










-
作者:Yunpeng Gao, Chenhui Li, Zhongrui You, Junli Liu, Zhen Li, Pengan CHEN, Qizhi Chen, Zhonghan TangLiansheng Wang, Penghui Yang, Yiwen Tang, Yuhang Tang, Shuai Liang, Songyi Zhu, Ziqin Xiong, Yifei Su, Xinyi Ye, Jianan Li, Yan Ding, Dong Wang, Zhigang Wang, Bin Zhao, Xuelong Li
-
单位:上海人工智能实验室,西北工业大学,北京邮电大学,上海交通大学,香港大学,浙江大学,中国科学技术大学,华东理工大学,复旦大学,中国科学院自动化研究所,TeleAI
-
论文标题:OpenFly: A Versatile Toolchain and Large-scale Benchmark for Aerial Vision-Language Navigation
-
论文链接:https://arxiv.org/pdf/2502.18041
-
项目主页:https://shailab-ipec.github.io/openfly/
主要贡献
-
论文开发了自动化工具链OpenFly,用于生成空中视觉语言导航的数据,集成了多种渲染引擎,能够高效地生成多样化和高质量的数据。
-
构建了包含10万个轨迹的大规模空中视觉语言导航数据集,覆盖了18个不同的场景,提供了丰富的环境多样性。
-
提出了基于关键帧感知的空中视觉语言导航模型OpenFly-Agent,能够有效地处理视觉冗余并提高导航性能。
-
通过广泛的实验,验证了所提方法和数据集的有效性,并建立了空中视觉语言导航任务的基准,展示了其在多个任务上的优越性能。

研究背景
研究问题
室内视觉语言导航(VLN)已经被广泛研究,而室外空中VLN仍然是一个未被充分探索的领域。
主要原因在于室外空中视野覆盖范围广,数据收集更具挑战性,导致缺乏基准数据集。
因此,论文主要解决的问题是如何在室外空中环境中进行VLN。
研究难点
该问题的研究难点包括:
-
数据多样性不足、数据收集效率低、数据规模小;
-
现有的方法依赖于AirSim和Unreal Engine(UE),限制了数据的多样性;
-
数据收集过程依赖飞行员操作无人机并在模拟器中进行手动标注,效率低下且难以扩展;
-
当前的数据集规模较小,仅有约10k条轨迹,远不及其他领域的数据集。
