







The normal-distributionstransform
原文来自The Three-Dimensional Normal-Distributions Transform — an Efficient Representation for Registration, Surface Analysis, and Loop Detection 的第六章,其他章节内容有兴趣可以自行研究
用于表示曲面的NDT
第三章中讨论的距离传感器都输出点云:来自表面的一组空间采样点。此外,第5章中涉及的许多相关算法都是针对点云的。然而,使用点云来表示表面有许多限制。例如,点云不包含关于表面特征的明确信息,如方向、平滑度或孔洞。根据传感器配置,点云也可能效率低下,需要不必要的大量存储。为了在远离传感器的位置获得足够的样本分辨率,通常需要配置传感器,以便从靠近传感器的表面产生大量冗余数据。
正态分布变换可以描述为一种简单表示表面的方法。2003年,Biberand straer[7]首次提出它作为2D扫描配准的一种方法。Biber和straer后来在与Sven Fleck的联合论文[8]中对该方法进行了评价,也是在扫描配准和建图的背景下。该变换将点云映射到光滑的表面表示,描述为一组局部概率密度函数,每个概率密度函数描述表面的一部分的形状。
该算法的第一步是将扫描占据的空间细分为一个系列单元网格(2D的正方形,或3D的立方体)。基于单元内的点分布,为每个单元计算概率密度函数。每个单元中的PDF可以解释为单元内表面点
x
→
\overrightarrow{x}
x的生成过程。换句话说,假设通过刻画这个分布,已经生成了
x
→
\overrightarrow{x}
x的位置。假设参考表面点的位置是由一个D维正态随机过程产生的,那么已经测量到
x
→
\overrightarrow{x}
x的可能性为
p
(
x
→
)
=
1
(
2
π
)
D
/
2
∣
Σ
∣
e
x
p
(
−
(
x
→
−
μ
→
)
T
Σ
−
1
(
x
→
−
μ
→
)
2
)
(6.1)
p(\overrightarrow{x}) = \frac{1}{(2 \pi)^{D/2} \sqrt{|\Sigma|} }exp(-\frac{(\overrightarrow{x} - \overrightarrow{\mu})^T \Sigma^{-1} (\overrightarrow{x} - \overrightarrow{\mu})}{2}) \tag{6.1}
p(x)=(2π)D/2∣Σ∣1exp(−2(x−μ)TΣ−1(x−μ))(6.1)
这里
μ
→
\overrightarrow{\mu}
μ和
Σ
\Sigma
Σ表示
x
→
\overrightarrow{x}
x所处的单元格内参考扫描表面点云的均值向量和协方差矩阵。因子
(
(
2
π
)
D
/
2
∣
Σ
∣
)
−
1
( (2 \pi)^{D/2} \sqrt{|\Sigma|} )^{-1}
((2π)D/2∣Σ∣)−1对函数进行了缩放,使其积分为1。实际上,它可以用常数
c
0
c_0
c0来表示。均值和协方差的计算方法如下
μ
→
=
1
m
∑
k
=
1
m
y
→
k
(6.2)
\overrightarrow{\mu} = \frac{1}{m} \sum_{k=1}^{m}{\overrightarrow{y}_k} \tag{6.2}
μ=m1k=1∑myk(6.2)
Σ
=
1
m
−
1
∑
k
=
1
m
(
y
→
k
−
μ
→
)
(
y
→
k
−
μ
→
)
T
(6.3)
\Sigma = \frac{1}{m-1} \sum_{k=1}^{m}{(\overrightarrow{y}_k - \overrightarrow{\mu})(\overrightarrow{y}_k - \overrightarrow{\mu})^T} \tag{6.3}
Σ=m−11k=1∑m(yk−μ)(yk−μ)T(6.3)
其中
y
→
k
=
1
,
.
.
.
