






MAPPO论文全称为:The Surprising Effectiveness of MAPPO in Cooperative, Multi-Agent Games
这篇文章属于典型的,我看完我也不知道具体是在哪里创新的,是不是我漏读了什么,是不是我没有把握住,论文看一半直接看代码去了,因此后半截会有一段代码的解析。其实工作更多的我觉得是工程上的trick,思想很简单,暴力出奇迹。多智能体的合作和协同完全体现在对于观测空间的穷举。
官方开源代码为:https://github.com/marlbenchmark/on-policy
官方代码对环境的要求可能比较高,更加轻量版,对环境没有依赖的版本,更好方便移植到自己项目的代码为:https://github.com/tinyzqh/light_mappo。
这篇文章更多的提出的是一些工程上的trick,并且有较详细对比协作式多智能体的一些文章。
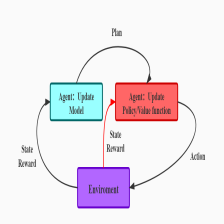
多智能体强化学习算法大致上可以分为两类,中心式和分散式。中心式的思想是考虑一个合作式的环境,直接将单智能体算法扩展,让其直接学习一个联合动作的输出,但是并不好给出单个智能体该如何进行决策。分散式是每个智能体独立学习自己的奖励函数,对于每个智能体来说,其它智能体就是环境的一部分,因此往往需要去考虑环境的非平稳态。并且分散式学习到的并不是全局的策略。
最近的一些工作提出了两种框架连接中心式和分散式这两种极端方法,从而得到折衷的办法:中心式训练分散式执行(centealized training and decentralized execution CTDE)和值分解(value decomposition VD)。
CETD的方式通过学习一个全局的Critic来减少值函数的方差,这类方法的代表作有MADDPG和COMA;VD通过对局部智能体的Q函数进行组合来得到一个联合的Q函数。
MAPPO采用一种中心式的值函数方式来考虑全局信息,属于CTDE框架范畴内的一种方法,通过一个全局的值函数来使得各个单个的PPO智能体相互配合。它有一个前身IPPO,是一个完全分散式的PPO算法,类似IQL算法。
MAPPO中每个智能体
i
i
i基于局部观测
o
i
o_{i}
oi和一个共享策略(这里的共享策略是针对智能体是同类型的情况而言的,对于非同类型的,可以拥有自己独立的actor和critic网络)
π
θ
(
a
i
∣
o
i
)
\pi_{\theta}(a_{i}|o_{i})
πθ(ai∣oi)去生成一个动作
a
i
a_{i}
ai来最大化折扣累积奖励:
J
(
θ
)
=
E
a
t
,
s
t
[
∑
t
γ
t
R
(
s
t
,
a
t
)
]
J(\theta)=\mathbb{E}_{a^{t}, s^{t}}\left[\sum_{t} \gamma^{t} R\left(s^{t}, a^{t}\right)\right]
J(θ)=Eat,st[∑tγtR(st,at)]。基于全局的状态
s
s
s来学习一个中心式的值函数
V
ϕ
(
s
)
V_{\phi}(s)
Vϕ(s)。
PPO实战技巧
对于单个智能体来说,PPO中实战的技巧也都有采用过来:
-
Generalized Advantage Estimation:这个技巧来自文献:Hign-dimensional continuous control using generalized advantage estimation。 -
Input Normalization -
Value Clipping:与策略截断类似,将值函数进行一个截断。 -
Relu activation with Orthogonal Initialization: -
Gredient Clipping:梯度更新不要太大。 -
Layer Normalization:这个技巧来自文献:Regularization matters in policy optimization-an empirical study on continuous control。 -
Soft Trust-Region Penalty:这个技巧来自文件:Revisiting design choices in proximal policy optimization。
MAPPO算法伪代码详解
MAPPO算法的伪代码如下所示:

也就是说有两个网络,策略
π
θ
\pi_{\theta}
πθ和值函数
V
ϕ
V_{\phi}
Vϕ。(作者在文献附录中有谈到说如果智能体是同种类的就采用相同的网络参数,对于每个智能体内部也可以采用各自的actor和critic网络,但是作者为了符号的便利性,直接就用的一个网络参数来表示)。值函数
V
ϕ
V_{\phi}
Vϕ需要学习一个映射:
S
→
R
S \rightarrow \mathbb{R}
S→R。策略函数
π
θ
\pi_{\theta}
πθ学习一个映射从观测
o
t
(
a
)
o_{t}^{(a)}
ot(a)到一个范围的分布或者是映射到一个高斯函数的动作均值和方差用于之后采样动作。
Actor网络优化目标为:
L ( θ ) = [ 1 B n ∑ i = 1 B ∑ k = 1 n min ( r θ , i ( k ) A i ( k ) , clip ( r θ , i ( k ) , 1 − ϵ , 1 + ϵ ) A i ( k ) ) ] + σ 1 B n ∑ i = 1 B ∑ k = 1 n S [ π θ ( o i ( k ) ) ) ] , where r θ , i ( k ) = π θ ( a i ( k ) ∣ o i ( k ) ) π θ old ( a i ( k ) ∣ o i ( k ) ) . \begin{array}{l} L(\theta) = {\left[\frac{1}{B n} \sum_{i=1}^{B} \sum_{k=1}^{n} \min \left(r_{\theta, i}^{(k)} A_{i}^{(k)}, \operatorname{clip}\left(r_{\theta, i}^{(k)}, 1-\epsilon, 1+\epsilon\right) A_{i}^{(k)}\right)\right]} \\ \left.+\sigma \frac{1}{B n} \sum_{i=1}^{B} \sum_{k=1}^{n} S\left[\pi_{\theta}\left(o_{i}^{(k)}\right)\right)\right], \text { where } r_{\theta, i}^{(k)}=\frac{\pi_{\theta}\left(a_{i}^{(k)} \mid o_{i}^{(k)}\right)}{\pi_{\theta_{\text {old }}}\left(a_{i}^{(k)} \mid o_{i}^{(k)}\right)} . \end{array} L(θ)=[Bn1∑i=1B∑k=1nmin(rθ,i(k)Ai(k),clip(rθ,i(k),1−ϵ,1+ϵ)Ai(k))]+σBn1∑i=1B∑k=1nS[πθ(oi(k)))], where rθ,i(k)=πθold (ai(k)∣oi(k))πθ(ai(k)∣oi(k)).
其中优势函数
A
i
(
k
)
A_{i}^{(k)}
Ai(k)是采用GAE方法的,
S
S
S表示策略的熵,
σ
\sigma
σ是控制熵系数的一个超参数。
Critic网络优化目标为:
L ( ϕ ) = 1 B n ∑ i = 1 B ∑ k = 1 n ( max [ ( V ϕ ( s i ( k ) ) − R ^ i ) 2 , ( clip ( V ϕ ( s i ( k ) ) , V ϕ old ( s i ( k ) ) − ε , V ϕ old ( s i ( k ) ) + ε ) − R ^ i ) 2 ] \begin{array}{l} L(\phi)=\frac{1}{B n} \sum_{i=1}^{B} \sum_{k=1}^{n}\left(\operatorname { m a x } \left[\left(V_{\phi}\left(s_{i}^{(k)}\right)-\right.\right.\right.\left.\hat{R}_{i}\right)^{2}, \\ \left(\operatorname{clip}\left(V_{\phi}\left(s_{i}^{(k)}\right), V_{\phi_{\text {old }}}\left(s_{i}^{(k)}\right)-\varepsilon, V_{\phi_{\text {old }}}\left(s_{i}^{(k)}\right)+\varepsilon\right)-\right.\left.\left.\hat{R}_{i}\right)^{2}\right] \end{array} L(ϕ)=Bn1∑i=1B∑k=1n(max[(Vϕ(si(k))−R^i)2,(clip(Vϕ(si(k)),Vϕold (si(k))−ε,Vϕold (si(k))+ε)−R^i)2]
其中
R
^
i
\hat{R}_{i}
R^i是折扣奖励。
B
B
B表示batch_size的大小,
n
n
n表示智能体的数量。
MAPPO实战技巧
- Value Normalization:
PopArt这个算法本来是用来处理多任务强化学习算法中,不同任务之间的奖励不一样的这样一个问题。例如,在吃豆人(Ms. Pac-Man)游戏中,智能体的目标是收集小球,收集一颗奖励10 分,而吃掉幽灵则奖励200到1600分,这样智能体对于不同任务就会有偏重喜好。MAPPO中采用这个技巧是用来稳定Value函数的学习,通过在Value Estimates中利用一些统计数据来归一化目标,值函数网络回归的目标就是归一化的目标值函数,但是当计算GAE的时候,又采用反归一化使得其放大到正常值。
这个技巧来自文献:Multi-task Deep Reinforcement Learning with popart。
- Agent-Specific Global State:
对于多智能体算法而言,大部分的工作都在处理值函数这一块,因为大部分算法都是通过值函数来实现各个子智能体的相互配合。值函数的输入通常也是直接给全局的状态信息
s
s
s使得一个部分可观测马尔可夫决策问题(POMDP)转化为了一个马尔可夫决策问题(MDP)。
Multi-agent actor-critic for mixed cooperative-competitive environment中提出将所有智能体地局部观测信息拼接起来
(
o
1
,
…
,
o
n
)
\left(o_{1}, \ldots, o_{n}\right)
(o1,…,on)作为Critic的输入,存在的问题就是智能体数量太多之后,尤其是值函数的输入维度远高于策略函数的输入维度的时候,会使得值函数的学习变得更加困难。
