







手把手教你训练自己的YOLO V4数据集,超详细教程,附带训练数据集
整体训练来源与结果
啥都不说了,直接上论文跟代码链接
YOLO V4 论文链接:https://arxiv.org/abs/2004.10934
YOLO V4 开源代码:https://github.com/AlexeyAB/darknet
YOLOv4来了!速度和精度双提升!
与YOLOv3相比,新版本的AP和FPS(每秒帧率)分别提高了10%和12%。

可以明显看到,YOLO V4,不管是AP还是real-time,都有非常大的提升。
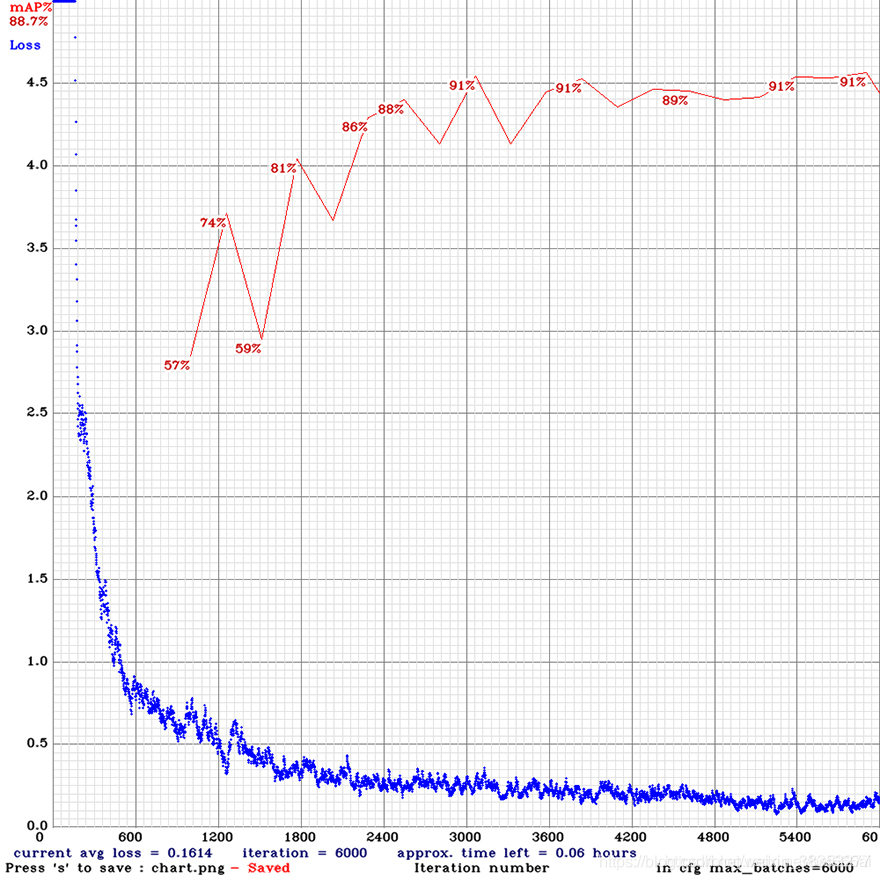
可以看到loss的下降还是收敛很快的。
本次训练系统环境
YOLO V4系列有linux版本和windows版本,由于windows 版本需要配置很多附加VS的插件,很明显linux版本更加简单,VS2017就十几个G,因此,笔者在Ubuntu的条件下训练,其他版本满足要求应该没啥问题,配置方法网上很多资源,这里不做介绍。
- 操作系统:ubuntu16.04
- CUDA版本:8.0
- cuDNN 版本:6.0
- opencv版本:3.4.9
- python版本:系统自带
- cmake版本:CMake >= 3.8
注*:windows中要求:CUDA > 10.0, cuDNN > 7.0, OpenCV > 2.4
整体数据处理流程
很多学者都是以coco, vol数据集为源头开始测试模型,因为如果直接用自己的数据集,就会有很多相关代码进行修改。本次测试直接借用coco数据集的类型。当我们做mask-rcnn时,我们用labelme来对图像进行标注,labelme使用教程和方法网上一大堆们这里不再讲解,标注完后,每一张图片对应一个json文件,将json文件分为两部分,一部分放到了train文件夹,一部分放到了val文件夹这两个文件同时放到IMGJSON(自己创建的文件)文件里,标注的图片放到自己创建的IMG文件里,图片为彩色 .jpg 格式。
