









读《Python神经网络编程》总结
一些归纳
- 计算机编程语言可以理解矩阵计算,并认识到潜在的计算方法的相似性,这允许计算机高速高效地进行这些计算,算出X = W • I ,而无需我们对每一层的每个节点给出单独的计算指令。
- 为什么让误差反向传播到网络的每一层呢?原因是,我们使用误差来指导如何调整链接权重,从而改进神经网络输出的总体答案。
- 为了避免终止于错误的山谷或错误的函数最小值,我们从山上的不同点开始,多次训练神经网络,确保并不总是终止于错误的山谷。不同的起始点意味着选择不同的起始参数,在神经网络的情况下,这意味着选择不同的起始链接权重。
- 我们更喜欢使用差的平方作为误差函数,而不喜欢使用差的绝对值作为误差函数,原因有以下几点:
(1)使用误差的平方,我们可以很容易使用代数计算出梯度下降的斜率。
(2)误差函数平滑连续,这使得梯度下降法很好地发挥作用——没有间断,也没有突然的跳跃。
(3)越接近最小值,梯度越小,这意味着,如果我们使用这个函数调节步长,超调的风险就会变得较小。 - 选择使用100个隐藏层节点并不是通过使用科学的方法得到的。我们认为,神经网络应该可以发现在输入中的特征或模式,这些模式或特征可以使用比输入本身更简短的形式表达,因此没有选择比784大的数字。通过选择使用比输入节点的数量小的值,强制网络尝试总结输入的主要特点。但是,如果选择太少的隐藏层节点,那么就限制了网络的能力,使网络难以找到足够的特征或模式,也就会剥夺神经网络表达其对MNIST数据理解的能力。给定的输出层需要10个标签,对应于10个输出层节点,因此,选择100这个中间值作为中间隐藏层的节点数量,似乎有点道理。
- 这里应该强调一点。对于一个问题,应该选择多少个隐藏层节点,并不存在一个最佳方法。同时,我们也没有最佳方法选择需要几层隐藏层。就目前而言,最好的办法是进行实验,直到找到适合你要解决的问题的一个数字。
如何更新权重
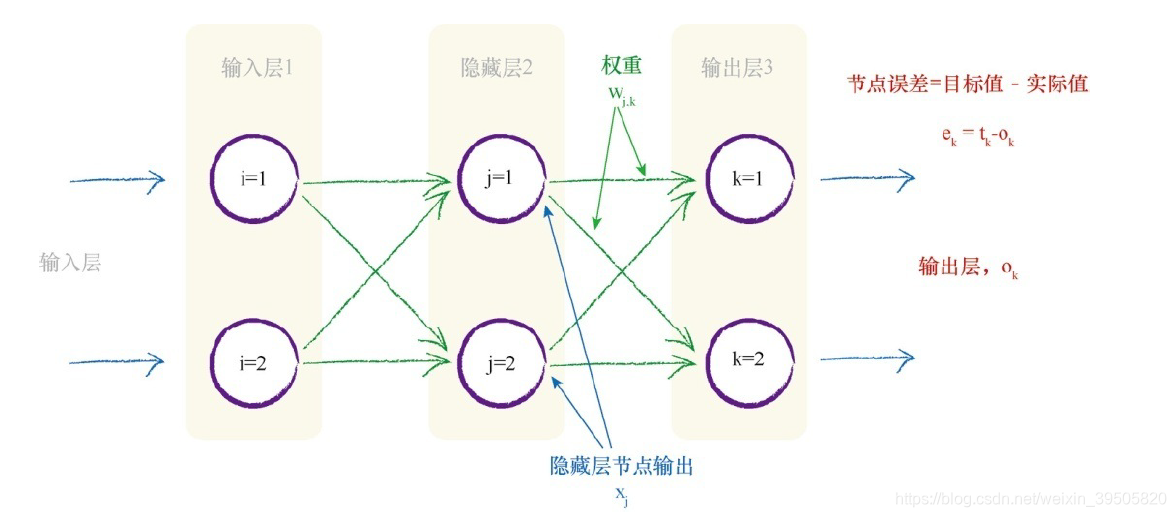
目标函数是E,也称为代价函数,损失函数。
∂
E
∂
w
j
,
k
\frac{\partial E}{\partial w_{j,k}}
∂wj,k∂E
这个表达式表示了当权重
w
j
,
k
w_{j,k}
wj,k改变时,误差E是如何改变的。这是误差函数的斜率,也就是我们希望使用梯度下降的方法到达最小值的方向。
∂
E
∂
w
j
,
k
=
∂
∑
n
(
t
n
−
o
n
)
2
∂
w
j
,
k
\frac{\partial E}{\partial w_{j,k}}=\frac{\partial \sum_{n}{(t_{n}-o_{n})^2}} {\partial w_{j,k}}
∂wj,k∂E=∂wj,k∂∑n(tn−on)2
在节点n的输出
o
n
o_{n}
on只取决于连接到这个节点的链接,因此我们可以直接简化这个表达式。。这意味着,由于这些权重是链接到节点k的权重,因此节点k的输出
o
k
o_{k}
ok只取决于权重
w
j
,
k
w_{j,k}
wj,k。
∂
E
∂
w
j
,
k
=
∂
(
t
k
−
o
k
)
2
∂
w
j
,
k
\frac{\partial E}{\partial w_{j,k}}=\frac{\partial (t_{k}-o_{k})^2} {\partial w_{j,k}}
∂wj,k∂E=∂wj,k∂(tk−ok)2
将这个微积分任务分解成更多易于管理的小块
∂
E
∂
w
j
,
k
=
∂
E
∂
o
k
⋅
∂
o
k
∂
w
j
,
k
\frac{\partial E}{\partial w_{j,k}}=\frac{\partial E} {\partial o_{k}} \cdot \frac{\partial o_{k}} {\partial w_{j,k}}
∂wj,k∂E=∂ok∂E⋅∂wj,k∂ok
我们对平方函数进行简单的微分,就很容易击破了第一个简单的项。对于第二项,我们需要仔细考虑一下,但是无需考虑过久。
o
k
o_{k}
ok是节点k的输出,如果你还记得,这是在连接输入信号上进行加权求和,在所得到结果上应用S函数得到的结果。
∂
E
∂
w
j
,
k
=
−
2
(
t
k
−
o
k
)
⋅
∂
s
i
g
m
o
i
d
(
∑
j
w
j
,
k
⋅
o
j
)
∂
o
k
\frac{\partial E}{\partial w_{j,k}}=-2(t_{k}-o_{k}) \cdot \frac{\partial sigmoid(\sum_{j}{w_{j,k}\cdot o_{j}})} {\partial o_{k}}
∂wj,k∂E=−2(tk−ok)⋅∂ok∂sigmoid(∑jwj,k⋅oj)
对S函数求微分,这对我们而言是一种非常艰辛的方法,但是,其他人已经完成了这项工作。我们可以只使用众所周知的答案,就像全世界的数学家每天都在做的事情一样。
∂
s
i
g
m
o
i
d
(
x
)
∂
x
=
s
i
g
m
o
i
d
(
x
)
(
1
−
s
i
g
m
o
i
d
(
x
)
)
\frac{\partial sigmoid(x)}{\partial x}=sigmoid(x)(1-sigmoid(x))
∂x∂sigmoid(x)=sigmoid(x)(1−sigmoid(x))
在微分后,一些函数变成了非常可怕的表达式。S函数微分后,可以得到一个非常简单、易于使用的结果。在神经网络中,这是S函数成为大受欢迎的激活函数的一个重要原因。