相关工作
-
模拟器用于具身AI:
-
介绍了多种用于具身AI研究的模拟器,如MuJoCo、Habitat、PyBullet、Matterport3D、OpenAI Gym和Isaac Gym。
-
这些模拟器主要用于室内机器人操作和导航,而不适合空中视觉语言导航(VLN)任务。
-
Gazebo和AirSim是常用的无人机模拟器,但存在兼容性和维护问题。
-
-
视觉语言导航数据集:
-
回顾了多个VLN数据集,包括R2R、RxR、TouchDown、REVERIE、CVDN等,这些数据集主要用于室内或地面导航。
-
最近的研究开始关注空中VLN,如ANDH和CityNav,它们分别使用鸟瞰图像和地理信息来辅助导航。
-
-
视觉语言导航方法:
-
讨论了VLN方法的进展,包括基于图的方法和LLM驱动的方法。
-
这些方法在连续环境中进行导航时面临挑战,特别是在空中VLN任务中,研究者提出了前瞻性引导和空间推理技术来应对这些问题。
-
OPENFLY数据生成平台
该平台通过集成多个模拟器和设计工具链来实现自动化的数据生成。
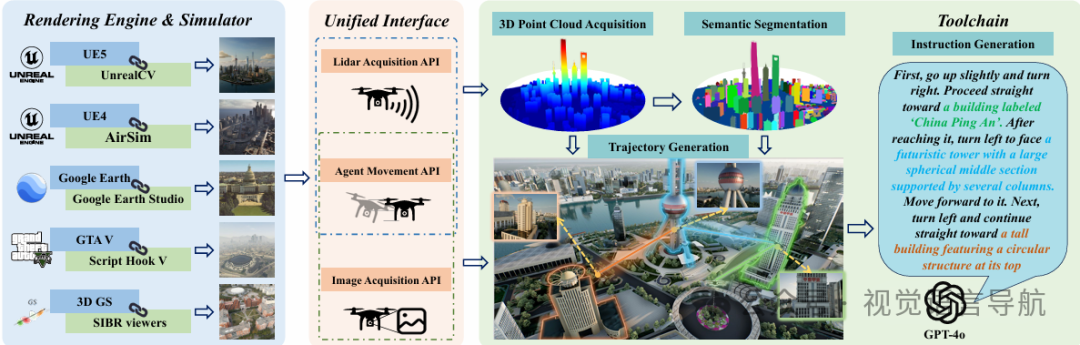
模拟器和数据资源
为了收集高质量和现实的模拟数据,平台从多个渲染引擎和模拟器中获取数据。具体包括:
-
Unreal Engine + AirSim/UnrealCV:
-
Unreal Engine(UE)提供高度真实的交互式虚拟环境。
-
平台使用UE5和UE4中的多个场景,涵盖多种城市景观和建筑风格。
-
AirSim是一个开源的无人机模拟器,通过UnrealCV插件与UE4集成,用于从无人机视角获取图像数据。
-
-
GTA V + Script Hook V:
-
GTA V是一个开放世界的游戏,提供高度真实和动态的虚拟环境。
-
通过Script Hook V库,平台能够控制虚拟代理以收集所需的数据。
-
-
Google Earth:
-
Google Earth软件结合卫星图像、航空照片和GIS数据,提供四个城市场景。
-
Google Earth Studio用于创建自定义视频,自动绘制飞行轨迹。
-
-
3D Gaussian Splatting:
-
3D GS是一种高度真实的重建方法,适用于渲染大规模区域。
-
平台使用该方法重建五个大学校园的场景,并通过SIBR viewers进行可视化。
-

自动数据收集工具链
为了实现自动化数据生成,平台设计了三个统一的接口和一个工具链,包括:
-
统一接口:
-