IMGJSON文件和IMG文件同时放在yolo v4 根目录里面,即darknet-master/里面,整个文件的包含模式如下所示:
-darknet-master(根目录)
- IMG
- IMGJSON
- train
- val
下一步时数据处理,这个过程比较麻烦,我个人处理好的数据集已经上传,需要尝试的可自行下载
https://download.csdn.net/download/weixin_38353277/12373128
自己做数据集的流程如下:
首先,做的数据集时模拟coco数据集,因此要在根目录下创建三个文件夹,Annotations, ImageSets, JPEGImages。
其次,在根目录下创建transdata.py,将IMG和IMGJSON的数据集转到coco数据集模式,具体转换代码如下所示:
下面展示一些 内联代码片。
// An highlighted block
# -*- coding: utf-8 -*-
import shutil
import os
import json
import cv2
import io
headstr = """\
<annotation>
<folder>VOC2007</folder>
<filename>%06d.jpg</filename>
<source>
<database>My Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>NULL</flickrid>
</source>
<owner>
<flickrid>NULL</flickrid>
<name>company</name>
</owner>
<size>
<width>%d</width>
<height>%d</height>
<depth>%d</depth>
</size>
<segmented>0</segmented>
"""
objstr = """\
<object>
<name>%s</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>%d</xmin>
<ymin>%d</ymin>