,
m
\overrightarrow{y}_{k = 1,...,m}
yk=1,...,m为网格内包含的参考扫描点的位置。
正态分布用连续导数给出点云的分段光滑表示。每个PDF都可以看作是局部表面的近似,描述了表面的位置以及方向和平滑度。2D激光扫描及其相应的正态分布如图6.1所示。图6.2显示了矿井隧道扫描的三维正态分布。


由于目前的工作主要集中在正态分布上,让我们更仔细地研究一下单变量和多变量正态分布的特征。在一维情况下,正态分布的随机变量
x
x
x有某个期望值
μ
\mu
μ,关于该值的不确定性用变量
σ
\sigma
σ表示。
p
(
x
)
=
1
σ
2
π
e
x
p
(
−
(
x
−
μ
)
2
2
σ
2
)
(6.4)
p(x) = \frac{1}{\sigma \sqrt{2 \pi}}exp(- \frac{(x - \mu)^2}{2 \sigma^2}) \tag{6.4}
p(x)=σ2π1exp(−2σ2(x−μ)2)(6.4)
在一维情况下(
D
=
1
D=1
D=1),方程6.1的多元概率密度函数
p
(
x
→
)
)
p(\overrightarrow{x}))
p(x))简化为上面的
p
(
x
)
p(x)
p(x)。在多维情况下,均值和方差由均值向量
μ
→
)
\overrightarrow{\mu})
μ)和协方差矩阵
Σ
\Sigma
Σ来描述。协方差矩阵的对角元素表示每个变量的方差,非对角元素表示变量的协方差。图6.3说明了一维、二维和三维的正态分布。

在2D和3D情况下,表面的方向和平滑度可以由协方差矩阵的特征向量和特征值来确定。特征向量描述分布的主要成分;也就是说,对应于变量的协方差的主导方向的一组正交向量。根据方差的比例,2D正态分布可以是点状(如果方差相似)或线状(如果一个比另一个大得多),或者介于两者之间。在3D情况下—如图6.4所示—正态分布可以描述为一个点或球体(如果所有方向上的方差大小相似),一条线(如果一个方向上的方差比另两个方向上的大得多),或者一个平面(如果一个方向上的方差比另两个方向上的小得多)。

NDT配准
当使用NDT进行扫描配准时,目标是找到当前扫描的位姿,使当前扫描的点位于参考扫描表面的可能性最大化。要优化的参数;即当前扫描的位姿估计的旋转和平移;可以用向量
p
→
\overrightarrow{p}
p来表示,当前扫描表示为点云
χ
=
{
x
→
1
,
.
.
.
x
→
n
}
\chi = \{\overrightarrow{x}_1,...\overrightarrow{x}_n\}
χ={x1,...xn}。假设有一个空间变换函数
T
(
p
→
,
x
→
)
T(\overrightarrow{p},\overrightarrow{x})
T(p,x)将一个点通过为姿
p
→
\overrightarrow{p}
p移动一个点
x
→
\overrightarrow{x}
x。给定一些扫描点的PDF
p
(
x
→
)
p(\overrightarrow{x})
p(x)(例如,公式6.1),最佳位姿
p
→
\overrightarrow{p}
p应该是最大化似然函数的位姿
Ψ
=
∏
k
=
1
n
p
(
T
(
p
→
,
x
→
k
)
)
(6.5)
\Psi = \prod_{k=1}^{n}{p(T(\overrightarrow{p},\overrightarrow{x}_k))} \tag{6.5}
Ψ=k=1∏np(T(p,xk))(6.5)
或者等效地,最小化
Ψ
\Psi
Ψ的负对数似然:
−
l
o
g
Ψ
=
−
∑
k
=
1
n
l
o
g
(
p
(
T
(
p
→
,
x
→
k
)
)
)
(6.6)
-log \Psi = -\sum_{k=1}^{n}{log(p(T(\overrightarrow{p},\overrightarrow{x}_k)))} \tag{6.6}
−logΨ=−k=1∑nlog(p(T(p,xk)))(6.6)
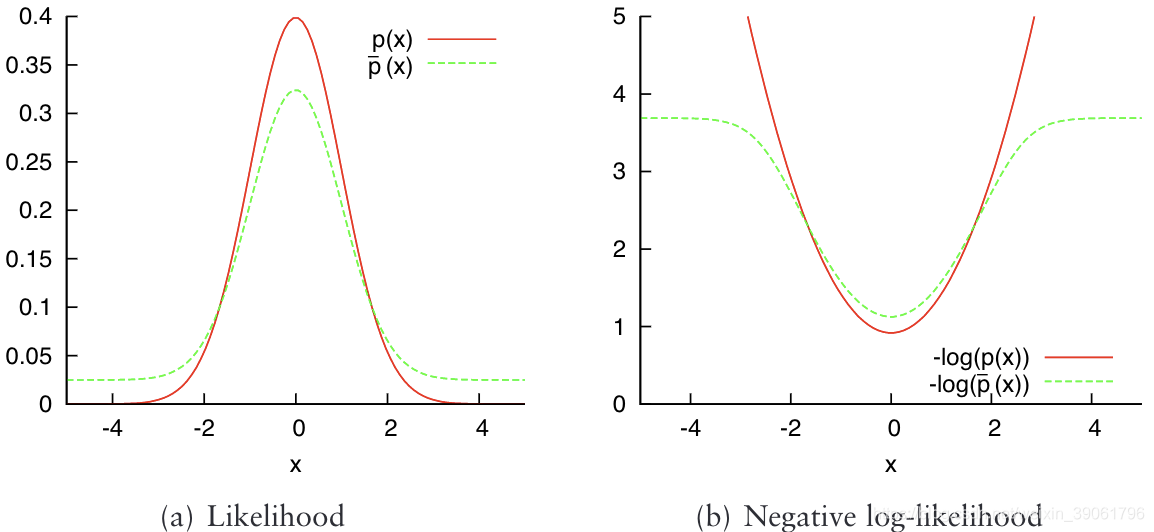
PDF不一定被限制为正态分布。任何局部捕捉表面点的结构并对对外点具有鲁棒性的PDF都是合适的。对于远离平均值的点,正态分布的负对数似然性在没有边界的情况下增长。因此,扫描数据中的异常值可能对结果有很大影响。在这项工作中(如Biber,Fleck和straer[8]的论文),使用了正态分布和均匀分布的混合:
p
ˉ
(
x
→
)
=
c
1
e
x
p
(
−
(
x
→
−
μ
→
)
T
Σ
−
1
(
x
→
−
μ
→
)
2
)
+
c
2
p
o
(6.7)