Agent Movement Interface:设计了一个坐标转换模块,统一所有模拟器的坐标系统。
-
Lidar Data Acquisition Interface:集成不同的点云数据获取方法,确保数据对齐。
-
Image Acquisition Interface:整合HTTP RESTful和TCP/IP协议,允许从任意位置获取图像数据。
-
-
3D点云获取:提供两种方法来重建整个场景的点云地图,包括栅格化采样重建和基于图像的稀疏重建。
-
场景语义分割:对四种类型的模拟场景进行语义分割,使用3D场景理解、点云投影和轮廓提取等方法。
-
自动轨迹生成:利用点云图和分割工具生成无碰撞的轨迹,采用A*路径搜索算法和基于网格的路径搜索方法。
-
自动指令生成:提出了一种基于大模型(VLM)的高度自动化的语言指令生成方法,减少手动标注的成本并提高数据集的可扩展性。
质量控制
平台还包括数据过滤和指令优化步骤,以确保数据质量和一致性:
-
数据过滤:移除损坏或低质量的图像,排除无人机穿过树木模型的轨迹,以及去除过短或过长的轨迹。
-
指令优化:使用NLTK库简化指令,检测并合并相似描述,减少冗余信息。
数据集分析
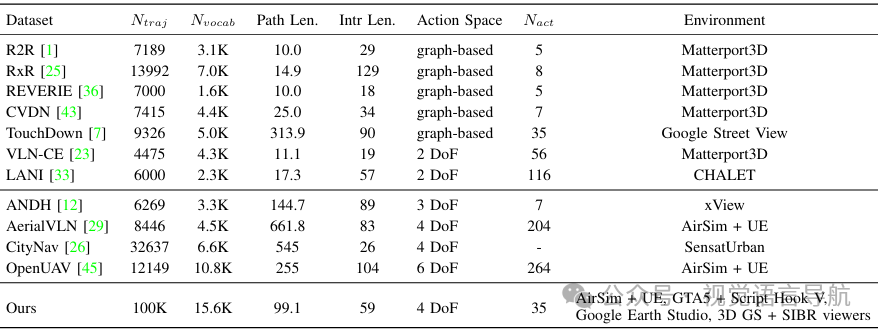
概述
OpenFly数据集通过工具链收集了10万个轨迹,每个轨迹都配有相应的图像序列和语言指令。数据生成过程中设定了最小运动步长为3米,以产生更细粒度的轨迹。数据集的特点包括:
-
轨迹数量:显著多于现有的VLN数据集。
-
词汇量:拥有更大的词汇量,提供了更丰富的指令描述。
-
环境多样性:涵盖了多种不同的场景和环境。
-
轨迹长度和指令长度:平均轨迹长度和指令长度相对较短,旨在符合人类用户的实际使用习惯。
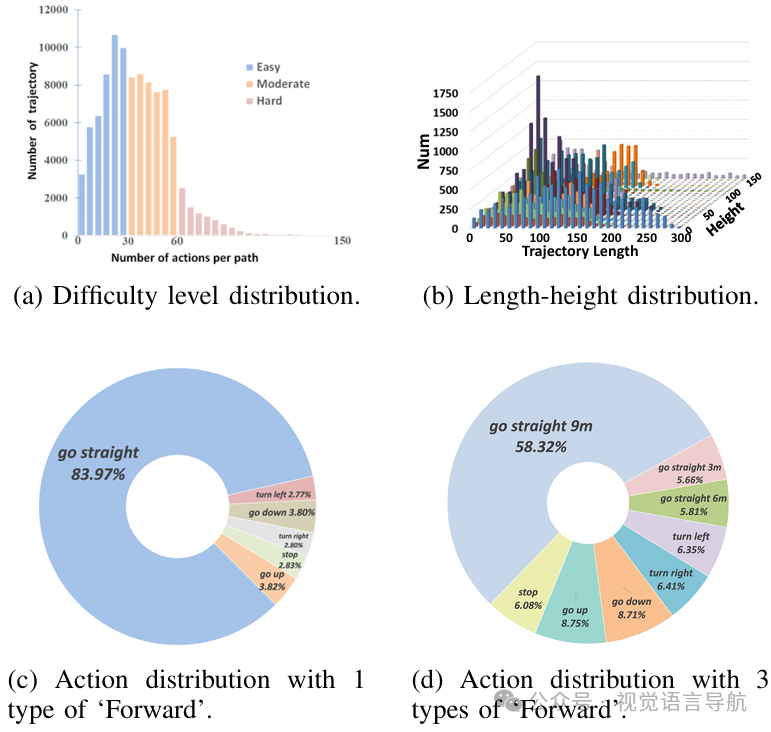
轨迹分析
除了丰富的场景多样性,数据集还努力在轨迹的难度级别、长度和高度上实现多样化:
-
难度级别:根据轨迹中的动作数量将轨迹分类为“简单”、“中等”和“困难”。例如,少于30个动作的轨迹被归类为“简单”。
-
轨迹长度和高度:轨迹长度范围从0到300米,飞行高度从0到150米不等。这种广泛的分布有助于训练模型应对不同复杂度的任务。
-
动作分布:在大型户外场景中,前进动作的比例自然较高。为了缓解模型对主导动作的过度拟合,将“前进”动作分为三种粒度(3米、6米和9米),并在轨迹中合并连续的“前进”动作。
OPENFLY-AGENT
介绍了OpenFly-Agent的设计、架构及其在视觉语言导航(VLN)任务中的应用。
数据集划分