∂
E
∂
w
j
,
k
=
−
2
(
t
k
−
o
k
)
⋅
s
i
g
m
o
i
d
(
∑
j
w
j
,
k
⋅
o
j
)
(
1
−
s
i
g
m
o
i
d
(
∑
j
w
j
,
k
⋅
o
j
)
)
⋅
∂
∑
j
w
j
,
k
⋅
o
j
∂
w
j
,
k
=
−
2
(
t
k
−
o
k
)
⋅
s
i
g
m
o
i
d
(
∑
j
w
j
,
k
⋅
o
j
)
(
1
−
s
i
g
m
o
i
d
(
∑
j
w
j
,
k
⋅
o
j
)
)
⋅
o
j
\frac{\partial E}{\partial w_{j,k}}=-2(t_{k}-o_{k}) \cdot sigmoid(\sum_{j}{w_{j,k} \cdot o_{j}}) (1-sigmoid(\sum_{j}{w_{j,k} \cdot o_{j}})) \cdot \frac{\partial \sum_{j}{w_{j,k}\cdot o_{j}}} {\partial w_{j,k}} \\ =-2(t_{k}-o_{k}) \cdot sigmoid(\sum_{j}{w_{j,k} \cdot o_{j}}) (1-sigmoid(\sum_{j}{w_{j,k} \cdot o_{j}})) \cdot o_{j}
∂wj,k∂E=−2(tk−ok)⋅sigmoid(j∑wj,k⋅oj)(1−sigmoid(j∑wj,k⋅oj))⋅∂wj,k∂∑jwj,k⋅oj=−2(tk−ok)⋅sigmoid(j∑wj,k⋅oj)(1−sigmoid(j∑wj,k⋅oj))⋅oj
在写下最后的答案之前,让我们把在前面的2去掉。我们只对误差函数的斜率方向感兴趣,这样我们就可以使用梯度下降的方法,因此可以去掉2。只要我们牢牢记住需要什么,在表达式前面的常数,无论是2、3还是100,都无关紧要。因此,去掉这个常数,让事情变得简单。
∂
E
∂
w
j
,
k
=
−
(
t
k
−
o
k
)
⋅
s
i
g
m
o
i
d
(
∑
j
w
j
,
k
⋅
o
j
)
(
1
−
s
i
g
m
o
i
d
(
∑
j
w
j
,
k
⋅
o
j
)
)
⋅
o
j
\frac{\partial E}{\partial w_{j,k}}=-(t_{k}-o_{k}) \cdot sigmoid(\sum_{j}{w_{j,k} \cdot o_{j}}) (1-sigmoid(\sum_{j}{w_{j,k} \cdot o_{j}})) \cdot o_{j}
∂wj,k∂E=−(tk−ok)⋅sigmoid(j∑wj,k⋅oj)(1−sigmoid(j∑wj,k⋅oj))⋅oj
我们所得到的这个表达式,是为了优化隐藏层和输出层之间的权重。现在,我们需要完成工作,为输入层和隐藏层之间的权重找到类似的误差斜率。这是我们所得到误差函数斜率,用于输入层和隐藏层之间权重调整。
∂
E
∂
w
j
,
k
=
−
(
e
j
)
⋅
s
i
g
m
o
i
d
(
∑
i
w
i
,
j
⋅
o
i
)
(
1
−
s
i
g
m
o
i
d
(
∑
i
w
i
,
j
⋅
o
i
)
)
⋅
o
i
\frac{\partial E}{\partial w_{j,k}}=-(e_{j}) \cdot sigmoid(\sum_{i}{w_{i,j} \cdot o_{i}}) (1-sigmoid(\sum_{i}{w_{i,j} \cdot o_{i}})) \cdot o_{i}
∂wj,k∂E=−(ej)⋅sigmoid(i∑wi,j⋅oi)(1−sigmoid(i∑wi,j⋅oi))⋅oi
权重改变的方向与梯度方向相反。我们使用学习因子,调节变化,我们可以根据特定的问题,调整这个学习因子。当我们建立线性分类器,作为避免被错误的训练样本拉得太远的一种方式,同时也为了保证权重不会由于持续的超调而在最小值附近来回摆动,我们都发现了这个学习因子。让我们用数学的形式来表达这个因子。
n
e
w
w
j
,
k
=
o
l
d
w
j
,
k
−
α
⋅
∂
E
∂
w
j
,
k
new_{w_{j,k}}=old_{w_{j,k}}-\alpha \cdot \frac{\partial E}{\partial w_{j,k}}
newwj,k=oldwj,k−α⋅∂wj,k∂E
正如我们先前所看到的,如果斜率为正,我们希望减小权重,如果斜率为负,我们希望增加权重,因此,我们要对斜率取反。符号α是一个因子,这个因子可以调节这些变化的强度,确保不会超调。我们通常称这个因子为学习率。
(
Δ
w
1
,
1
Δ
w
2
,
1
Δ
w
3
,
1
⋯
Δ
w
1
,
2
Δ
w
2
,
2
Δ
w
3
,
2
⋯
Δ
w
1
,
3
Δ
w
2
,
3
Δ
w
j
,
k
⋯
⋯
⋯
⋯
⋯
)
=
(
E
1
∗
S
1
(
1
−
S
1
)
E
2
∗
S
2
(
1
−
S
2
)
E
k
∗
S
k
(
1
−
S
k
)
⋯
)
⋅
(
o
1
o
2
o
j
⋯
)
