








- 作者:Xiangyu Shi, Zerui Li, Wenqi Lyu, Jiatong Xia, Feras Dayoub, Yanyuan Qiao, Qi Wu
- 单位:阿德莱德大学机器学习研究所
- 论文标题:SmartWay: Enhanced Waypoint Prediction and Backtracking for Zero-Shot Vision-and-Language Navigation
- 论文链接:https://arxiv.org/pdf/2503.10069
主要贡献
- 导航点预测增强:通过使用DINOv2视觉编码模块和掩码交叉注意力机制,改进了导航点的预测质量,确保导航点在可通行区域内。
- 多模态大模型(MLLM)的应用:首次在连续环境中使用MLLM进行导航,结合历史轨迹信息和自适应路径规划,提升导航的鲁棒性。
- 回溯机制:引入回溯机制,允许在导航过程中纠正错误,减少错误传播,提高导航的成功率。
- 实验验证:在模拟和现实环境中验证了方法的有效性,展示了其在零样本设置下的优越性能,优于其他方法。
研究背景
研究问题
论文主要解决的问题是视觉语言导航(VLN)在连续环境中,智能体需要解释自然语言指令并在无约束的3D空间中进行导航的问题。
研究难点
该问题的研究难点包括:
- 现有的VLN-CE框架依赖于两阶段方法,即导航点预测模块和导航模块,
- 但当前的航点预测模块在空间感知方面存在不足,而导航模块则缺乏历史推理和回溯能力,限制了适应性。
相关工作
- 视觉语言导航(VLN):
- VLN任务涉及让智能体根据人类指令在未见过的环境中导航。大多数现有研究在离散环境中进行,使用预定义的导航图。
- Krantz等人引入了连续环境(CE)的基准,以更好地模拟现实世界的导航场景。
- 导航点预测:
- 在VLN-CE中,智能体需要在连续的三维空间中导航,而不是依赖于固定的导航图。
- 研究者们提出了多种导航点预测模型,如Hong等人的方法,但这些方法在生成与目标子任务对齐的导航点时存在挑战。
- 基础模型作为具身智能体:
- 近年来,研究者们开始将基础模型应用于具身任务,如VLN。
- MapGPT和DiscussNav等方法利用大语言模型(LLMs)的泛化能力来增强导航性能,但通常依赖于文本输入,缺乏直接处理视觉信息的能力。
- 历史和回溯机制:
- 在学习型VLN-CE方法中,历史和回溯机制被证明是有效的。
- 然而,当使用LLMs作为导航智能体时,这些机制的重要性尚未得到充分研究。论文旨在通过引入历史感知和回溯功能来提升VLN的性能。
基础介绍
问题定义
- 在连续环境中的视觉语言导航(VLN-CE)中,自主智能体必须在连续的三维空间 E E E 中根据语言指令进行导航。
- 智能体的位置在时间 t t t 时记为 x t = ( x t , y t , z t ) ∈ E x_t = (x_t, y_t, z_t) \in E xt=(xt,yt,zt)∈E。