






上一篇我们将到我们将要求解目标函数:
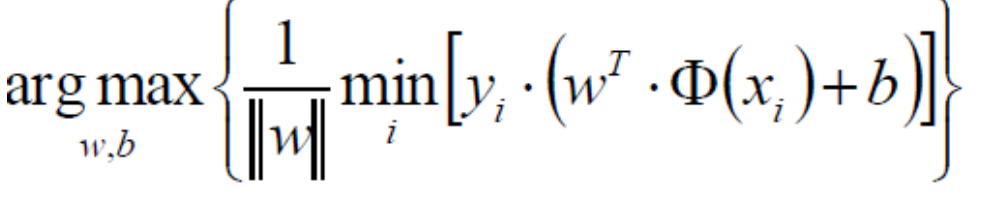
在这里我们对min后面的式子进行放缩。之前我们认为
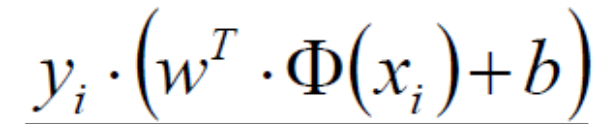
该式大于等于0
现在我们对该式进行放缩,我们知道当x>1时,2x>2。所以我们总有办法使
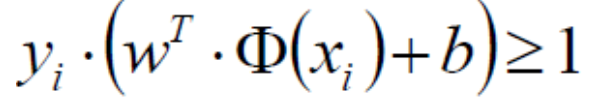
进行此放缩的目的是为了化简。当该式大于等于1时,它的最小值就是1。所以目标函数可以化简成
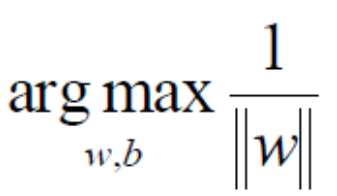
所以目标函数就变成了