<xmax>%d</xmax>
<ymax>%d</ymax>
</bndbox>
</object>
"""
tailstr = '''\
</annotation>
'''
def writexml(idx, head, bbxes, tail):
filename = ("Annotations/%06d.xml" % (idx))
f = open(filename, "w")
f.write(head)
for bbx in bbxes:
f.write(objstr % (bbx[0], bbx[1], bbx[2], bbx[3], bbx[4]))
f.write(tail)
f.close()
def clear_dir():
if shutil.os.path.exists(('Annotations')):
shutil.rmtree(('Annotations'))
if shutil.os.path.exists(('ImageSets')):
shutil.rmtree(('ImageSets'))
if shutil.os.path.exists(('JPEGImages')):
shutil.rmtree(('JPEGImages'))
shutil.os.mkdir(('Annotations'))
shutil.os.makedirs(('ImageSets/Main'))
shutil.os.mkdir(('JPEGImages'))
def excute_datasets(json_path, tr, idx):
json_path = os.path.join(json_path, tr)
json_file = os.listdir(json_path) # 读取所有json文件
savename = open(('ImageSets/Main/' + tr + '.txt'), 'a')
for file in json_file:
file_path = os.path.join(json_path, file) # 找到json文件路径
with io.open(file_path, 'r', encoding='utf-8') as f:
file_json = json.load(f)
imagename = file_json["imagePath"].split('/')[-1]
image_path = os.path.join('./IMG', imagename) # RGB彩色图像所在文件夹
image = cv2.imread(image_path)
if image is None: # 如果没有这种照片,检查图片路径
print("No image")
continue
label_shape_type = file_json['shapes'][0]['shape_type']
#print("save img!")
if label_shape_type == 'rectangle':
continue
head = headstr % (idx, image.shape[1], image.shape[0], image.shape[2])
shapes = file_json['shapes']
boxes = []
for i in range(len(shapes)):
classname = file_json['shapes'][i]['label'] # 类别
box = [classname, file_json['shapes'][i]['points'][0][0],
file_json['shapes'][i]['points'][0][1], file_json['shapes'][i]['points'][1][0],
file_json['shapes'][i]['points'][1][1]]
boxes.append(box)
writexml(idx, head, boxes, tailstr)
cv2.imwrite('JPEGImages/%06d.jpg' % (idx), image)
savename.write('%06d\n' % (idx))
idx += 1