\bar{p}(\overrightarrow{x}) = c_1 exp(- \frac{ (\overrightarrow{x} - \overrightarrow{\mu})^T \Sigma^{-1} (\overrightarrow{x} - \overrightarrow{\mu}) }{2}) + c_2 p_o \tag{6.7}
pˉ(x)=c1exp(−2(x−μ)TΣ−1(x−μ))+c2po(6.7)
其中
p
o
p_o
po是异常值的预期比率。使用这个函数,外点的影响是有限的。这如图6.5所示。
常数
c
1
c_1
c1和
c
2
c_2
c2可以通过要求̄
p
(
x
→
)
p(\overrightarrow{x})
p(x)在一个单元所跨越的空间内积分等于1来确定。
待优化的对数似然能量函数的和由形式为对数的项组成
−
l
o
g
(
c
1
e
x
p
(
−
(
x
→
−
μ
→
)
T
Σ
−
1
(
x
→
−
μ
→
)
)
/
2
)
+
c
2
)
-log(c_1 exp( - (\overrightarrow{x} -\overrightarrow{\mu})^T \Sigma^{-1} (\overrightarrow{x} - \overrightarrow{\mu}))/2) + c_2)
−log(c1exp(−(x−μ)TΣ−1(x−μ))/2)+c2)。这些项没有简单的一阶和二阶导数。然而,图6.5(b)表明对数似然函数又可以用高斯函数来近似。形式为̄
p
ˉ
(
x
)
=
−
l
o
g
(
c
1
e
x
p
(
−
x
2
/
(
2
σ
2
)
)
/
2
)
+
c
2
)
\bar{p}(x) = -log(c_1 exp(-x^2 / (2 \sigma^2))/2) + c_2)
pˉ(x)=−log(c1exp(−x2/(2σ2))/2)+c2)的函数可以用高斯̃分布函数
p
~
(
x
)
=
d
1
e
x
p
(
−
d
2
x
2
/
(
2
σ
2
)
)
+
d
3
\tilde{p}(x) = d_1 exp(-d_2x^2/(2 \sigma^2)) + d_3
p~(x)=d1exp(−d2x2/(2σ2))+d3近似,拟合参数
d
i
d_i
di可以通过要求近似的高斯分布函数
p
~
(
x
)
\tilde{p}(x)
p~(x)在
x
=
μ
x = \mu
x=μ,
x
=
μ
+
σ
x = \mu + \sigma
x=μ+σ以及
x
=
∞
x = \infty
x=∞处与原始分布
p
(
x
)
p(x)
p(x)一致来求得
d
3
=
−
l
o
g
(
c
2
)
d
1
+
d
3
=
−
l
o
g
(
c
1
+
c
2
)
d
2
=
−
2
l
o
g
(
(
−
l
o
g
(
c
1
e
x
p
(
−
1
/
2
)
+
c
2
)
−
d
3
)
/
d
1
)
(6.8)
d_3 = -log(c_2)\\ d_1 + d_3 = -log(c_1 + c_2) \\ d_2 = -2 log( (-log(c_1 exp(-1/2) + c_2 ) - d_3) /d_1 ) \tag{6.8}
d3=−log(c2)d1+d3=−log(c1+c2)d2=−2log((−log(c1exp(−1/2)+c2)−d3)/d1)(6.8)
使用这种高斯近似,当前扫描的一个点对NDT分数函数的影响为
p
~
(
x
→
k
)
=
−
d
1
e
x
p
(
−
d
2
2
(
x
→
k
−
μ
→
k
)
T
Σ
−
1
(
x
→
k
−
μ
→
k
)
)
(6.9)
\tilde{p}(\overrightarrow{x}_k) = -d_1 exp(-\frac{d_2}{2} (\overrightarrow{x}_k - \overrightarrow{\mu}_k)^T \Sigma^{-1} (\overrightarrow{x}_k - \overrightarrow{\mu}_k) ) \tag{6.9}
p~(xk)=−d1exp(−2d2(xk−μk)TΣ−1(xk−μk))(6.9)
其中
μ
→
k
\overrightarrow{\mu}_k
μk和
Σ
k
\Sigma_k
Σk是
x
→
k
\overrightarrow{x}_k
xk所在的NDT网格的均值和协方差。这种NDT分数函数比等式6.7的对数具有更简单的导数,但是当用于优化时仍然表现出相同的一般性质。请注意,公式6.9中省略了
d
3
d_3
d3项。当使用NDT进行扫描配准时,这是不需要的,因为它只是给分数函数增加了一个恒定的偏移量,而不会改变其形状或被优化的参数。
给定一组点
χ
=
{
x
→
1
,
.