智能体接收在均匀间隔的视点(例如, 0 ∘ , 3 0 ∘ , … , 33 0 ∘ 0^\circ, 30^\circ, \ldots, 330^\circ 0∘,30∘,…,330∘)收集的全景RGB-D观测值,生成12张RGB图像和12张深度图像 I = { ( I i r g b , I i depth ) ∣ i = 1 , … , 12 } I = \{(I_i^{rgb}, I_i^{\text{depth}}) \mid i=1, \ldots, 12\} I={(Iirgb,Iidepth)∣i=1,…,12},其中 I i r g b ∈ R H × W × 3 I_i^{rgb} \in R^{H \times W \times 3} Iirgb∈RH×W×3 和 I i depth ∈ R H × W I_i^{\text{depth}} \in R^{H \times W} Iidepth∈RH×W。
- 智能体接收指令 L = { l 1 , l 2 , … , l n } L = \{l_1, l_2, \ldots, l_n\} L={l1,l2,…,ln},其中每个 l i l_i li 是指令的一个词(token)。
- 指令指定如何从起始位置 x start x_{\text{start}} xstart 到达目标位置 x goal x_{\text{goal}} xgoal。导航过程通过执行离散的低级动作来展开,这些动作决定移动的方向和距离。
- 智能体的目标是根据指令最小化导航误差并到达连续三维环境中的指定目标。
导航点预测
-
导航点预测模块通过在当前观测的基础上生成候选导航点来弥合离散环境和连续空间之间的差距。
-
对于开放环境中的任何给定位置,智能体捕获RGB和深度全景图,每个全景图由12张单视图图像组成,每张图像间隔30度。
-
这些图像被编码成特征序列,分别表示为 F r g b = { f i r g b ∣ i = 1 , … , 12 } F^{rgb} = \{f_i^{rgb} \mid i=1, \ldots, 12\} Frgb={firgb∣i=1,…,12} 和 F depth = { f i depth ∣ i = 1 , … , 12 } F^{\text{depth}} = \{f_i^{\text{depth}} \mid i=1, \ldots, 12\} Fdepth={fidepth∣i=1,…,12}。
- RGB图像编码:使用在ImageNet上预训练的ResNet-50对RGB图像进行编码:
f i r g b = E resnet ( I i r g b ) f_i^{rgb} = E^{\text{resnet}}(I_i^{rgb}) firgb=Eresnet(Iirgb) - 深度图像编码:使用另一个在点目标导航上预训练的ResNet-50对深度图像进行编码:
f i depth = E depth ( I i depth ) f_i^{\text{depth}} = E^{\text{depth}}(I_i^{\text{depth}}) fidepth=Edepth(Iidepth)
- RGB图像编码:使用在ImageNet上预训练的ResNet-50对RGB图像进行编码:
-
每个特征对 ( f i r g b , f i depth ) (f_i^{rgb}, f_i^{\text{depth}}) (firgb,fidepth) 通过非线性层 W m W^m Wm 进行融合,以获得组合特征 f i r g b d f_i^{rgb\text{d}} firgbd。一个两层的Transformer处理12个融合特征,分析空间关系并预测相邻导航点。