savename.close()
return idx
if __name__ == '__main__':
clear_dir()
idx = 10000
idx = excute_datasets('./IMGJSON', 'train', idx) # IMGJSON文件的路径
idx = excute_datasets('./IMGJSON', 'val', idx)
print('Complete...')
运行之后在目录下生成如下几个文件:
Annotations文件夹中:如图所示
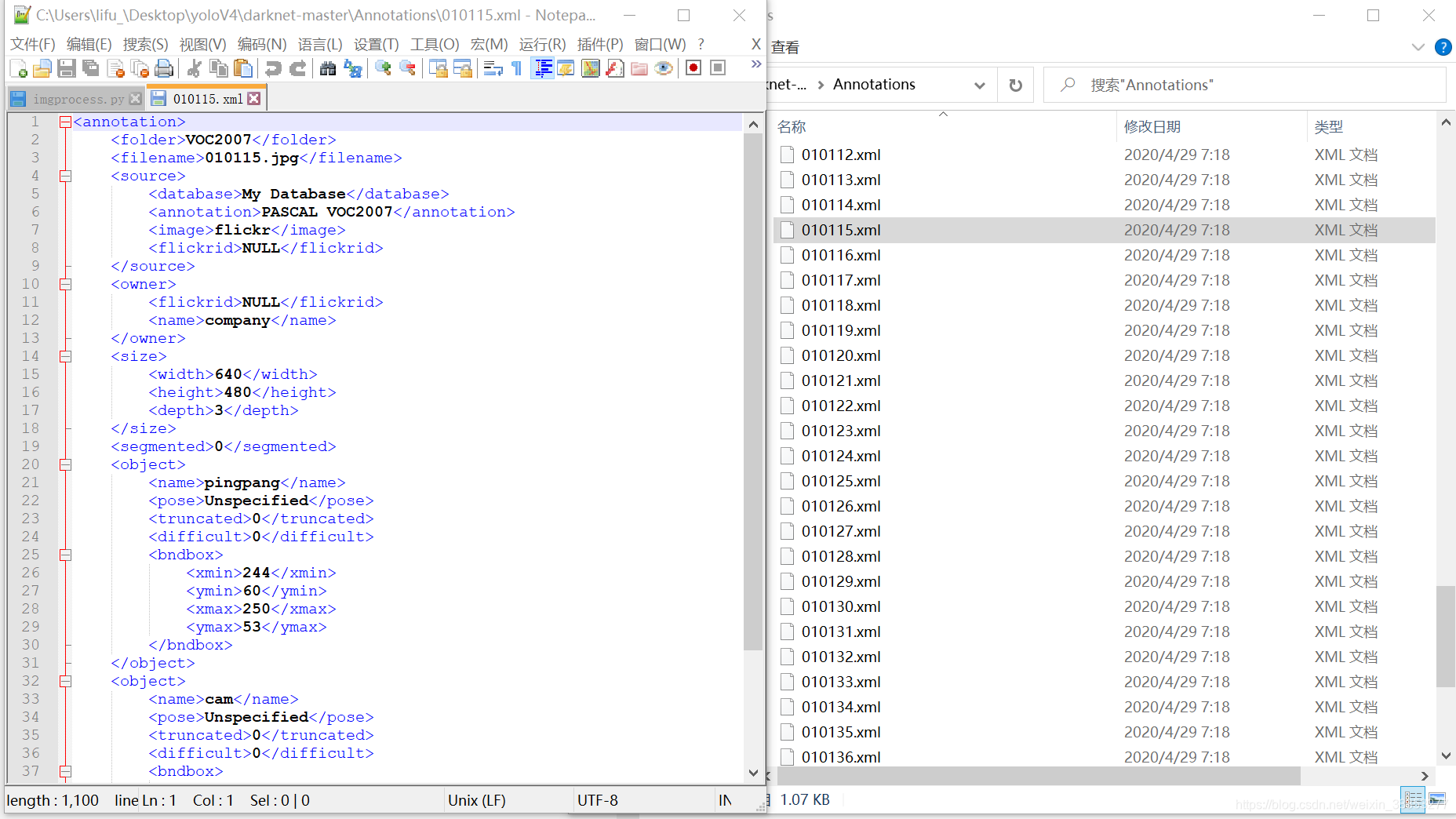
该文件中为标注数据的xml文件,距离内容如上图所示。
ImageSets/Main文件夹中如图所示
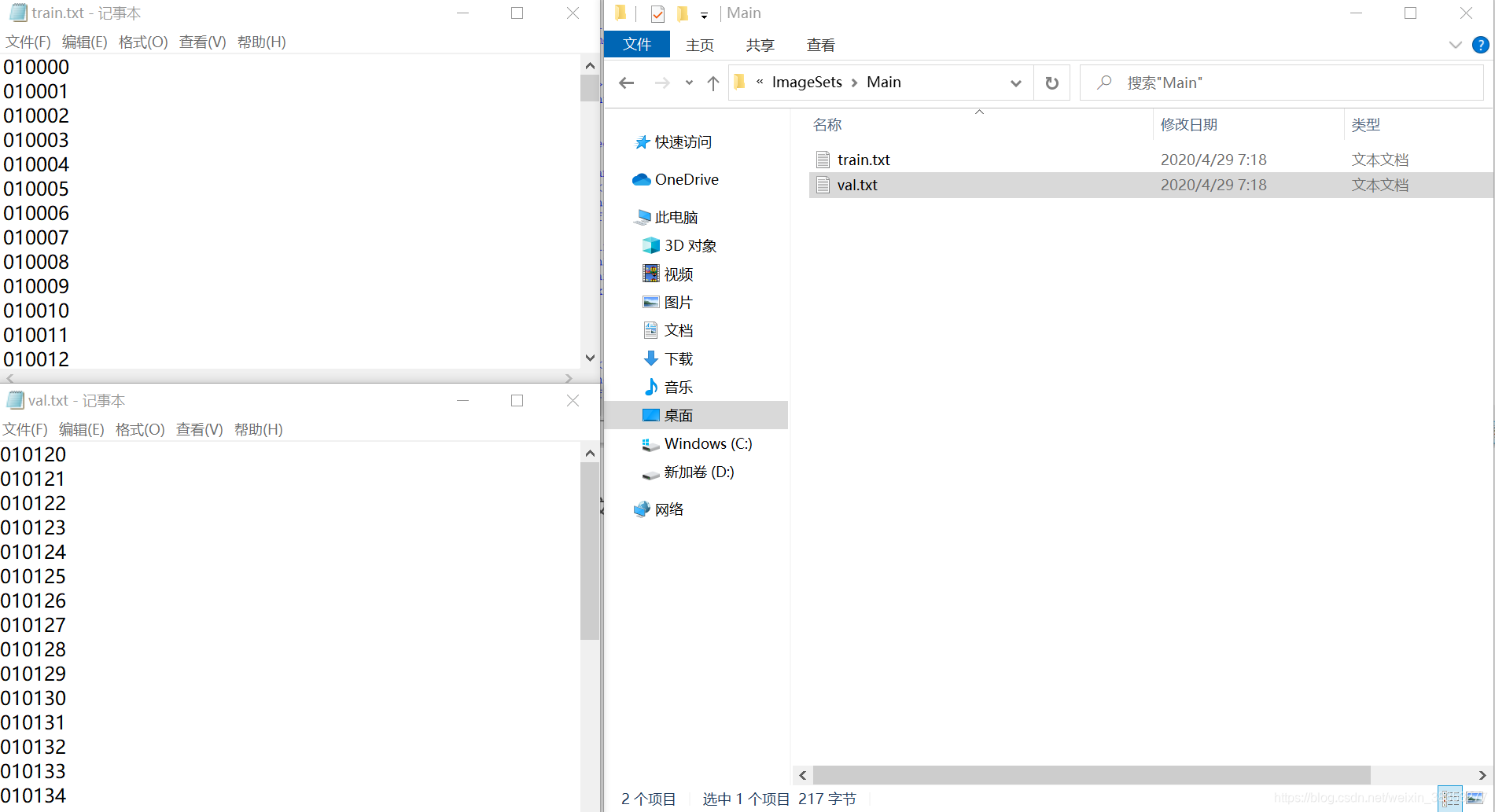
train.txt和val.txt里面是数据图像的名称,不附带格式.jpg
JPEGImages文件夹中时IMG原图片,如下图所示
transdata.py文件运行完,一定要去核对有没有生成这些数据,因为图片路径出错了可能会生成数据,但是文件里面时空的。
别着急,着急就懵逼了,这才到了处理图像的一半,接下来,需要我们生成训练用的数据集。
在主目录下生成两个文件夹train.txt和val.txt,这才是我们需要的数据,除此之外我们需要生成目标的label文件夹。
train.txt和val.txt是我们数据的绝对路径,根据每个文件位置不同则不同,例如:
/home/XXX/Desktop/YOLO V4/darknet-master//JPEGImages/010004.jpg
label文件夹里面也会生成以图片名称命名的txt文件,这些文件保存的是图片中的标签类别,中心点的x,中心点的y,标签的宽,边框的高。
那我们就用代码实现一下:
创建文件train_val_data.py
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=['train', 'val']#
classes = ['pingpang','cam'] # 这里是你自己的数据的类别