.
.
,
x
→
n
}
\chi = \{ \overrightarrow{x}_1,...,\overrightarrow{x}_n \}
χ={x1,...,xn},一个位姿
p
→
\overrightarrow{p}
p,一个变换函数
T
(
p
→
,
x
→
)
T(\overrightarrow{p},\overrightarrow{x})
T(p,x)通过位姿
p
→
\overrightarrow{p}
p对点
x
→
\overrightarrow{x}
x进行变换,当前参数向量的NDT得分函数
s
(
p
→
)
s(\overrightarrow{p})
s(p)为
s
(
p
→
)
=
−
∑
k
=
1
n
p
→
(
T
(
p
→
,
x
→
k
)
)
(6.10)
s(\overrightarrow{p}) = -\sum_{k=1}^{n}{\overrightarrow{p}(T(\overrightarrow{p},\overrightarrow{x}_k))} \tag{6.10}
s(p)=−k=1∑np(T(p,xk))(6.10)
这对应于当点被
p
→
\overrightarrow{p}
p变换后落在参考扫描表面上的可能性。
似然函数需要协方差矩阵的逆
Σ
−
1
\Sigma^{-1}
Σ−1。如果网格单元中的点完全共面或共线,则协方差矩阵是奇异的,不能求逆。在三维情况下,由三个点或更少点计算的协方差矩阵总是奇异的。因此,PDF仅针对包含五个以上点的单元格进行计算。此外,作为对数值问题的预防措施,
Σ
\Sigma
Σ只要被发现是接近奇异的,就会稍微膨胀。如果最大特征值
λ
3
\lambda_3
λ3比
λ
1
\lambda_1
λ1或
λ
2
\lambda_2
λ2大100倍以上,那么较小的特征值
λ
j
\lambda_j
λj被
λ
j
′
=
λ
3
/
100
\lambda_j^{'} = \lambda_3 / 100
λj′=λ3/100代替。用矩阵
Σ
′
=
V
Λ
′
V
\Sigma^{'} = V \Lambda ^{'} V
Σ′=VΛ′V代替
Σ
\Sigma
Σ,其中
V
V
V包含
Σ
\Sigma
Σ的特征向量并且
Λ
′
=
[
λ
1
′
0
0
0
λ
2
′
0
0
0
λ
3
]
.
(6.11)
\Lambda^{'} = \begin{bmatrix} \lambda_1^{'} & 0 & 0 \\ 0 & \lambda_2^{'} & 0 \\ 0 & 0 & \lambda_3 \end{bmatrix}. \tag{6.11}
Λ′=⎣⎡λ1′000λ2′000λ3⎦⎤.(6.11)
牛顿算法可以用来寻找优化的参数
p
→
\overrightarrow{p}
p。牛顿法迭代求解方程
H
Δ
p
→
=
−
g
→
H \Delta \overrightarrow{p} = -\overrightarrow{g}
HΔp=−g,其中
H
H
H和
g
→
\overrightarrow{g}
g是
s
(
p
→
)
s(\overrightarrow{p})
s(p)的Hessian矩阵和梯度向量。在每次迭代中,增量
Δ
p
→
\Delta \overrightarrow{p}
Δp被添加到当前位姿估计中,因此
p
→
←
p
→
+
Δ
p
→
\overrightarrow{p} \leftarrow \overrightarrow{p} + \Delta \overrightarrow{p}
p←p+Δp。
为了简洁起见,让
x
→
k
′
=
T
(
p
→
,
x
→
k
)
−
μ
→
k
\overrightarrow{x}_k^{'} = T(\overrightarrow{p}, \overrightarrow{x}_k) - \overrightarrow{\mu}_k
xk′=T(p,xk)−μk。换句话说
x
→
k
′
\overrightarrow{x}_k^{'}
