







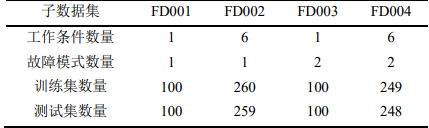
本例所用的数据集为C-MAPSS数据集,C-MAPSS数据集是美国NASA发布的涡轮风扇发动机数据集,其中包含不同工作条件和故障模式下涡轮风扇发动机多源性能的退化数据,共有 4 个子数据集,每个子集又可分为训练集、 测试集和RUL标签。其中,训练集包含航空发动机从开始运行到发生故障的所有状态参数; 测试集包含一定数量发动机从开始运行到发生故障前某一时间点的全部状态参数;RUL标签记录测试集中发动机的 RUL 值,可用于评估模 型的RUL预测能力。C-MAPSS数据集包含的基本信息如下:
添加图片注释,不超过 140 字(可选)
本例只采用FD001子数据集:

添加图片注释,不超过 140 字(可选)
关于python的集成环境,我一般Anaconda 和 winpython 都用,windows下主要用Winpython,IDE为spyder(类MATLAB界面)。
添加图片注释,不超过 140 字(可选)
正如peng wang老师所说
winpython, anaconda 哪个更好? - peng wang的回答 - 知乎 winpython, anaconda 哪个更好? - 知乎
winpython脱胎于pythonxy,面向科学计算,兼顾数据分析与挖掘;Anaconda主要面向数据分析与挖掘方面,在大数据处理方面有自己特色的一些包;winpython强调便携性,被做成绿色软件,不写入注册表,安装其实就是解压到某个文件夹,移动文件夹甚至放到U盘里在其他电脑上也能用;Anaconda则算是传统的软件模式。winpython是由个人维护;Anaconda由数据分析服务公司维护,意味着Winpython在很多方面都从简,而Anaconda会提供一些人性化设置。Winpython 只能在windows上用,Anaconda则有linux的版本。
抛开软件包的差异,我个人也推荐初学者用winpython,正因为其简单,问题也少点,由于便携性的特点系统坏了,重装后也能直接用。
请直接安装、使用winPython:WinPython download因为很多模块以及集成的模块
添加图片注释,不超过 140 字(可选)
可以选择版本,不一定要用最新版本,否则可能出现不兼容问题。
下载、解压后如下
添加图片注释,不超过 140 字(可选)
打开spyder就可以用了。
采用8种机器学习方法对NASA涡轮风扇发动机进行剩余使用寿命RUL预测,8种方法分别为:Linear Regression,SVM regression,Decision Tree regression,KNN model,Random Forest,Gradient Boosting Regressor,Voting Regressor,ANN Model。
首先导入相关模块
import pandas as pd import seaborn as sns import numpy as np import matplotlib.pyplot as plt from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.svm import SVR from sklearn.tree import DecisionTreeRegressor from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score import tensorflow as tf from tensorflow.keras.layers import Dense
版本如下ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2160
2160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











