






点击下方卡片,关注“小白玩转Python”公众号
在本文中,我们将解析 YOLOv5 目标检测模型的三个检测头的输出,并理解网格和锚点的概念。您可以将这一概念推广到其他版本的 YOLO。值得注意的是,所有 YOLOv5 模型(s、m、l、x)的三个检测头的输出张量形状都是相同的。
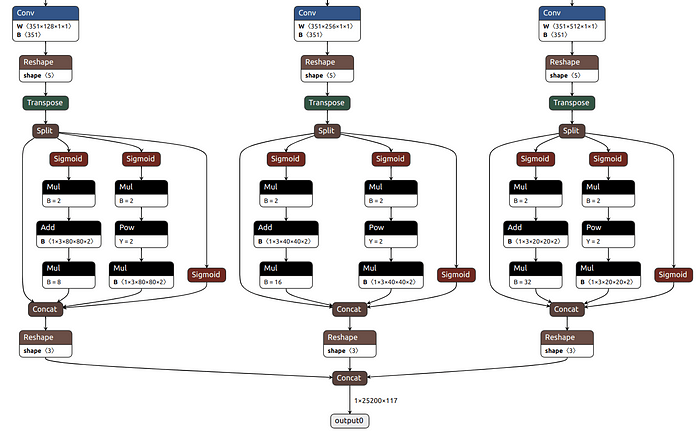
上图是 YOLOv5s 模型转换为 ONNX 格式后的 Netron 表示。图像显示了模型的边界框解码部分,我们将尝试理解这里发生的事情。图像顶部的三个卷积操作是检测头的输出。卷积头的输出形状如下:
head 1:3x80x80x117 -> 检测小尺寸目标
head 2:3x40x40x117 -> 检测中等尺寸目标
head 3:3x20x20x117 -> 检测大尺寸目标
接下来,我们将详细解析head 1。
什么是117?
数字117指的是 YOLOv5 目标检测模型输出张量的通道数。这可以进一步分解为:
目标得分:表示目标存在的概率。
𝛅x:预测边界框原点 x 坐标相对于网格原点的缩放偏差。
𝛅y:预测边界框原点 y 坐标相对于网格原点的缩放偏差。
𝛅h:预测边界框高度相对于锚框高度的缩放偏差。
𝛅w:预测边界框宽度相对于锚框宽度的缩放偏差。
剩下的112个通道用于编码检测到的目标的类别概率。值得注意的是,一些模型可能有不同的通道数,例如85。在这种情况下,模型是在 COCO 数据集的80个类别上训练的。
什么是80x80?
80x80 指的是在640x640尺寸的图像中用于检测小目标的网格数量,步长为8。每个网格为8x8像素,假设一个小目标可能在这8x8像素内找到。因此,总网格数量为80x80,这是通过将图像尺寸除以网格尺寸计算得出的。
由于 grid_size = 8x8,image_size = 640x640,网格数量 = image_size / grid_size = 80x80
重要的是要注意,YOLO 每个网格只能检测一个目标。
什么是3?
YOLO 中的数字3指的是捕捉不同尺度和纵横比的三种不同锚点。每个检测头有3个锚点,总共有9个锚点。这些锚点是通过分析真实边界框的分布来确定的。锚点表示为一个元组列表,例如 [(10, 13), (16, 30), (33, 23)],它们大致覆盖1:2、2:1和1:1的纵横比以及头1的不同尺度。
锚点基本上是预定义边界框的高度和宽度,现在 YOLO 预测的是这些预定义边界框高度和宽度的差异。
总结
在 YOLO 中,如果我们在 Head1_output[1, 1, 1, 1] 中获得一个高目标分数,这意味着原始图像的前8x8像素中可能存在一个物体,除非它被置信度阈值或NMS(非极大值抑制)排除。
我们可以使用 (𝛅x, 𝛅y) 值确定预测框的原点,以及在原始图像网格中的对应原点,即 (4, 4)。我们还可以使用 (𝛅h, 𝛅w) 值和通道一的预定义锚框确定预测框的高度和宽度。目标的类别可以使用第1点中解释的其余112个值确定。
对于中等目标,步长为16,网格大小为 (16x16),网格数量为 (40x40)。对于大目标,步长为32,网格大小为 (32x32),网格数量为 (20x20)。
如果我们移除NMS(非极大值抑制)和置信度阈值,YOLO 能检测的最大目标数量是 (20x20x3)+(40x40x3)+(80x80x3) = 252000,这是网格的总数量。这导致输出大小为 1x252000x117 = 29484000。最后,再结合置信度阈值和NMS来确定最终预测的边界框。
· END ·
🌟 想要变身计算机视觉小能手?快来「小白玩转Python」公众号!
回复“Python视觉实战项目”,解锁31个超有趣的视觉项目大礼包!🎁

本文仅供学习交流使用,如有侵权请联系作者















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