xk′是
x
→
k
\overrightarrow{x}_k
xk被当前的位姿参数变换后距离它所属的网格中心的距离向量。可以写出梯度向量
g
→
\overrightarrow{g}
g的项
g
→
i
\overrightarrow{g}_i
gi
g
i
=
δ
s
δ
p
i
=
∑
k
=
1
n
d
1
d
2
x
→
k
′
T
Σ
k
−
1
δ
x
→
k
′
δ
p
i
e
x
p
(
−
d
2
2
x
→
k
′
T
Σ
k
−
1
x
→
k
′
)
(6.12)
g_i = \frac{\delta s}{\delta p_i} = \sum_{k=1}^{n}{d_1 d_2 {\overrightarrow{x}_k^{'}}^T \Sigma_k^{-1} \frac{\delta \overrightarrow{x}_k^{'}}{\delta p_i} exp(\frac{-d_2}{2} {\overrightarrow{x}_k^{'}}^T \Sigma_{k}^{-1} \overrightarrow{x}_k^{'} ) } \tag{6.12}
gi=δpiδs=k=1∑nd1d2xk′TΣk−1δpiδxk′exp(2−d2xk′TΣk−1xk′)(6.12)
Hessian矩阵
H
H
H的项
H
i
j
H_{ij}
Hij为

NDT分数函数的梯度(6.12)和Hessian矩阵(6.13)以相同的方式表达,不管配准是在2D还是在3D(或任何其他维度)中进行。它们同样独立于正在使用的转换表示。另一方面,方程6.12和6.13中$ \overrightarrow{x}^{’}
的
一
阶
和
二
阶
偏
导
数
依
赖
于
变
换
函
数
。
不
同
选
择
的
的一阶和二阶偏导数依赖于变换函数。不同选择的
的一阶和二阶偏导数依赖于变换函数。不同选择的T$的2D和3D配准之间的差异将在第6.2.1和6.2.2节中描述。
在之前的几篇关于NDT扫描配准的出版物[7,47,56,63,66,88]中,评分函数是直接使用正态分布的PDF中的高斯形式的和来定义的。尽管从概率的角度来看,这样的公式不太令人满意,但最终结果与使用混合模型对数似然的高斯近似(6.9)的结果(6.7)非常相似。
算法2描述了如何使用NDT方法配准两个点云
X
\mathcal{X}
X和
Y
\mathcal{Y}
Y。

2D-NDT
对于2D配准,有三个变换参数需要优化。设
p
→
=
[
t
x
,
t
y
,
ϕ
]
T
\overrightarrow{p} = [t_x,t_y,\phi]^T
p=[tx,ty,ϕ]T,其中
t
x
t_x
tx和
t
y
t_y
ty为平移参数,
ϕ
\phi
ϕ为旋转角度。使用逆时针旋转,2D变换函数是
T
2
(
p
→
,
x
→
)
=
[
c
o
s
ϕ
−
s
i
n
ϕ
s
i
n
ϕ
c
o
s
ϕ
]
x
→
+
[
t
x
t
y
]
(6.14)
T_2(\overrightarrow{p},\overrightarrow{x}) = \begin{bmatrix} cos \phi & -sin \phi \\ sin \phi & cos \phi \end{bmatrix} \overrightarrow{x} + \begin{bmatrix} t_x \\ t_y \end{bmatrix} \tag{6.14}
T2(p,x)=[cosϕsinϕ−sinϕcosϕ]x+[txty](6.14)
利用这个2D变换函数,由雅各比矩阵的
i
i
i列给出了用于计算方程6.12中梯度的一阶导数
δ
x
→
′
/
δ
p
→
i
\delta \overrightarrow{x}^{'} / \delta \overrightarrow{p}_i
δx′/δpi
J
2
=
[
1
0
−
x
1
s
i
n
ϕ
−
x
2
c
o
s
ϕ
0
1
x
1
c
o
s
ϕ
−
x
2
s
i
n
ϕ
]
.