-
为了保持空间一致性,每个 f i r g b d f_i^{rgb\text{d}} firgbd 的自注意力限制在其相邻特征上。Transformer输出 f ~ i r g b d \tilde{f}_i^{rgb\text{d}} f~irgbd,编码以图像 i i i 为中心的空间关系。
-
分类器生成一个 120 × 12 120 \times 12 120×12 的热图 P P P,其中角度间隔为每3度,距离范围从0.25米到3.00米,步长为0.25米。然后应用非极大值抑制(NMS)提取前K个可通行导航点,K设置为5。
-
路径预测模块使用回归损失来训练,最小化预测热图 P P P 和地面真实热图 P ∗ P^* P∗ 之间的差异。具体来说,使用均方误差(MSE)损失: L vis = MSE ( P , P ∗ ) L_{\text{vis}} = \operatorname{MSE}(P, P^*) Lvis=MSE(P,P∗)
其中 P P P 是预测的导航点概率分布, P ∗ P^* P∗ 是地面真实热图。这个损失确保模型准确预测可通行导航点的空间分布。
方法
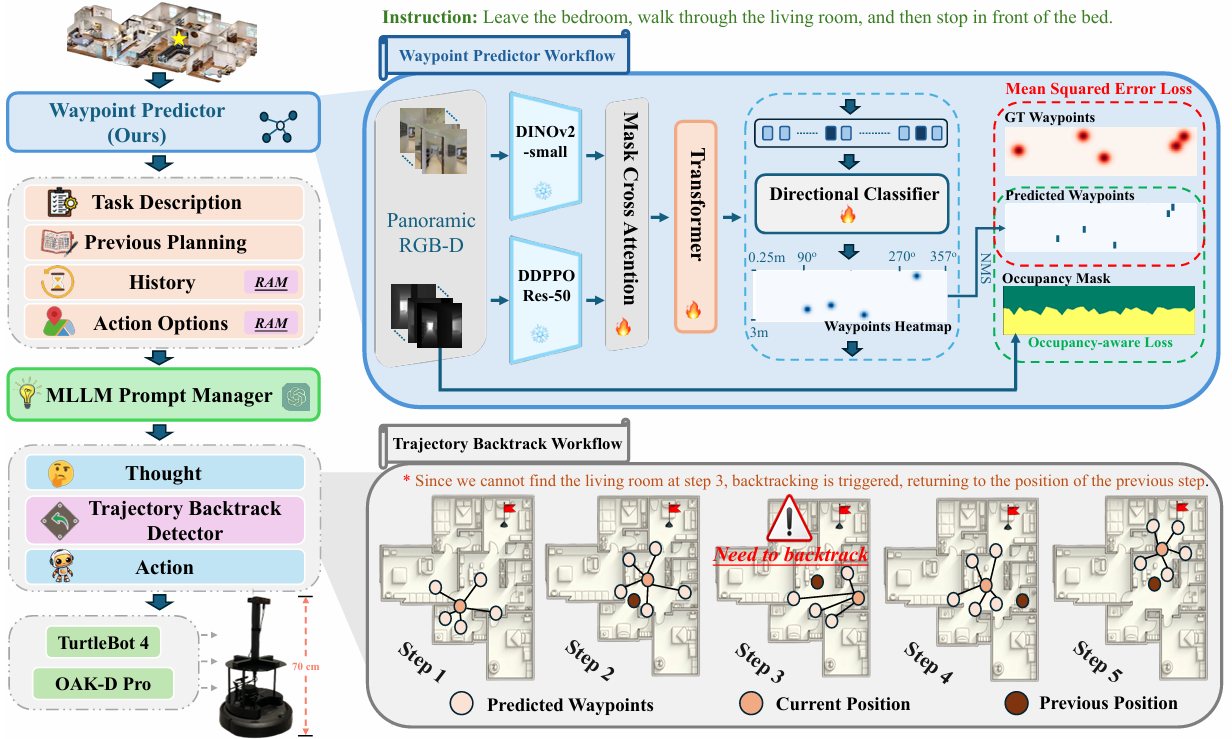
占用感知的路径预测模块
-
视觉编码模块升级
- 替换ResNet-50为DINOv2:原始路径预测模块使用基于ImageNet预训练的ResNet-50来提取RGB图像的特征。
- 为了提高视觉表示的质量,论文中提出将ResNet-50替换为DINOv2,一个自监督的视觉Transformer,能够提供更丰富和更具迁移性的特征。
- 深度编码模块保持不变:深度图像的编码模块保持不变,继续使用预训练用于点目标导航的ResNet-50。
-
基于掩码交叉注意力的特征融合
- 改进特征交互:在基线方法中,RGB和深度特征通过非线性层简单融合。这种简单的融合未能充分利用RGB和深度模态的互补性。
- 交叉注意力机制:为了改善特征交互并增强空间意识,论文中提出使用掩码交叉注意力机制。在该机制中,RGB特征作为查询,深度特征作为键和值,使RGB能够关注关键的深度区域。
- 表示更新:
f i r g b = CrossAttention ( f i r g b , f i d e p t h , mask ) f_i^{rgb} = \text{CrossAttention}(f_i^{rgb}, f_i^{depth}, \text{mask}) firgb=CrossAttention(firgb,fidepth,mask)
其中,掩码用于保持空间一致性,确保每个特征仅与其相邻特征交互。
-
占用感知损失
- 环境约束:现有的路径预测模块仅依赖地面真实热图进行训练,忽略了环境约束,可能导致预测的导航点位于障碍物区域。
- 引入占用感知损失:论文引入了占用感知损失,结合深度信息来确保预测的导航点位于可通行区域。通过计算每个间隔的最短相对距离,并将其映射到分类器的热图中,生成占用掩码。
- 计算3D坐标:
C n = I depth ( n , m ) ⋅ d n , m C_n = I^{\text{depth}}(n, m) \cdot d_{n, m} Cn=Idepth(n,m)⋅dn,m