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open(wd + '/Annotations/%s.xml'%(image_id))
out_file = open( wd + '/labels/%s.txt'%(image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__=='__main__':
wd = getcwd()
wd = wd.replace('\\', '/')
for image_set in sets:
if not os.path.exists(wd + '/labels/'):
os.makedirs(wd + '/labels/')
image_ids = open(wd +'/ImageSets/Main/%s.txt' % image_set).read().strip().split()
list_file = open('%s.txt' % image_set, 'w')
for image_id in image_ids:
list_file.write(wd + '/JPEGImages/%s.jpg\n' % image_id)
convert_annotation(image_id)
list_file.close()
最后生成三个文件,一个train.txt,一个val.txt,一个label文件夹
其中:
train.txt和val.txt里面的内容如下图所示;
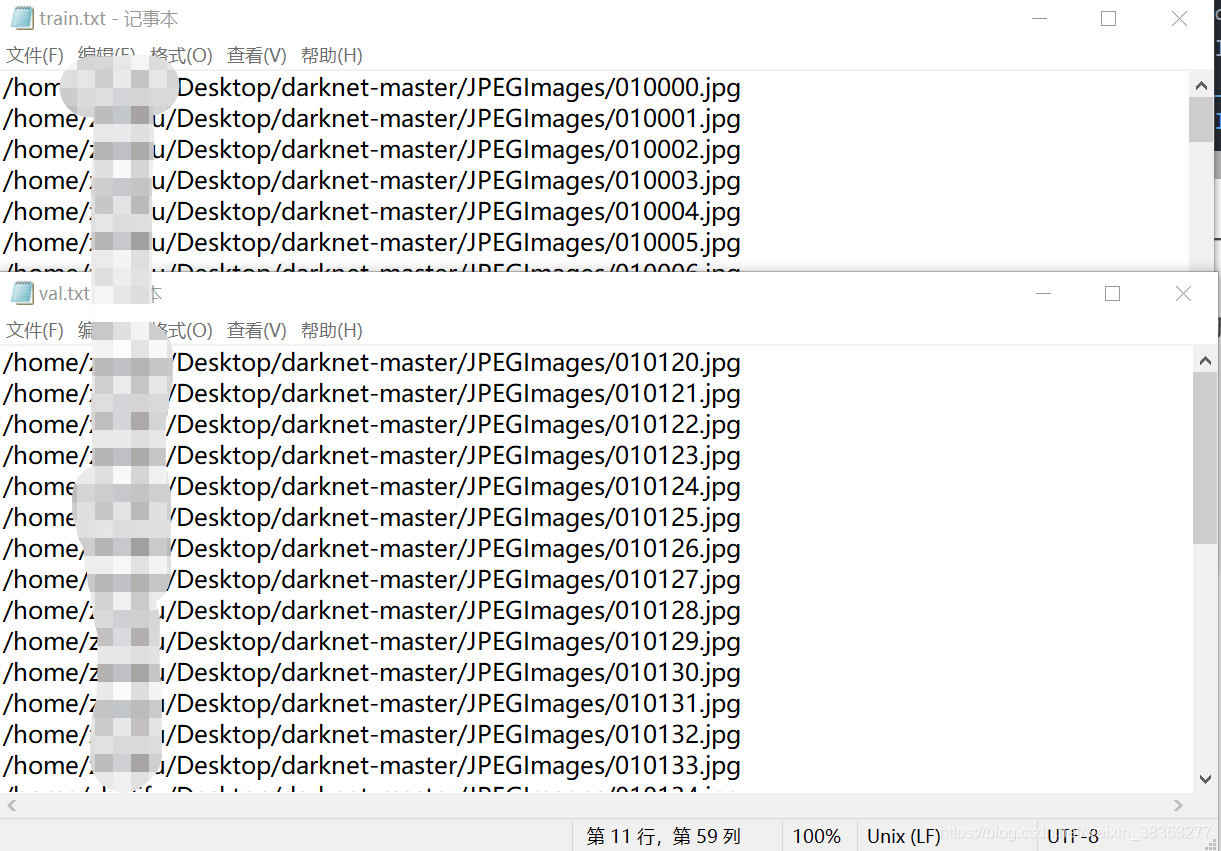 这里是训练数据的绝对路径,train和val数据比例自己打分。或者根据理论论文分;
这里是训练数据的绝对路径,train和val数据比例自己打分。或者根据理论论文分;
其次是label文件夹,具体内容是:
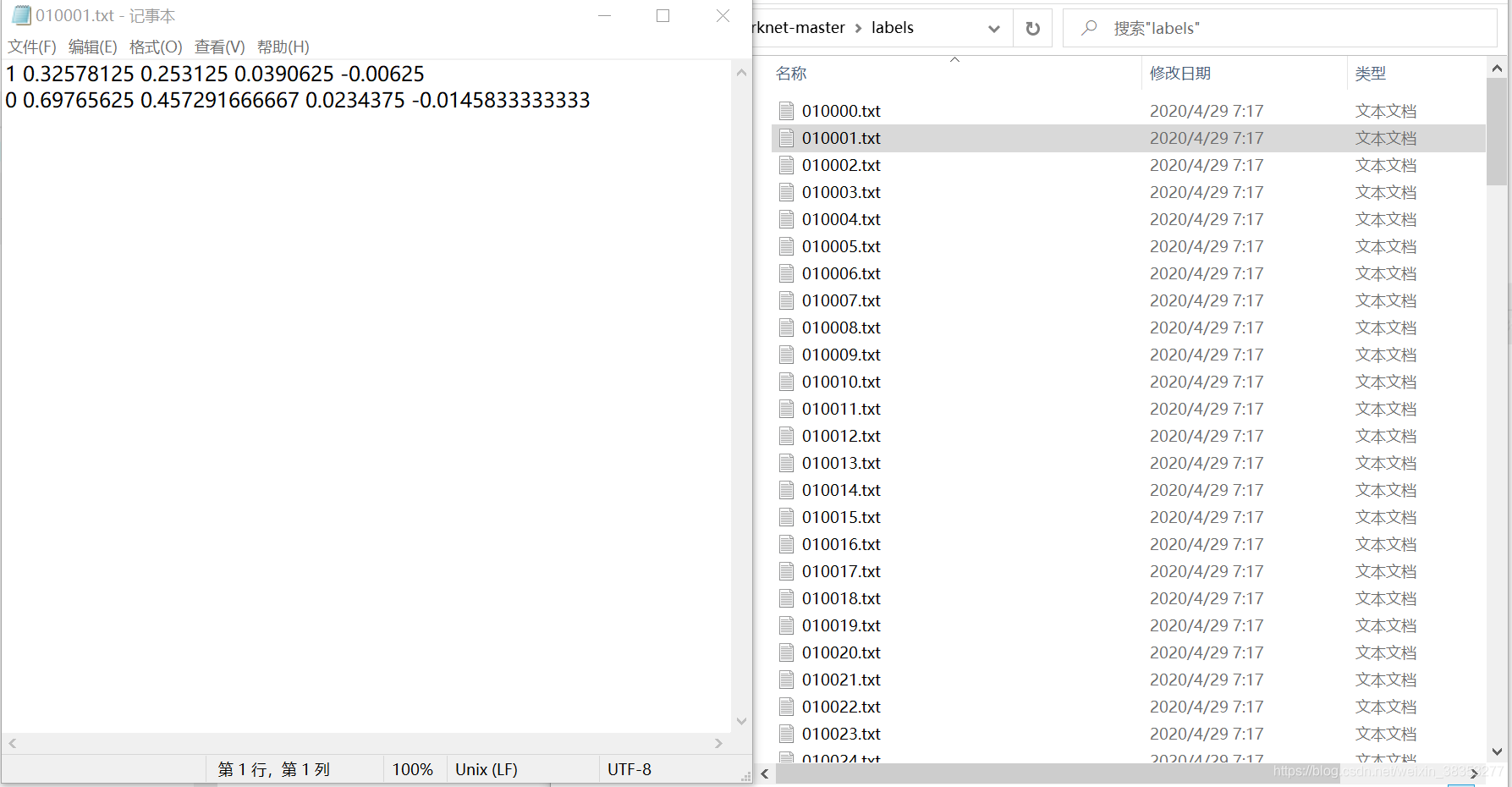
到此为止,数据的处理算是完了。
训练之前参数修改
