









可解释人工智能如何进行创新?
(1)解释方法结合。现有的研究较少关注如何将不同的解释方法结合起来,未来可以考虑将不同的 解释方法结合在一起,如正反结合,事实解释侧重于 “为什么”,反事实解释侧重于“怎么做”,构建更为强大的模型解释方法。
(2)可靠性与稳定性。现有的一些解释方法是不可靠、不稳定的。如LIME,两个非常接近的点可能会导致两种截然不同的解释。因此,解释性算法还有 赖于可靠的理论基础。未来解释方法需要经过AI专家的认可,确保算法的内在可靠性。
(3)知识驱动。随着深度学习与知识图谱等技术的深度融合,利用数据中的因果与逻辑关系,助 力人工智能朝着认知智能的方面发展,例如,反事实解释研究目前缺乏因果约束,导致生成的反事实对用户来说是不可行的。因此,未来可以考虑在生成反事实之前利用领域知识增强特征之间的因果约束。
(4)评价体系。对XAI方法还没有一个统一的评价体系。虽然目前有研究从定性和定量两个角度进 行评估,但由于定性评估带有主观性和不可控性,而定量分析也没有达到相应的预期。究其原因,是由于决策者对于不同的决策任务有不同的理解和要求。
深度学习应用于一维时间序列时,如何探索其可解释性?
最简单的方法就是通过可视化图以直观地看出模型在做出分类决策时对于不同波形特征的依赖权重,为模型的可解释性提供依据,进而提高模型的可信度。以模型梯度类激活映射为例,数据为地震时间序列数据。
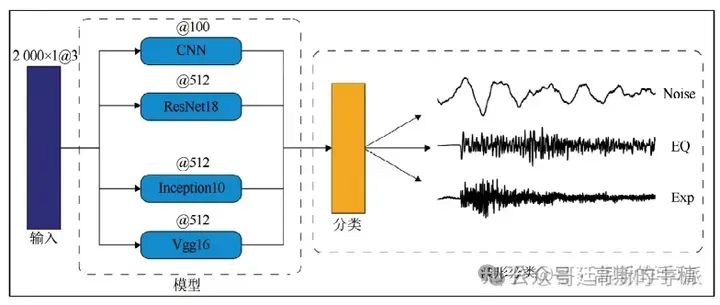
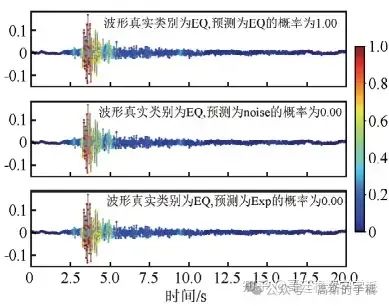
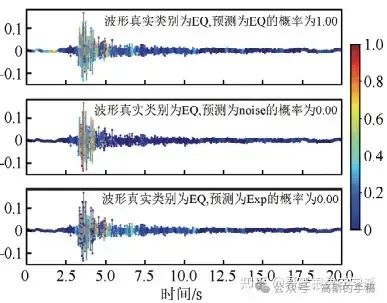
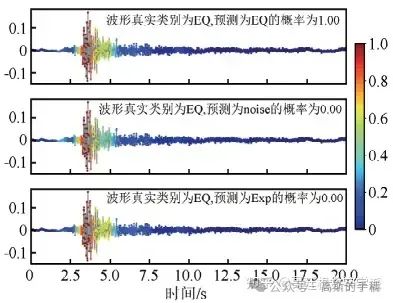
4种模型识别地震事件的可视化图如下,每个子图显示了模型做出分类决策所依赖的波形特 征,波 形特征的 grad-cam权重值越大,代表模型做出决策时更加依赖此波形特征,每个波形图的标题显示了波形的真实类别、预测类别以及预测概率,输入波形的真实类别为地震时间序列。
CNN模型
Inception10模型
vgg16模型
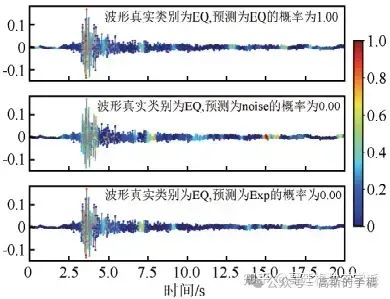
resnet18模型
CNN模型在识别地震波形时主要依赖于P波和S波,权值在S波之后显著下降。vgg16模型和CNN模型相似,同样将注意力放在P波和S波的震相上面,对于其他位置的关注度很低。resnet18模型模型更关注S波,对于P波的依赖较小。Inception10模型对于S波的关注度较大,分类时对于其他波段的关注度较小。
深度学习全局可解释性算法包括什么?
深度模型的全局可解释性算法主要关注模型本身的解释性以及神经元粒度上的特征表示,通过将模型内部的特征表示映射为图像空间的语义特征,从而提升模型的透明度。
常见的模型级可解释性算法包括激活最大化算法、网络压缩、知识蒸馏等,神经元级的解释性算法有基于激活最大化的算法和基于Network Dissection框架的可解释性算法。
模型级可解释性算法包括但不限于:
(1)模型级激活最大化算法