SMAC环境有提供一个包含所有智能体和敌方的全局信息,但是这个信息并不完整。虽然每个智能体的局部信息中会缺失敌方的信息,但是会有一些智能体特有的信息,像智能体的ID、可选动作、相对距离等等,这些在全局状态信息中是没有的。因此作者构建了一个带有智能体特征的全局状态信息,包含所有的全局信息和一些必须的局部智能体特有的状态特征。
- Training Data Usage:
通常训练单个智能体的时候,我们会将数据切分成很多个mini-batch,并且在一个epoch中将其多次训练来提高数据的利用效率,但是作者在实践中发现,可能是由于环境的非平稳态问题,如果数据被反复利用训练的话效果会不太好,因此建议对于简单的task用15个epoch,比较困难的任务用10个或者5个epoch,并且不要将数据切分成多个mini-batch。当然也不是绝对的,作者说到了对于SMAC中的一个环境,将数据切分成两个mini-batch的时候有提高性能,对此作者给出了解释说有帮助跳出局部最优,还引用了一篇参考文献。这一波说辞不是自相矛盾么。。。。
- Action Masking:
由于游戏规则的限制,在某些情况下,某些动作就是不允许被执行。当计算动作概率
π
θ
(
a
i
∣
o
i
)
\pi_{\theta}\left(a_{i} \mid o_{i}\right)
πθ(ai∣oi)的时候,我们将不被允许的动作直接mask掉,这样在前向和反向传播的过程中,这些动作将永远为0,作者发现这种做法能够加速训练。
- Death Masking:
如果智能体死掉了的话,在Agent-Specific特征中直接用一个0向量来描述即可。
代码解析
MAPPO官方代码链接:https://github.com/marlbenchmark/on-policy。
总体理解
每个局部智能体接收一个局部的观察obs,输出一个动作概率,所有的actor智能体都采用一个actor网络。critic网络接收所有智能体的观测obs,
c
e
n
t
_
o
b
s
_
s
p
a
c
e
=
n
×
o
b
s
_
s
p
a
c
e
cent\_obs\_space= n \times obs\_space
cent_obs_space=n×obs_space其中
n
n
n为智能体的个数,输出为一个
V
V
V值,这个
V
V
V值用于actor的更新。actor的loss和PPO的loss类似,有添加一个熵的loss。Critic的loss更多的是对value的值做normalizer,并且在计算episode的折扣奖励的时候不是单纯的算折扣奖励,有采用gae算折扣回报的方式。
- 网络定义
代码定义在onpolicy/algorithms/r_mappo/algorithm/rMAPPOPolicy.py
每一个智能体的观测obs_space为一个14维的向量,有两个智能体,cent_obs_space为一个28纬的向量,单个智能体的动作空间act_space为一个离散的5个维度的向量。
- actor
输入一个观测,14维度,输出一个确切的动作actions和这个动作对数概率,这部分代码在onpolicy/algorithms/utils/act.py中。
action_dim = action_space.n
self.action_out = Categorical(inputs_dim, action_dim, use_orthogonal, gain)
action_logits = self.action_out(x, available_actions)
actions = action_logits.mode() if deterministic else action_logits.sample()
action_log_probs = action_logits.log_probs(actions)
- critic
critic输入维度为
c
e
n
t
_
o
b
s
_
s
p
a
c
e
=
n
×
o
b
s
_
s
p
a
c
e
=
28
cent\_obs\_space= n \times obs\_space = 28
cent_obs_space=n×obs_space=28。输出是一个特征值向量,也就是输出纬度为1。
采样流程
- 初始化初始的观测
实例化5个环境:
# all_args.n_rollout_threads
SubprocVecEnv([get_env_fn(i) for i in range(all_args.n_rollout_threads)])
如果采用centralized_V值函数的训练方式,则需要初始化的时候构造出多个智能体的share_obs:
obs = self.envs.reset() # shape = (5, 2, 14)
share_obs = obs.reshape(self.n_rollout_threads, -1) # shape = (5, 28)
# 指定两个智能体
share_obs = np.expand_dims(share_obs, 1).repeat(self.num_agents, axis=1) # shape = (5, 2, 28)
share_obs中会将
n
=
2
n=2
n=2个智能体的obs叠加在一起作为share_obs。
- collect()采用rollout方式采样数据