当遇到求极大值问题时,我们将其转换成求极小值问题,所以我们只需要求w的极小值就可以。为了方便后续化简,我们将w变成w的平方,并乘以1/2,变成
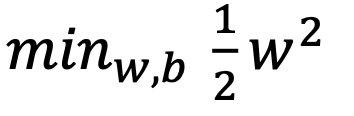
在求有约束条件的极小值问题时,我们一般都使用拉格朗日乘子法进行求解。
已知拉格朗日乘子法
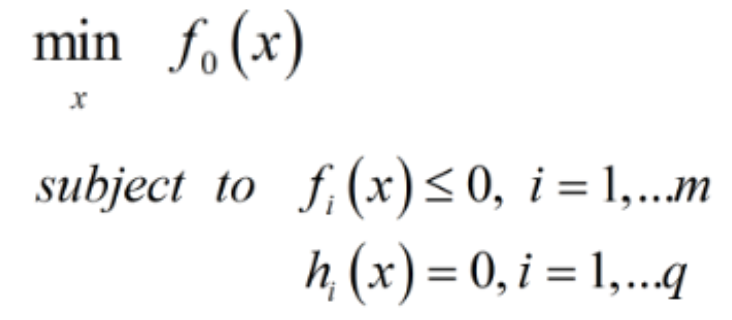
f0是求极小值的目标函数,fi和hi都是约束条件。由于约束条件需要小于等于0,所以我们在约束条件前面加上负号,所以拉格朗日方程变成:
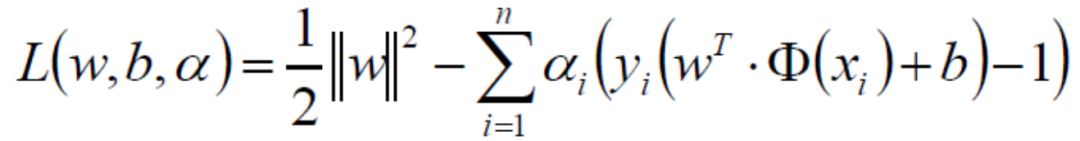
在这里我们介绍一个原理:KKT原理,也可以称之为拉格朗日对偶原则,就是对拉格朗日等式先求最大再求最小等价于对拉格朗日等式先求最小再求最大。
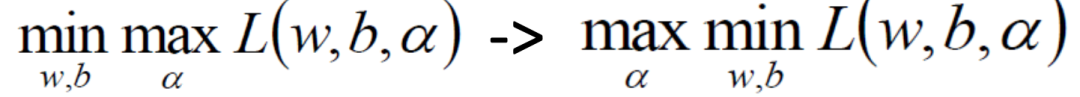
那么什么样的w和b能使得拉格朗日等式最小的,我们需要分别对w和b求偏导。
对w求偏导得:
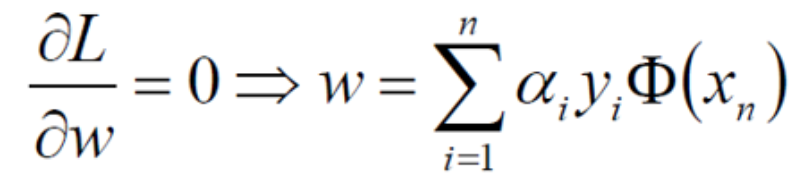
对b求偏导得到:
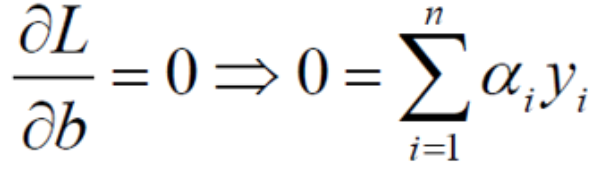
我们将w和b分别代入到原拉格朗日方程式中:
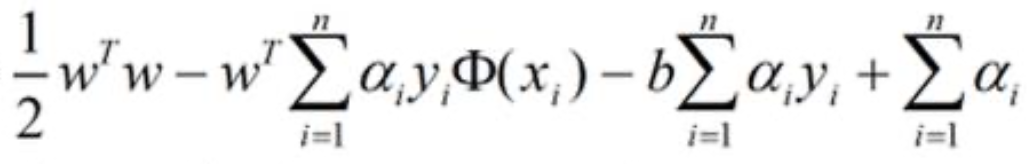
虽然求导没有得到关于b的等式,但是因为:
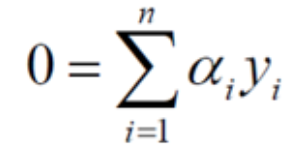
0乘以任何数都是0,所以我们仍然可以将b约掉。
等式变成:
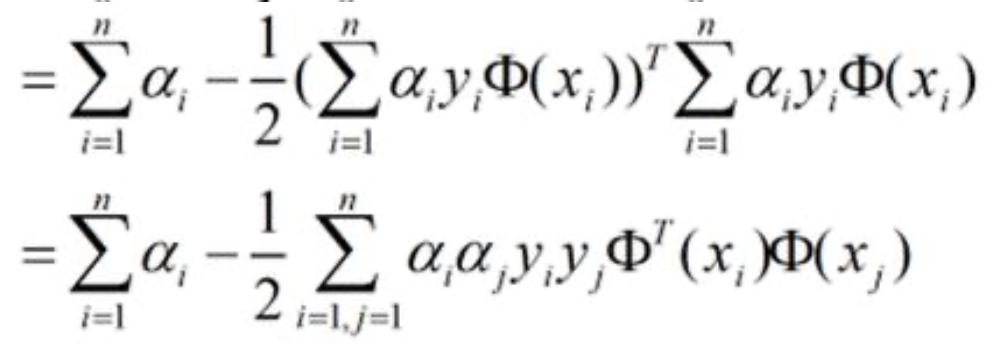
所以根据对偶原则,我们接下来需要求解什么样的阿尔法能使得拉格朗日等式最大。这里别忘了我们之前还有一个约束条件
我们可以看到,无论是约束条件还是化简后的等式,都只与阿尔法 x和y有关。所以我们将需要进行分类的已知数据点带入到
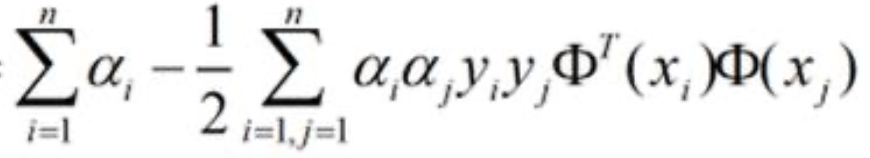
可以得到关于阿尔法的式子,然后在对此式子求偏导结合约束条件就可以求到阿尔法的值。
再将阿尔法的值带入到
就可以得到w的值,同样我们也可以得到b的值。
我们求到的阿尔法有可能为0,根据方程式
我们可以注意到,当阿尔法为0时,无论x和y的值为多少,与之相乘都是0,没有任何意义。由此我们得到一个定理,对超平面产生影响的只有阿尔法不为0的那些数据点,我们将这些数据点称为支持向量,只有这些数据点会对超平面产生影响,会影响w的取值。阿尔法为0的数据点对超平面不会产生任何印象!
接下来我们将会讲解支持向量机的另一个概念:软间隔和核函数。
敬请关注❤️
喜欢的话点个关注哦~ 会每天分享人工智能机器学习内容,回复关键字可获取相关算法数据及代码~
















 2834
2834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