其中, d n , m d_{n, m} dn,m 表示像素 ( n , m ) (n, m) (n,m) 的光线方向。 - 水平面距离:
D n = x n 2 + z n 2 D_n = \sqrt{x_n^2 + z_n^2} Dn=xn2+zn2 - 构建占用掩码:
M k , j = { 1 , if d j ≤ D k 0 , otherwise M_{k, j} = \begin{cases} 1, & \text{if } d_j \leq D_k \\ 0, & \text{otherwise} \end{cases} Mk,j={1,0,if dj≤Dkotherwise - 二进制交叉熵损失:
L occ = BCE ( P , M ) L_{\text{occ}} = \text{BCE}(P, M) Locc=BCE(P,M) - 总目标函数:
L total = L vis + λ occ ∗ L occ L_{\text{total}} = L_{\text{vis}} + \lambda_{\text{occ}} * L_{\text{occ}} Ltotal=Lvis+λocc∗Locc
其中, λ occ \lambda_{\text{occ}} λocc 控制占用约束的相对重要性。
基于MLLM的导航模块

-
历史感知的单专家提示系统
- 单专家范式:论文中提出的方法基于MapGPT的单专家范式,统一处理文本和视觉输入,避免了多个专家模块带来的信息丢失和冗余计算。
- 扩展动作空间:通过引入多尺度转向提示和细粒度物体识别,增强了智能体在连续环境中的适应能力。
- 物体检测:
s i = RAM ( I r g b ) , i = 1 , 2 , … , n s_i = \operatorname{RAM}(I_{rgb}), \quad i=1,2,\ldots,n si=RAM(Irgb),i=1,2,…,n - 扩展历史记录:通过扩展历史信息,包括来自先前动作空间的场景描述,增强了导航的历史感知能力。
-
自适应路径规划与回溯
- 多步规划:利用MLLM的多步规划能力,模型可以生成、更新和优化多步计划,并引入回溯机制以纠正错误并避免冗余探索。
- 回溯策略:在每个步骤中,模型生成一个简短的“思考”来描述后续的移动,并在必要时通过额外的动作选项返回到之前的位置进行修正。
实验
实验设置
模拟环境
- 实现平台:实验在Habitat模拟器上实现。Habitat是一个用于研究机器人和AI在虚拟环境中的行为的平台。
- 数据集:在MP3D的val-unseen集上评估路径预测模块,并遵循Hong等人在CVPR 2022年提出的评估协议。
- 导航模块评估:通过与几种基于学习的VLN方法和LLM/MLLM方法进行基准测试,评估导航模块的性能。使用Open-Nav在ICRA 2025年提出的评估框架进行100个回合的基准测试。
- 路径预测模块训练:使用AdamW优化器,批量大小为128,学习率为 1 0 − 6 10^{-6} 10−6,训练300个epoch。 λ occ \lambda_{\text{occ}} λocc 设置为0.5。
- MLLM导航模块部署:使用gpt-4o-2024-08-06 API进行零样本推理。