首先修改,根目录下cfg文件夹里面的yolov4.cfg。
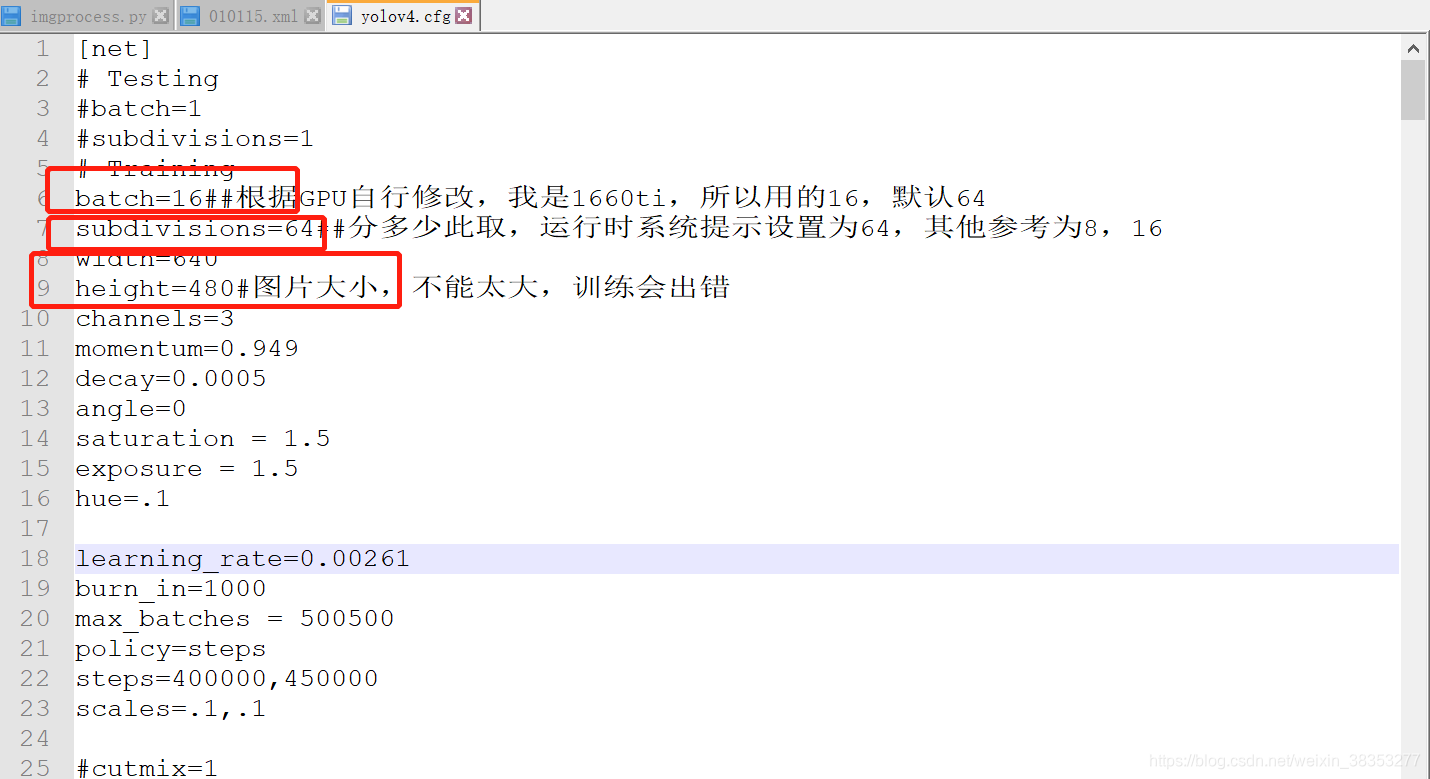
其他参数根据github介绍可参考,
下来时修改类别数,classes
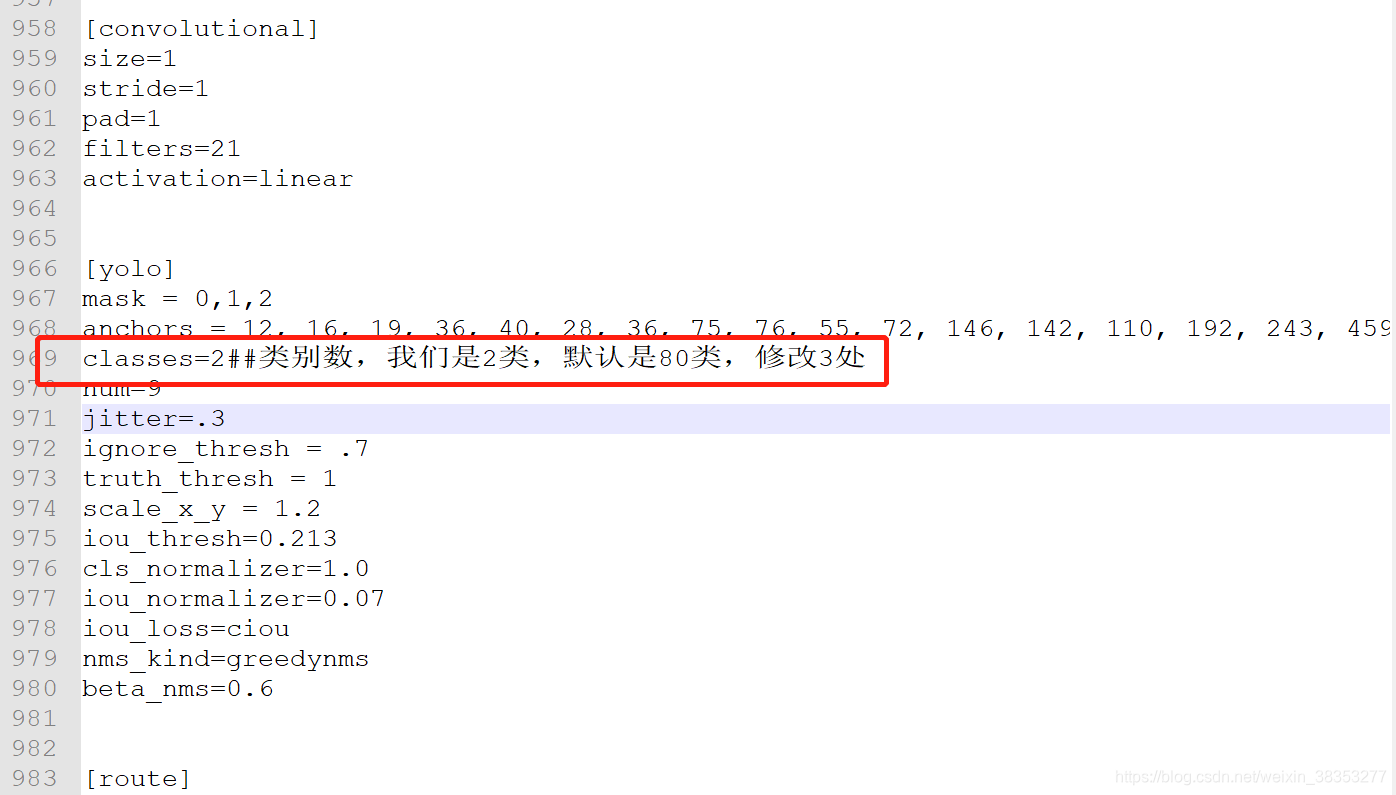
 以上是所有需要修改的参数
以上是所有需要修改的参数
接下配置cmake文件属性
打开根目录下的makefile文件如图所示:
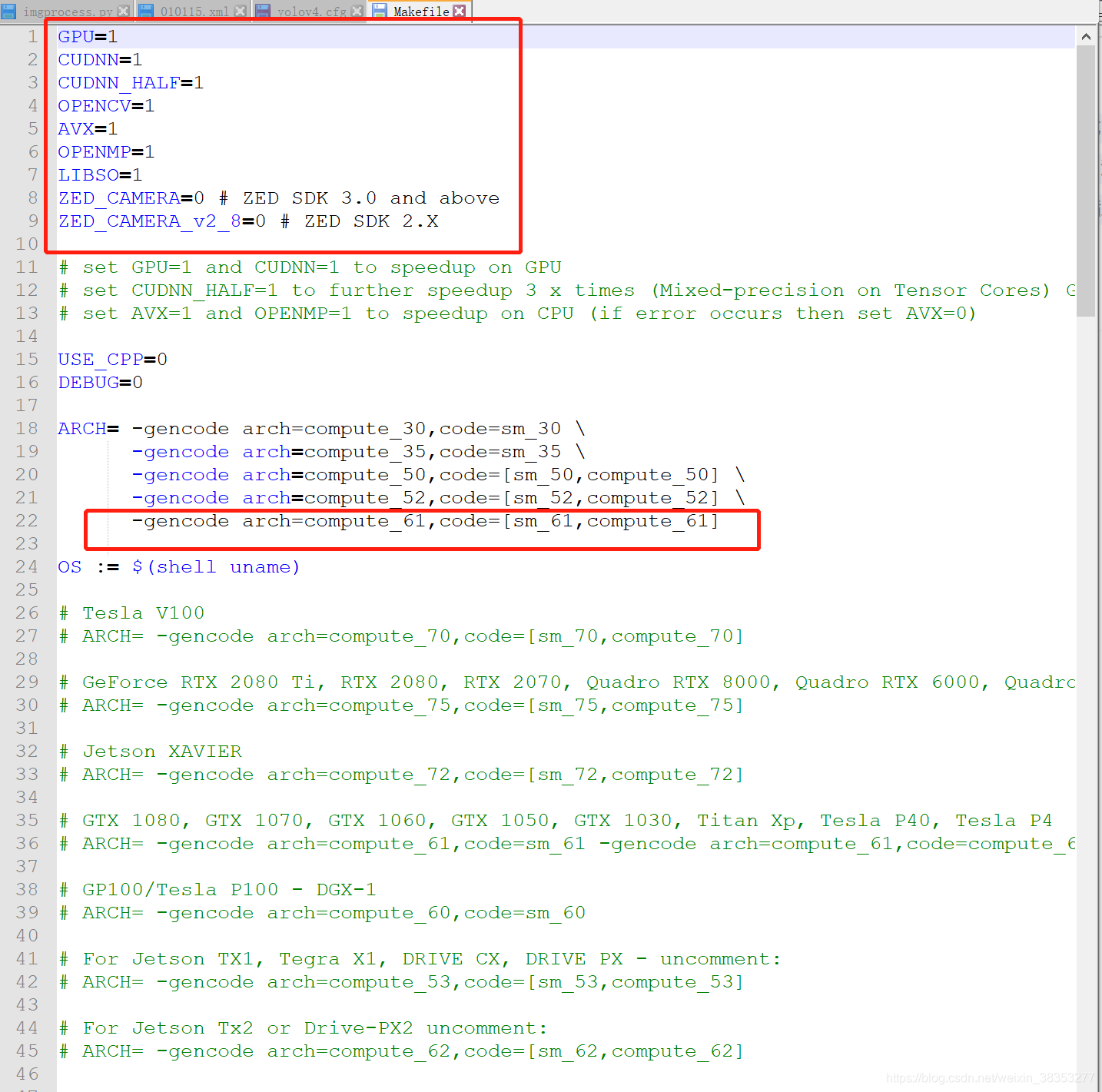
配置:
GPU=1;确定使用GPU,默认是0
CUDNN;设置为1
CUDNN_HALF =1
OPENCV=1(这个需要安装opencv)
ARCH有版本要求,可以查看工程文件中readme
配置好后。make,如果有错误百度,google搜索都有办法解决,同yolo v3
配置OPENCV
下载链接:https://opencv.org/ 读者下载的是opencv3.4.9下载源码自己编译;
第一步:
安装必备库
sudo apt-get install build-essential
sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
安装cmake
sudo apt-get install cmake
下载opencv:unzip opencv-3.4.2.zip
创建编译文件夹build
cd opencv
mkdir build
cd build
执行cmake
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local ..
等待cmake命令执行完成然后执行make
这里make一定要注意,因为我们配置了cuda和CUDNN.所以make会出错。很多错误,所以用下列指令:
sudo make -j8(直接sudo make 错误多到你吐血!)
sudo make install
sudo make install 执行完毕后OpenCV编译过程就结束了,接下来就需要配置一些OpenCV的编译环境首先将OpenCV的库添加到路径,从而可以让系统找到:
sudo gedit /etc/ld.so.conf.d/opencv.conf
然后加入如下指令:
export /usr/local/
sudo ldconfig
配置bashrc
sudo gedit /etc/bash.bashrc
加入末尾
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
export PKG_CONFIG_PATH
source /etc/bash.bashrc
结束opencv配置。
加油,伙伴们,成功就在眼前了
最终配置,要成功了
在根目录里创建2个文件
第一个起名叫train.data
里面的内容如图所示:

classes=2是训练种类;其他是训练数据的路径。backup是我们生成模型的存储位置
第二个文件时train.names放的是类别名称,如下图所示。

做了上面那些工作,终于可以开始训练了,终于可以了,终于可以了!!!!!!!
就一行指令:
sudo ./darknet detector train train.data cfg/yolov4.cfg yolov4.conv.137 -map
中yolov4.conv.137是预训练模型,需要另外进行下载,下载链接是:
https://drive.google.com/open?id=1JKF-bdIklxOOVy-2Cr5qdvjgGpmGfcbp
翻不了墙的留言,我给你哈!
如果没这个文件,只需要执行如下指令:
sudo ./darknet detector train train.data cfg/yolov4.cfg -map
yolov4和yolov3训练是不同的,yolov4训练的时候有一个动态图来显示,类似于tensorboard。
好了,训练结果就不发了,大家一起搞起来吧。到此就结束了,感觉有用给个赞噶!!!!!!!!!

















 4391
4391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