调用self.trainer.prep_rollout()函数将actor和critic都设置为eval()格式。然后用np.concatenate()函数将并行的环境的数据拼接在一起,这一步是将并行采样的那个纬度降掉:
value, action, action_log_prob, rnn_states, rnn_states_critic \
= self.trainer.policy.get_actions(np.concatenate(self.buffer.share_obs[step]),
np.concatenate(self.buffer.obs[step]),
np.concatenate(self.buffer.rnn_states[step]),
np.concatenate(self.buffer.rnn_states_critic[step]),
np.concatenate(self.buffer.masks[step]))
上面的代码就是将数据传入总的MAPPO策略网络R_MAPPOPolicy(onpolicy/algorithms/r_mappo/algorithm/rMAPPOPolicy.py)中去获取一个时间步的数据。在get_actions()函数里面会调用actor去获取动作和动作的对数概率,critic网络去获取对于cent_obs的状态值函数的输出:
actions, action_log_probs, rnn_states_actor = self.actor(obs,
rnn_states_actor,
masks,
available_actions,
deterministic)
obs这里的shape是(5*2, 14),输出actions的shape, 和action_log_probs的shape都为(10 , 1)。
values, rnn_states_critic = self.critic(cent_obs, rnn_states_critic, masks)
cent_obs的shape是(5*2, 28),输出是shape=(10, 1)。
最后将(10 , 1)的actions转换成(5, 2, 1)的形式,方便之后并行送到并行的环境中去,作者这里还将动作进行了one-hot编码,最后变成了(5, 2, 5)的形式送入到环境中去。
obs, rewards, dones, infos = self.envs.step(actions_env)
data = obs, rewards, dones, infos, values, actions, action_log_probs, rnn_states, rnn_states_critic
# insert data into buffer
self.insert(data)
环境下一次输出的obs还是(5, 2, 14)的形式,之后调insert方法将数据添加到buffer里面,在insert方法里面会将局部观测构造一个全局观测share_obs其shape=(5, 2, 28)出来:
def insert(self, data):
obs, rewards, dones, infos, values, actions, action_log_probs, rnn_states, rnn_states_critic = data
rnn_states[dones == True] = np.zeros(((dones == True).sum(), self.recurrent_N, self.hidden_size), dtype=np.float32)
rnn_states_critic[dones == True] = np.zeros(((dones == True).sum(), *self.buffer.rnn_states_critic.shape[3:]), dtype=np.float32)
masks = np.ones((self.n_rollout_threads, self.num_agents, 1), dtype=np.float32)
masks[dones == True] = np.zeros(((dones == True).sum(), 1), dtype=np.float32)
if self.use_centralized_V:
share_obs = obs.reshape(self.n_rollout_threads, -1)
share_obs = np.expand_dims(share_obs, 1).repeat(self.num_agents, axis=1)
else:
share_obs = obs
self.buffer.insert(share_obs, obs, rnn_states, rnn_states_critic, actions, action_log_probs, values, rewards, masks)
上述过程循环迭代self.episode_length=200次。
训练流程
- 计算优势函数
训练开始之前,首先调用self.compute()函数计算这个episode的折扣回报,在计算折扣回报之前,先算这个episode最后一个状态的状态值函数next_values,其shape=(10, 1)然后调用compute_returns函数计算折扣回报:
def compute(self):
"""Calculate returns for the collected data."""