\left( \begin{matrix} \Delta w_{1,1} & \Delta w_{2,1} & \Delta w_{3,1} & \cdots \\ \Delta w_{1,2} & \Delta w_{2,2} & \Delta w_{3,2} & \cdots \\ \Delta w_{1,3} & \Delta w_{2,3} & \Delta w_{j,k} & \cdots \\ \cdots & \cdots & \cdots & \cdots \\ \end{matrix} \right) =\left( \begin{matrix} E_{1}*S_{1}(1-S_{1}) \\ E_{2}*S_{2}(1-S_{2}) \\ E_{k}*S_{k}(1-S_{k}) \\ \cdots \\ \end{matrix} \right) \cdot \left( \begin{matrix} o_{1} & o_{2} & o_{j} & \cdots \end{matrix} \right)
⎝⎜⎜⎛Δw1,1Δw1,2Δw1,3⋯Δw2,1Δw2,2Δw2,3⋯Δw3,1Δw3,2Δwj,k⋯⋯⋯⋯⋯⎠⎟⎟⎞=⎝⎜⎜⎛E1∗S1(1−S1)E2∗S2(1−S2)Ek∗Sk(1−Sk)⋯⎠⎟⎟⎞⋅(o1o2oj⋯)
权重更新矩阵有如下的矩阵形式,这种形式可以让我们通过计算机编程语言高效地实现矩阵运算。
Δ
w
j
,
k
=
α
⋅
E
k
⋅
O
k
(
1
−
O
k
)
⋅
O
j
T
\Delta w_{j,k}=\alpha \cdot E_{k} \cdot O_{k}(1-O_{k}) \cdot O_{j}^{T}
Δwj,k=α⋅Ek⋅Ok(1−Ok)⋅OjT
使用Python制作神经网络
1.框架代码
有三个函数:
(1)初始化函数——设定输入层节点、隐藏层节点和输出层节点的数量。
(2)训练——学习给定训练集样本后,优化权重。
(3)查询——给定输入,从输出节点给出答案。
# neural network class definition
class neuralNetwork:
# initialise the neural network
def __init__():
pass
# train the neural network
def train():
pass
# query the neural network
def query():
pass
2.初始化网络
优秀的程序员、计算机科学家和数学家,只要可能,都尽力创建一般代码,而不是具体的代码。如果能做到这点,就意味着我们的解决方案可以适用于不同的场景。让我们看看__init __()函数是什么样子的:
# neural network class definition
class neuralNetwork:
# initialise the neural network
def __init__(self , inputnodes, hiddennodes, outputnodes, learningrate):
# set number of nodes in each input, hidden, output layer
self . inodes = inputnodes
self . hnodes = hiddennodes
self . onodes = outputnodes
# learning rate
self . lr = learningrate
pass
3.权重—-网络的核心
网络中最重要的部分是链接权重,我们使用这些权重来计算前馈信号、反向传播误差,并且在试图改进网络时优化链接权重本身。使用正态概率分布采样权重,其中平均值为0,标准方差为节点传入链接数目的开方,即 1 / ( 传 入 链 接 数 目 ) 1/\sqrt{(传入链接数目)} 1/(传入链接数目)下面是实现了神经网络的心脏——链接权重矩阵。
# neural network class definition
class neuralNetwork:
# initialise the neural network
def __init__(self , inputnodes, hiddennodes, outputnodes, learningrate):
# set number of nodes in each input, hidden, output layer
self . inodes = inputnodes
self . hnodes = hiddennodes
self . onodes = outputnodes
# link weight matrices, wih and who
# weights inside the arrays are w_i_j, where link is from node i to node j in the next layer
# w11 w21
# w12 w22 etc
# self.wih = (numpy.random.rand(self.hnodes, self.inodes) - 0.5)
# self.who = (numpy.random.rand(self.onodes, self.hnodes) - 0.5)
self.wih = np.random.normal(0.0, pow(self.hnodes, -0.5), (self.hnodes, self.inodes))
self.who = np.random.normal(0.0, pow(self.onodes, -0.5), (self.onodes, self.hnodes))
# learning rate
self . lr = learningrate
pass
4.查询网络