(2)代理模型
由于深度模型体量较大且结构复杂使得我们难以理解模型的行为,因此可以通过降低模型的复杂度来提升模型的解释性。代理模型在原始网络的基础上, 采用复杂度低、解释性好的替代模型来模仿原始模型进行决策。
(3)神经元级可解释性算法
神经元级可解释性算法主要关注网络中每个神经元所对应的语义特征,通过将神经元在特征空间中的表示映射到人类可理解的语义空间来揭示神经元所学习到的特征,这类算法主要有基于激活最大化的可解释性算法以及基于Network Dissection框架的可解释性算法。
深度学习中基于扰动的特征重要性分析是怎么?
这个算法挺有意思的,结合了泰勒展开这个微积分大杀器。
基于扰动的特征重要性分析的可解释性算法主要思想是对输入图像进行多次扰动,通过对比扰动前 后的图像在网络输出上的差异来判定被扰动特征对网络输出的重要程度,扰动的方式主要分为遮挡、擦除、 掩码等方式。可以将基于扰动的算法统一到泰勒展开的范式下,将扰动后的图像视为x0, 那么神经元或分类器输出的变化估计如下:
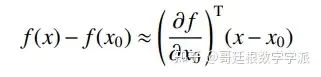
与基于反向传播算法相比,基于扰动的算法是模型无关的算法,它们不需要访问模型内部的参数。遮挡是最为常见的一种扰动方式,例如可以使用一个灰色的方块对图像进行滑动式的遮挡,将连续遮挡产生的图像输入网络中,将分类器输出的类别概率作为像素空间位置的函数进行可视化,通过这种方式可以定位出原始图像中对输出类别有较大影响的像素点集合。

如上图所示,原始图像被分类器正确分类为博美犬, 右图展示了对原始图像在不同位置进行遮挡后正确类别输出的概率图,可以发现在红色区域对图像进行遮挡时正确类别的输出概率变化不大,当对博美犬所在区域进行遮挡时尤其是面部进行遮挡时正确类别概率会急剧下降。
深度学习可解释性算法的性能评估指标有哪些?
目前关于深度模型的解释性算法越来越多,不同的解释性算法在同一模型上的表现也不尽相同,因此需要评价指标来衡量解释性算法的好坏。评估解释性算法的质量具有一定的挑战性,因为我们不清楚哪些特征对模型来说是重要的,导致我们无法提供相关的监督信息来对解释性算法进行统一的评估。因此,一些性能评估算法选择在不同的角度下对解释性算法进行比较,常见的评价指标如:敏感性、忠实性/准确性、一致性/鲁棒性/稳定性等。
● 可解释性算法的敏感性
关注解释性算法是否对模型的参数以及类别标签敏感,与模型相关的解释性算法需要访问模型参数, 那么我们应该期望这些解释性算法在不同网络参数下的解释结果应该有差异。同样的,一般来 说解释性算法依赖于数据标签,那么数据标签的变化也应该会导致不同的解释性结果。
● 可解释性算法的忠实性/准确性关注的是可解释性算法检测到的模型决策特征,对当前任务来说,是否是模型真正依赖的特征,该评价指标主要是基于扰动的思想来实施的。部分解释性算法会生成和输入图像大小一致的热力图,热力图中的数值大小反映着该像素特征的重要程度。
● 可解释性算法的稳定性/一致性要求输入相似的样本具有相似的解释结果。
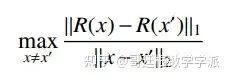
这个指标衡量输入相似的样本在解释性输出结果上的差异程度,如果解释性输出差异较大那么解释性算法的一致性 (鲁棒性/稳定性) 较差,则可设计攻击算法对输入图像进行微小扰动从而生成矛盾的解释结果, 这会使得用户怀疑解释性算法的可靠性。
知乎学术咨询:
工学博士,担任《Mechanical System and Signal Processing》等期刊审稿专家,擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。
















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