(6.15)
J_2 = \begin{bmatrix} 1 & 0 &-x_1 sin\phi - x_2 cos \phi \\ 0 & 1 & x_1 cos \phi - x_2 sin\phi \end{bmatrix}. \tag{6.15}
J2=[1001−x1sinϕ−x2cosϕx1cosϕ−x2sinϕ].(6.15)
等式6.13中使用的二阶导数为
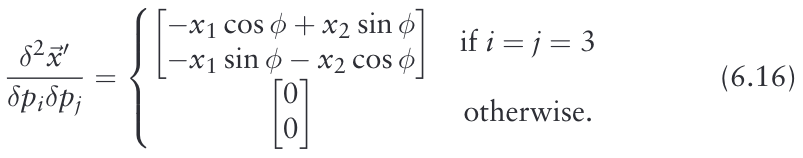
3D-NDT
2D与3DNDT配准的主要区别在于空间变换函数 T ( p → , x → ) T(\overrightarrow{p}, \overrightarrow{x}) T(p,x)及其偏导数。在2D中,旋转用绕原点旋转的角度的单个值来表示,最明显的变换函数是方程6.14中的一个。在3D情况下,有几种方法可以表示旋转,如第2.2节所述。
在我们先前的三维NDT工作[63,66]中,使用了轴/角旋转表示。然而,这样做给优化问题增加了一个额外的变量,并且需要额外的约束来保持旋转轴的单位长度。牛顿优化方法是一种迭代方法,在每次牛顿迭代后,只需对旋转表示重新归一化,就可以强制实施单位轴约束。然而,当牛顿更新方向偏离到位姿参数空间的不可行区域时,这种策略仍然会导致问题,这可以解释先前结果中的一些不一致。为完整起见,附录B.2中提供了轴/角度转换函数及其导数。
在下文中,将使用三维欧拉角,尽管这种旋转表示存在潜在的问题。这些优点——数值优化过程不需要进行约束,导数也稍微不那么复杂——被评估为超过万向节锁的风险,万向节锁只会在大角度出现,以至于局部配准过程无论如何都很可能失败。使用欧拉角,有六个变换参数需要优化:三个用于平移,三个用于旋转。可以使用六维参数向量 p → 6 = [ t x , t y , t z , ϕ x , ϕ y , ϕ z ] \overrightarrow{p}_6 = [t_x,t_y,t_z,\phi_x,\phi_y,\phi_z] p6=[tx,ty,tz,ϕx,ϕy,ϕz]对位姿进行编码。
使用欧拉序列
z
−
y
−
x
z-y-x
z−y−x,3D变换函数为
T
E
(
p
→
6
,
x
→
)
=
R
x
R
y
R
z
x
→
+
t
→
=
[
c
y
c
z
−
c
y
s
z
s
y
c
x
s
z
+
s
x
s
y
c
z
c
x
c
z
−
s
x
s
y
s
z
−
s
x
c
y
s
x
s
z
−
c
x
s
y
c
z
c
x
s
y
s
z
+
s
x
c
z
c
x
c
y
]
x
→
+
[
t
x
t
y
t
z
]
(6.17)
T_E(\overrightarrow{p}_6,\overrightarrow{x}) = R_xR_yR_z \overrightarrow{x} + \overrightarrow{t} \\ = \begin{bmatrix} c_yc_z & -c_ys_z & s_y \\ c_xs_z + s_x s_yc_z & c_xc_z-s_xs_ys_z & -s_xc_y \\ s_xs_z-c_xs_yc_z & c_xs_ys_z + s_x c_z & c_xc_y \end{bmatrix}\overrightarrow{x} + \begin{bmatrix} t_x \\ t_y \\ t_z \end{bmatrix} \tag{6.17}
TE(p6,x)=RxRyRzx+t=⎣⎡cyczcxsz+sxsyczsxsz−cxsycz−cyszcxcz−sxsyszcxsysz+sxczsy−sxcycxcy⎦⎤x+⎣⎡txtytz⎦⎤(6.17)
其中
c
i
=
c
o
s
ϕ
i
c_i = cos \phi_i
ci=cosϕi,
s
i
=
s
i
n
ϕ
i
s_i = sin \phi_i
si=sinϕi .方程6.17的一阶导数
δ
T
E
(
p
→
6
,
x
→
)
/
δ
p
i
\delta T_E(\overrightarrow{p}_6,\overrightarrow{x})/\delta p_i
δTE(p6,x)/δpi为