现实环境
- 硬件平台:在配备OAK-D Pro摄像头的Turtlebot 4移动机器人上进行实验。摄像头安装在70厘米的高度。
- 实验设计:方法依赖于相机进行感知,不使用外部映射模块。在语义丰富的室内环境中进行评估。
- 实时执行:
- 所有方法在配备NVIDIA RTX 3080 Mobile GPU(16 GB VRAM)的笔记本电脑上实时执行。
- 机器人在每个导航步骤中根据预测的角度和方向前进。
- 评估指标:
- 定义了25个不同的导航指令,包括开放词汇的地标、细粒度地标细节和涉及多个房间转换的场景。
- 使用DiscussNav在ICRA 2024年提出的实验协议进行评估。
结果
模拟环境结果
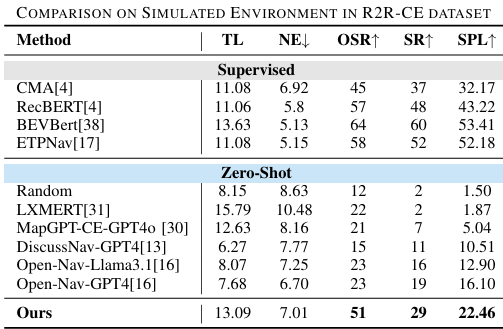
- 在R2R-CE数据集上,展示了各种模型的综合性能比较。表格分为两部分:监督方法和零样本方法。
- 监督方法:受益于领域特定训练的监督方法在模拟环境中表现更好,成功率和路径效率更高。
- 零样本方法:在严格的零样本条件下,所提出的零样本方法在OSR(Oracle Success Rate)、SR(Success Rate)和SPL(Success Weighted by Path Length)方面优于其他零样本方法。
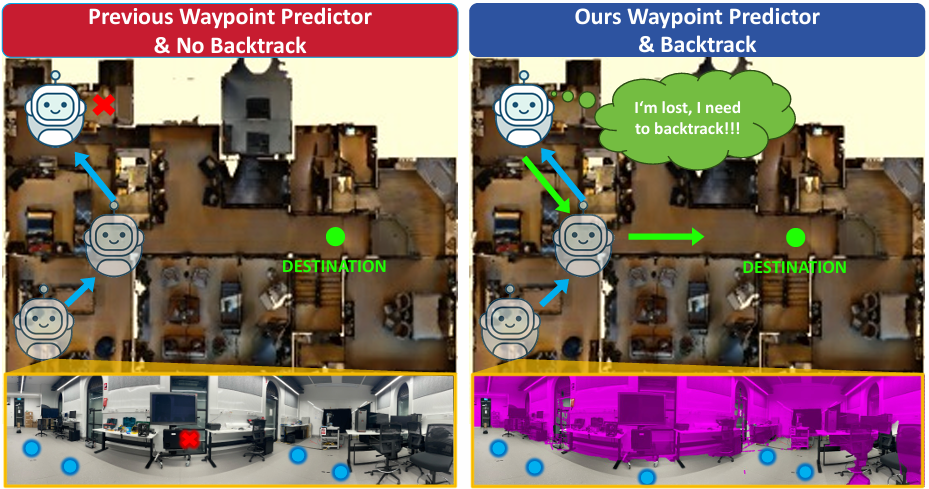
现实环境结果
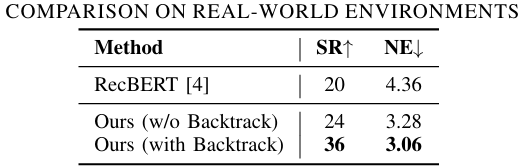
- 在现实环境中,选择RecBERT作为比较对象,因为它是现实任务中表现最好的监督训练方法。
- 性能提升:所提出的方法在没有回溯机制的情况下成功率高于RecBERT。启用回溯机制后,成功率进一步提高,导航误差降低。
- 回溯机制:回溯机制显著提高了成功率并减少了导航错误,表明其在复杂动态现实场景中纠正次优路径选择的能力。
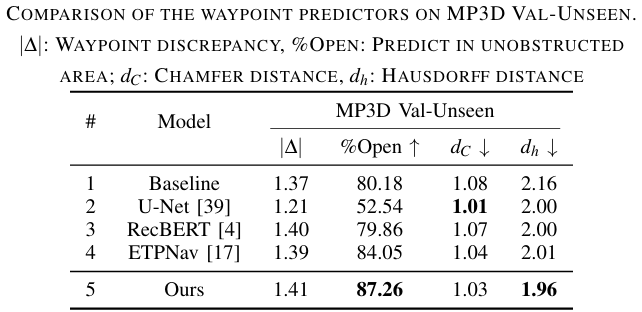
路径预测模块比较
- 在MP3D Val-Unseen数据集上,展示了不同路径预测模块的比较。
- 性能提升:所提出的方法在%Open(可通行区域预测比例)和 d h d_h dh(Hausdorff距离)方面表现最佳,表明其在不可阻挡区域的导航点预测和导航点对齐方面的优势。
消融研究
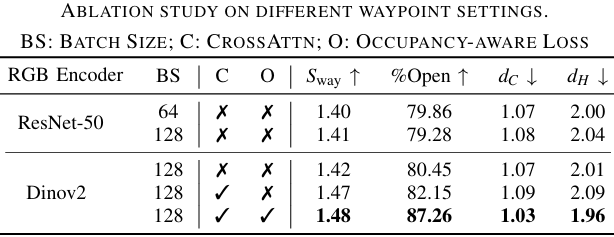
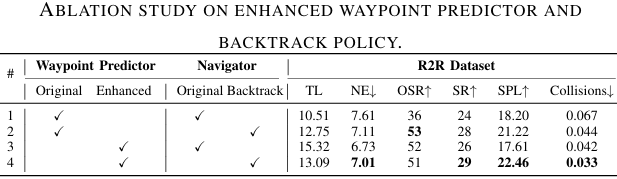
- 路径预测模块消融研究:评估不同组件对路径预测的影响。
- 导航模块消融研究:研究增强路径预测模块和回溯机制如何相互补充以提高导航性能。
总结
- 论文提出了一种零样本VLN-CE框架,通过增强的航点预测模块和基于MLLM的导航模块,显著提高了导航性能和鲁棒性。
- 实验结果表明,该方法在模拟和真实环境中均达到了最先进的性能,缩小了与全监督方法的性能差距。
- 未来的工作将扩展回溯机制以支持多步撤销操作,并通过引入视觉语言分割和场景感知提示来增强语义理解,以进一步纠正更深层次的导航错误并提高导航性能。


















 3183
3183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