# initialise the neural network
def __init__(self , inputnodes, hiddennodes, outputnodes, learningrate):
# activation function is the sigmoid function
self.activation_function = lambda x: np.array([1/(1 + math.exp(-z)) for z in x], ndmin=2).T
pass
# query the neural network
def query(self, inputs_list):
# convert inputs list to 2d array
inputs = np.array(inputs_list, ndmin=2).T
# calculate signals into hidden layer
hidden_inputs = np.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
final_inputs = np.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
final_outputs = self.activation_function(final_inputs)
return final_outputs
5.训练网络
# train the neural network
def train(self, inputs_list, targets_list):
# convert inputs list to 2d array
inputs = numpy.array(inputs_list, ndmin=2).T
targets = numpy.array(targets_list, ndmin=2).T
# calculate signals into hidden layer
hidden_inputs = numpy.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
final_inputs = numpy.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
final_outputs = self.activation_function(final_inputs)
pass
现在,接近神经网络工作的核心,即基于所计算输出与目标输出之间的误差,改进权重。首先需要计算误差,这个值等于训练样本所提供的预期目标输出值与实际计算得到的输出值之差。这个差也就是将矩阵targets和矩阵final_outputs中每个对应元素相减得到的。
# error is the (target - actual)
output_errors = targets - final_outputs
e
r
r
o
r
s
h
i
d
d
e
n
=
w
e
i
g
h
t
s
h
i
d
d
e
n
o
u
t
p
u
t
T
⋅
e
r
r
o
r
s
o
u
t
p
u
t
errors_{hidden}=weights_{hidden_output}^{T} \cdot errors_{output}
errorshidden=weightshiddenoutputT⋅errorsoutput
根据所连接的权重分割误差,为每个隐藏层节点重组这些误差
# hidden layer error is the output_errors, split by weights, recombined at hidden nodes
hidden_errors = numpy.dot(self.who.T, output_errors)
这样,我们就拥有了所需要的一切,可以优化各个层之间的权重了。对于在隐蔽层和最终层之间的权重,我们使用output_errors进行优化。对于输入层和隐藏层之间的权重,我们使用刚才计算得到的hidden_errors进行优化。
先前,我们得到了用于更新节点j与其下一层节点k之间链接权重的矩阵形式的表达式:
Δ
w
j
,
k
=
α
∗
E
k
∗
O
k
∗
(
1
−
O
k
)
⋅
O
j
T
\Delta w_{j,k}=\alpha \ast E_{k} \ast O_{k} \ast (1-O_{k}) \cdot O_{j}^{T}
Δwj,k=α∗Ek∗Ok∗(1−Ok)⋅OjT
α是学习率,*乘法是正常的对应元素的乘法,•点乘是矩阵点积。最后一点要注意,来自上一层的输出矩阵被转置了。
首先为隐藏层和最终层之间的权重进行编码。
# update the weights for the links between the hidden and output layers
self.who += self.lr * np.dot((output_errors * final_outputs * (1.0 - final_outputs)), np.transpose(hidden_outputs))
用于输入层和隐藏层之间权重的代码也是类似的。我们只是利用对称性,重写代码,更换名字,这样它们指的就是神经网络的前一层了。
# update the weights for the links between the input and hidden layers
self. wih += self.lr * numpy.dot(( hidden_errors * hidden_outputs * (1.0 - hidden_outputs)), numpy.transpose(inputs))