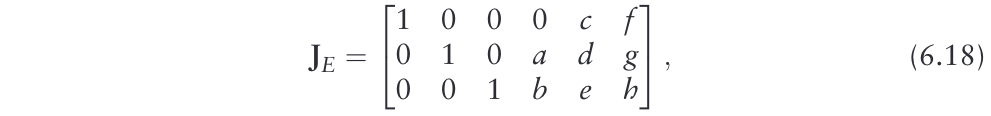
这里
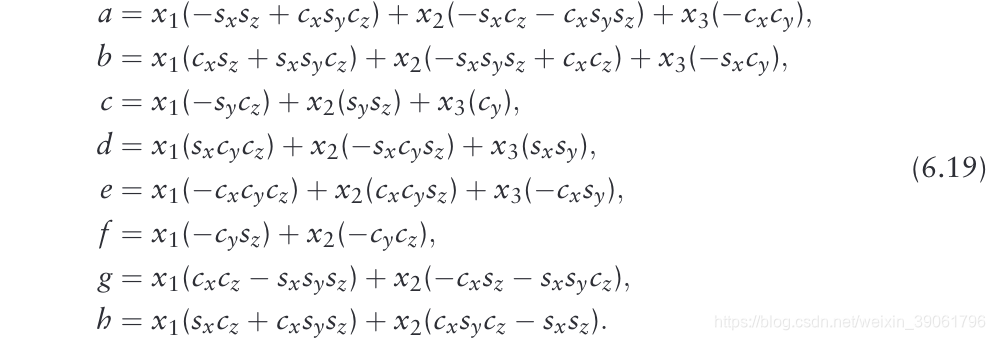
二阶导数
δ
2
T
E
(
p
→
6
,
x
→
)
/
δ
p
i
δ
p
J
\delta^2 T_E(\overrightarrow{p}_6,\overrightarrow{x})/\delta p_i \delta p_J
δ2TE(p6,x)/δpiδpJ为
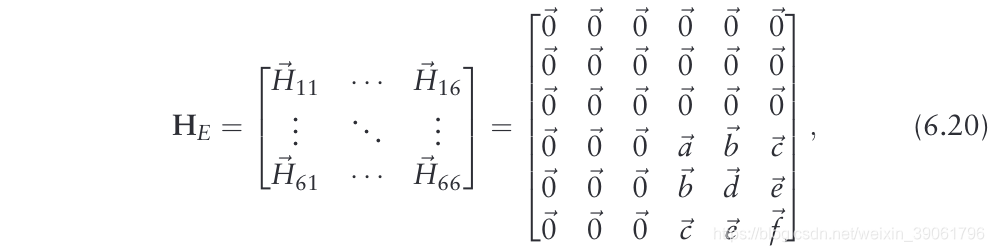
这里

通过对小角度使用以下的近似计算,可以大大简化计算:
s
i
n
ϕ
≈
ϕ
c
o
s
ϕ
≈
1
ϕ
2
≈
0
(6.22)
sin \phi \approx \phi \\ cos \phi \approx 1 \\ \phi^2 \approx 0 \tag{6.22}
sinϕ≈ϕcosϕ≈1ϕ2≈0(6.22)
对于小于
10
°
10\degree
10°的角度,这些近似值可以认为是精确的。对于正弦函数,在
14
°
14\degree
14°角时近似误差达到
1
1%
1。对于余弦,同样的误差出现在
8.2
°
8.2 \degree
8.2°角。当使用小角度近似时,计算变换函数及其导数更快,但是在某些情况下,与使用方程6.17相比,使用近似的配准不那么鲁棒。附录B.1中提供了相应的小角度近似的闭环函数。在时间要求严格的应用中,推荐使用近似公式,尽管差异很小。
对于非线性优化的许多应用,通常使用Hessian矩阵的数值近似代替解析的Hessian矩阵,因为Hessian矩阵无法解析计算,或者计算起来过于昂贵。然而,由于NDT评分函数的Hessian矩阵可以解析计算,并且其大部分元素为零,因此不使用近似值是有利的。为了完整起见,使用Hessian的BFGS近似[91]的准牛顿法已经与牛顿法和方程6.13的Hessian法进行了比较。使用拟牛顿法时,鲁棒性较低。一些准牛顿结果可以在附录C中找到。
3D-NDT扩展
本节描述了3-DNDT的一些扩展,旨在更好地表示潜在的表面。3D-NDT最重要的参数是网格尺寸。任何比单元尺寸小得多的特征都会被描述其周围局部表面形状的函数所模糊,因为正态分布是单峰的。选择一个太大的网格尺寸通常会导致不太精确的配准。另一方面,一个网格的影响区域只延伸到它的边界。也就是说,该单元将只对其边界内的扫描点的评分函数有贡献。这样做的一个结果是,如果网格尺寸太小,只有当两次扫描最初靠得很近时,配准才会成功。另一个问题是,对于较小的网格,可能根本不使用具有低点密度的部分扫描,因为每个网格至少需要五个点来计算可靠的协方差矩阵。使用更小的网格也需要更多的内存。因此,网格的最佳大小和分布取决于输入数据的形状和密度。他们还取决于应用对扫描表示保真度的要求。
使用正方形或立方体单元格的固定尺寸网格会给用户带来选择好的网格大小的任务。更灵活的网格结构是更可取的:在可能的情况下使用大网格,在单个正态分布不能令人满意地描述表面的地方使用更精细的网格划分。本节介绍了创建NDT网格结构和相关似然函数的多种替代方法。
固定尺寸离散化
抛开刚才提到的缺点,使用固定网格单元的好处是初始化和使用网格结构的开销非常小。每个网格只需要计算一组参数,每个网格的定位很简单。对于算法的性能更为重要的是,点到网格的查找可以在恒定时间内非常快速地完成,因为网格可以存储在一个简单的数组中。
八叉树离散化
八叉树是一种常用的树结构,可用于存储三维空间的分层离散。在八叉树中,每个节点代表空间的一个有界区间。每个内部节点有八个子节点,代表其父节点的空间分区的一致的不重叠的子区间。当创建八叉树时,根节点的大小被调整为包含整个参考扫描。然后递归地构建树,分割包含超过一定数量点的所有节点。所有数据点都包含在八叉树的叶节点中。八叉树非常类似于KD树,但是每个内部节点有八个而不是两个子节点。
如前所述,3D-NDT的八叉树版本从固定的规则网格开始,区别在于每个网格都是八叉树的根节点。分布方差大于某一阈值的所有网格被递归分割,形成八叉树森林。