self.trainer.prep_rollout()
next_values = self.trainer.policy.get_values(np.concatenate(self.buffer.share_obs[-1]),
np.concatenate(self.buffer.rnn_states_critic[-1]),
np.concatenate(self.buffer.masks[-1]))
next_values = np.array(np.split(_t2n(next_values), self.n_rollout_threads))
self.buffer.compute_returns(next_values, self.trainer.value_normalizer)
有了数据之后就可以开始计算折扣回报了(这里有采用gae算折扣回报的方式,并且有将value做normalizer)。compute_returns函数在onpolicy/utils/shared_buffer.py文件中,核心代码如下:
self.value_preds[-1] = next_value
for step in reversed(range(self.rewards.shape[0])):
delta = self.rewards[step] + self.gamma * value_normalizer.denormalize(
self.value_preds[step + 1]) * self.masks[step + 1] \
- value_normalizer.denormalize(self.value_preds[step])
gae = delta + self.gamma * self.gae_lambda * self.masks[step + 1] * gae
self.returns[step] = gae + value_normalizer.denormalize(self.value_preds[step])
算完折扣回报之后调用self.train()函数进行训练:
def train(self):
"""Train policies with data in buffer. """
self.trainer.prep_training() # 将网络设置为train()的格式。
train_infos = self.trainer.train(self.buffer)
self.buffer.after_update() # 将buffer的第一个元素设置为其episode的最后一个元素
return train_infos
在self.trainer.train(self.buffer)函数中先基于数据,计算优势函数(优势函数是针对全局的观测信息所得到的):
advantages = buffer.returns[:-1] - self.value_normalizer.denormalize(buffer.value_preds[:-1])
advantages_copy = advantages.copy()
advantages_copy[buffer.active_masks[:-1] == 0.0] = np.nan
mean_advantages = np.nanmean(advantages_copy) # float, shape = (1)
std_advantages = np.nanstd(advantages_copy) # float, shape = (1)
advantages = (advantages - mean_advantages) / (std_advantages + 1e-5)
然后从buffer中采样数据,把线程、智能体的纬度全部降掉(onpolicy/algorithms/r_mappo/r_mappo.py):
share_obs_batch, obs_batch, rnn_states_batch, rnn_states_critic_batch, actions_batch, \
value_preds_batch, return_batch, masks_batch, active_masks_batch, old_action_log_probs_batch, \
adv_targ, available_actions_batch = sample
拿到采样之后的数据,把obs送给actor网络,得到action_log_probs, dist_entropy。把cent_obs送到critic得到新的values。
- 计算actor的loss
有了新老动作的概率分布和优势函数之后就可以更新actor网络了:
# actor update
imp_weights = torch.exp(action_log_probs - old_action_log_probs_batch)
surr1 = imp_weights * adv_targ
surr2 = torch.clamp(imp_weights, 1.0 - self.clip_param, 1.0 + self.clip_param) * adv_targ
policy_action_loss = (-torch.sum(torch.min(surr1, surr2),
dim=-1,
keepdim=True) * active_masks_batch).sum() / active_masks_batch.sum()
(policy_loss - dist_entropy * self.entropy_coef).backward()
- 计算critic的loss
新的value和老的value_preds_batch和计算的return_batch送到onpolicy/algorithms/r_mappo/r_mappo.py文件的cal_value_loss函数中去计算critic的loss:
value_loss = self.cal_value_loss(values, value_preds_batch, return_batch, active_masks_batch)
先对value做一个clipped:
value_pred_clipped = value_preds_batch + (values - value_preds_batch).clamp(-self.clip_param, self.clip_param)
然后计算误差的clip:
error_clipped = return_batch - value_pred_clipped
error_original = return_batch - values
有了误差直接就可以计算loss:
value_loss_clipped = mse_loss(error_clipped)
value_loss_original = mse_loss(error_original)
算出loss之后反向传播即可:
(value_loss * self.value_loss_coef).backward()
参考
The Surprising Effectiveness of MAPPO in Cooperative, Multi-Agent Games















 7146
7146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