6.完整的神经网络代码
import numpy as np
import math
# neural network class definition
class neuralNetwork:
# initialise the neural network
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
# set number of nodes in each input, hidden, output layer
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
# link weight matrices, wih and who
# weights inside the arrays are w_i_j, where link is from node i to node j in the next layer
# w11 w21
# w12 w22 etc
self.wih = np.random.normal(0.0, pow(self.hnodes, -0.5), (self.hnodes, self.inodes))
self.who = np.random.normal(0.0, pow(self.onodes, -0.5), (self.onodes, self.hnodes))
# learning rate
self.lr = learningrate
# activation function is the sigmoid function
self.activation_function = lambda x: np.array([1/(1 + math.exp(-z)) for z in x], ndmin=2).T
pass
# training the neural network
def train(self, inputs_list, targets_list):
# convert inputs list to 2d array
inputs = np.array(inputs_list, ndmin=2).T
targets = np.array(targets_list, ndmin=2).T
# calculate signals into hidden layer
hidden_inputs = np.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
final_inputs = np.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
final_outputs = self.activation_function(final_inputs)
# error is the (target - actual)
output_errors = targets - final_outputs
# hidden layer error is the output_errors, split by weights, recombined at hidden nodes
hidden_errors = np.dot(self.who.T, output_errors)
# update the weights for the links between the hidden and output layers
self.who += self.lr * np.dot((output_errors * final_outputs * (1.0 - final_outputs)),
np.transpose(hidden_outputs))
# update the weights for the links between the input and hidden layers
self.wih += self.lr * np.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)),
np.transpose(inputs))
pass
# query the neural network
def query(self, inputs_list):
# convert inputs list to 2d array
inputs = np.array(inputs_list, ndmin=2).T
# calculate signals into hidden layer
hidden_inputs = np.dot(self.wih, inputs)
# calculate the signals emerging from hidden layer
hidden_outputs = self.activation_function(hidden_inputs)
# calculate signals into final output layer
final_inputs = np.dot(self.who, hidden_outputs)
# calculate the signals emerging from final output layer
final_outputs = self.activation_function(final_inputs)