对于NDT的效率来说,点对网格的查找是非常重要的,这也是使用八叉树森林的主要原因,而不是使用根节点跨越所有扫描的单个八叉树。对于许多类型的扫描数据,可以指定一个合理的基本网格大小,这样只需要分割扫描表面特别不均匀的部分中的几个网格。因此,对于大多数点来说,找到正确的网格只需要一次数组访问,而对于每个点来说,一次转换八叉树将花费更多的时间。一个森林比一棵树需要更多的内存,特别是当每棵树的根节点的网格很小时,但是这种影响对于本文介绍的实验来说可以忽略不计。
迭代离散化
另一种选择是,使用每次运行的最终为姿态作为下一次运行的初始位姿,以更高的网格分辨率执行多次NDT。第一次运行有助于将对齐不良的扫描更紧密地结合在一起,之后的运行改善了粗略的初始匹配的精度。
自适应聚类
一种更具适应性的离散化方法是使用聚类算法,该算法根据扫描点的位置将扫描点分成多个聚类,并为每个聚类使用一个NDT网格。
一种易于实现的通用聚类算法为k-means聚类[29],其工作原理如下。初始化 k k k个聚类中心,扫描点随机分配给聚类。聚类算法迭代推进。在每一步中,每个聚类的中心点是从它当前包含的点的质心计算出来的。每个点都被分配到最近的聚类中心。重复这两个步骤,直到在两次迭代之间没有更多的点改变聚类,或者直到改变的数量低于某个阈值。为了获得良好的聚类分布,没有特别大或者特别小的聚类,初始分布应均匀分布在扫描所占的空间体积上。然后聚类算法尝试将聚类移动到它们应该在的地方。使用这种离散化方法,必须预先确定网格的数量 k k k,但算法可以自动确定每个网格的大小,这与手动确定网格大小的其他离散化方法不同。图6.6显示了一个使用k均值聚类的网格分布示例。

链接网格
使用第6.2节中描述的NDT公式,位于没有被参考扫描表面占据的网格中的扫描点被丢弃。不使用这种方法,而是将最近的被占用的网格用于这些点。这增加了网格的影响范围。通常情况下,对于超出网格边界的部分,网格的函数值几乎为零,在这种情况下,它对分数没有实质性的贡献。但有些情况下(例如,对于点分布具有较大方差的网格),网格外的分布函数基本上不为零。
实现这种最近占用网格策略的一种方法是“链接单元”:让NDT网格中的每个网格存储一个指向最近网格单元的指针,并在网格中查询对应于某个点的网格时使用这些指针。这个实现已经在NDT配准[63,64,66]的早期工作中使用过。具有相同效果的另一种实现是在一个KD树搜索结构中只存储NDT网格的已占用网格,在KD树中查询最近的网格。如果有很多未被占用的网格则后者是更好的方法,并且是本工作中使用的实现。这种方法在下文中仍称为“链接网格”。
双线性插值
将空间细分为离散的网格会导致网格边缘的表面表示不连续,这有时会造成问题。在最初的2D-NDT实现[7]中,通过使用四个重叠的2D网格,离散化效果被最小化。类似的方法是使用四个(在2D)或八个(在3D)相邻网格的正态分布,每个网格的贡献权重由三线性插值(在2D为双线性)确定。换句话说,每个点的得分函数(6.9)被替换为
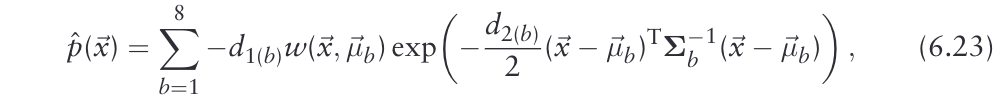
其中
q
→
b
\overrightarrow{q}_b
qb、
Σ
b
\Sigma_b
Σb和
d
i
(
b
)
d_{i(b)}
di(b)是最接近
x
→
\overrightarrow{x}
x的八个网格的均值、协方差和尺度参数;
w
(
x
→
,
μ
→
)
w(\overrightarrow{x},\overrightarrow{\mu})
w(x,μ)是一个三线性插值权重函数。等式6.23具有类似于Biber和Straber方法的平滑效果,而不需要计算更多的概率函数。效果如图6.7所示。

因为每个点需要评估多达八个函数,所以在最坏的情况下,该算法需要八倍于不使用三线性插值NDT的时间。然而,在参考扫描仅包含平面的情况下,因为表面没有占据周围所有的网格,使用插值的3D-NDT对每个点需要进行四次函数评估。在大多数使用真实世界扫描数据的情况下,使用插值的3D-NDT所花费的时间实际上是没有使用插值时的四倍左右,因为扫描点通常取自或多或少平坦的表面,而不是稠密地分布在三维空间中。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