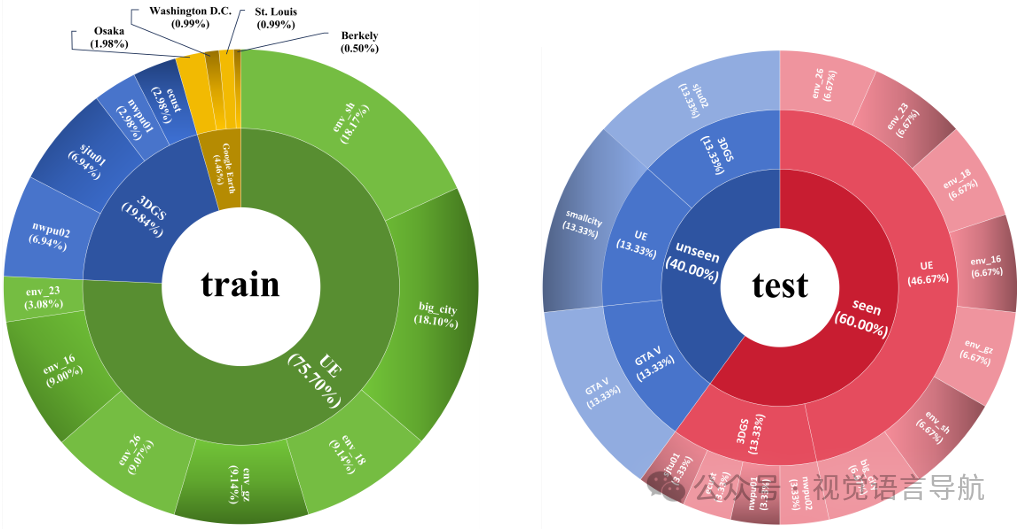
数据集被划分为三个部分,以便在不同的数据子集上评估模型的性能:
-
训练集(Train):
-
主要用于模型的训练。训练集包含来自多个场景的轨迹,其中大部分来自Unreal Engine,因为它提供了最多的场景。
-
具体的轨迹数量根据场景的面积进行采样,以确保数据集的平衡性。
-
-
测试可见集(Test-seen):
-
用于评估模型在已知场景中的表现。测试可见集包含从训练集中未使用的场景中均匀采样的轨迹。
-
这样可以确保模型在未见过的场景中进行测试时,仍能表现出色。
-
-
测试不可见集(Test-unseen):
-
用于评估模型的泛化能力。测试不可见集包含从未在训练集中出现过的场景中的轨迹。
-
这有助于验证模型在新场景中的适应性和鲁棒性。
-
问题定义
-
在视觉语言导航任务中,无人机的初始位置和姿态被随机设定在一个3D环境中。
-
无人机通过其自带的摄像头感知周围环境,并根据自然语言指令进行导航。
-
任务的目标是预测下一个导航动作,这些动作可以是前进、转向、上升、下降或停止。
模型架构
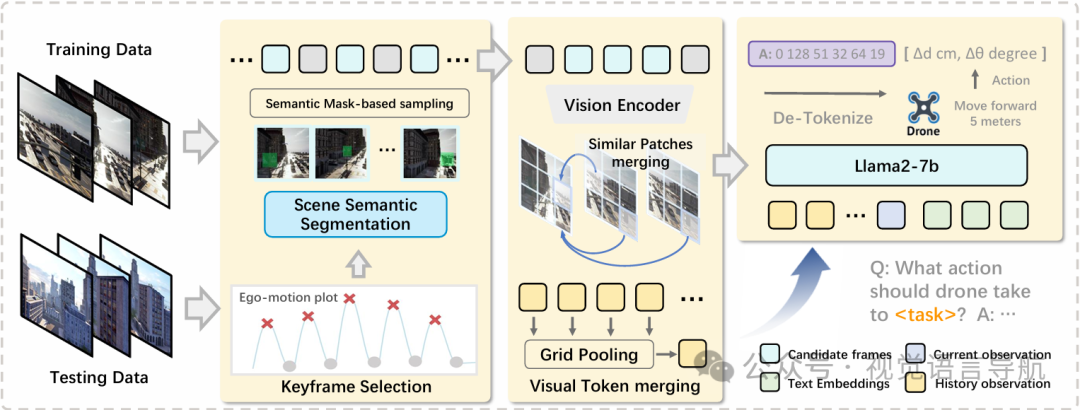
OpenFly-Agent基于OpenVLA模型进行扩展和改进,采用了端到端的架构。主要特点包括:
-
关键帧选择:
-
为了减少视觉冗余并保持关键信息,模型采用关键帧选择策略。
-
通过检测无人机的运动变化点来识别关键帧,确保包含关键地标的信息。
-
具体来说,模型通过绘制无人机的轨迹曲线,并在波峰附近选择帧作为候选关键帧。
-
然后,使用场景分割图来检测关键地标,确保选定的帧包含重要的导航信息。
-
-
视觉token合并:
-
为了减少计算负担,模型采用视觉token合并策略。
-
通过计算参考图像和后续图像之间的相似性,合并相似的视觉token。
-
具体来说,模型在每个关键帧集合中选择一个参考帧,并计算其与后续帧之间的余弦相似性。
-
相似的视觉token通过平均处理进行合并,以减少冗余信息。
-
-
动作预测:
-
模型定义了六种无人机动作:前进、左转、右转、上升、下降和停止。
-
每种动作被离散化为多个区间,模型输出映射到每个动作类型的区间,以预测飞行动作。
-
具体来说,“前进”动作有三个不同的单位(3米、6米和9米),而“左转”和“右转”的单位是30度,“上升”和“下降”的单位是3米。
-
实验与分析
实现和训练细节
-
模型组成:
-
OpenFly-Agent由Dino-SigCLIP(224 x 224像素)作为视觉编码器和预训练的Llama-2(7B)作为语言模型组成。
-
视觉token通过投影层与文本嵌入对齐后输入到Llama-2模型中。
-
-
视觉token处理:
-
当前帧保留256个视觉token,所有历史关键帧压缩为一个token。
-
历史记忆库的容量设置为2。
-
-
动作预测:使用词汇表中最后256个特殊token表示动作,每个动作类型被离散化为多个区间,用于预测。
评估指标
-
导航误差(NE):测量无人机最终停止点与目标位置之间的平均偏差。
-
成功率(SR):成功任务的比率,定义为无人机在目标20米范围内停止的任务比例。
-
Oracle成功率(OSR):如果轨迹上的任何点在目标20米范围内,则认为任务成功。
-
路径加权成功率(SPL):根据实际执行路径长度与目标路径长度的比例加权的成功率。
结果分析

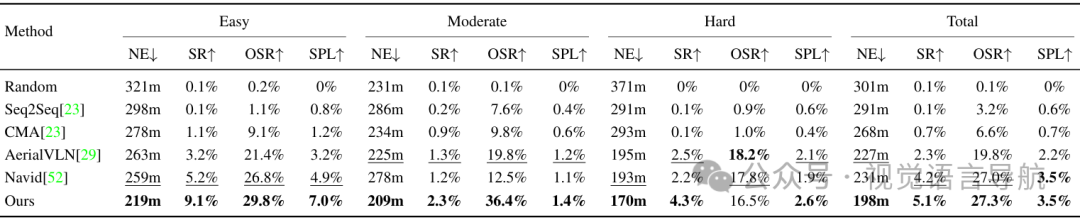
-
定量结果:在测试可见集和测试不可见集上测试OpenFly-Agent,并区分容易、中等和困难的样本。与其他VLN方法相比,OpenFly-Agent在所有难度级别上均表现出最佳性能。
-
Test-seen:OpenFly-Agent在各个难度级别上均优于其他方法,显示出强大的视觉语言导航能力。
-
Test-unseen:尽管所有方法的性能都有所下降,但OpenFly-Agent仍然表现出一定的泛化能力。
-
-
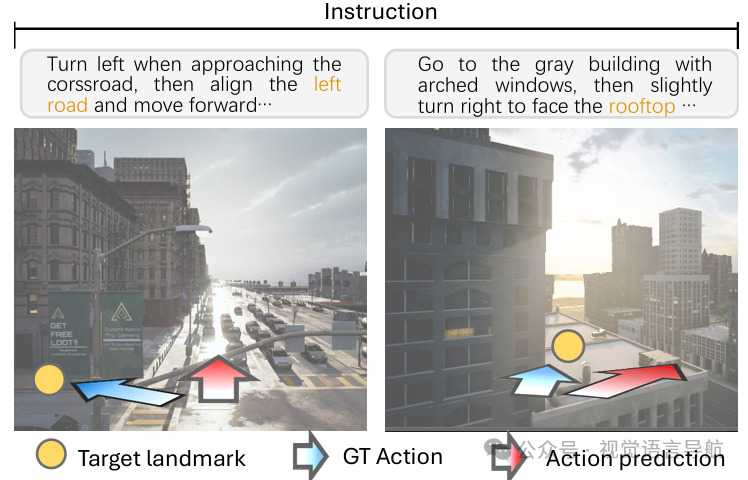
定性结果:
-
展示了OpenFly-Agent的成功导航案例和失败案例。
-
成功案例中,模型能够根据指令成功导航至目的地;
-
失败案例中,模型可能未能正确识别地标或输出错误的动作。
-
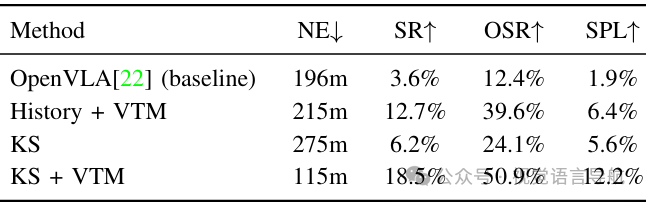
消融研究
-
评估关键帧选择和视觉token合并对模型性能的影响。
-
结果表明,关键帧选择和视觉token合并策略显著提高了模型的成功率。
总结
-
论文提出了OpenFly平台,用于大规模数据收集和室外空中VLN任务。
-
OpenFly集成了多种渲染引擎,生成了多样且高质量的数据。
-
提出的OpenFly-Agent模型在多个评估指标上表现优异,验证了其有效性,并为未来的空中导航研究提供了一个全面的基准。


















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