return final_outputs
7.在手写数字的数据集MNIST上运行神经网络
fileintrain = r"H:\深度学习\data\mnist_train.csv"
fileintest = r"H:\深度学习\data\mnist_test.csv"
# number of input, hidden and output nodes
input_nodes = 784
hidden_nodes = 100
output_nodes = 10
# learning rate is 0.3
learning_rate = 0.2
# create instance of neural network
n = neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate)
# load the mnist training data CSV file into a list
training_data_file = open(fileintrain)
training_data_list = training_data_file.readlines()
training_data_file.close()
# train the neural network
# go through all records in the training data set
for record in training_data_list:
# split the record by the ',' commas
all_values = record.split(',')
# scale and shift the inputs
inputs = (np.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
# create the target output values (all 0.01, except the desired label which is 0.99)
targets = np.zeros(output_nodes) + 0.01
# all_values[0] is the target label for this record
targets[int(all_values[0])] = 0.99
n.train(inputs, targets)
pass
# load the mnist test data CSV file into a list
test_data_file = open(fileintest)
test_data_list = test_data_file.readlines()
test_data_file.close()
# test the neural network
# scorecard for how well the network performs, initially empty
scorecard = []
# go through all the records in the test data set
for record in test_data_list:
# split the record by the ',' commas
all_values = record.split(',')
# correct answer is first value
correct_label = int(all_values[0])
print(correct_label, "correct label")
# scale and shift the inputs
inputs = (np.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
# query the network
outputs = n.query(inputs)
# the index of the highest value corresponds to the label
label = np.argmax(outputs)
print(label, "network's answer")
# append correct or incorrect to list
if label == correct_label:
# network's answer matches correct answer, add 1 toscorecard
scorecard.append(1)
else:
# network's answer doesn't match correct answer, add 0 to scorecard
scorecard.append(0)
pass
pass
# calculate the performance score, the fraction of correct answers
scorecard_array = np.asarray(scorecard)
print("performance = ", scorecard_array.sum() / scorecard_array.size)
为什么选择784个输入节点呢?请记住,这是28×28的结果,即组成手写数字图像的像素个数。
选择使用100个隐藏层节点并不是通过使用科学的方法得到的。我们认为,神经网络应该可以发现在输入中的特征或模式,这些模式或特征可以使用比输入本身更简短的形式表达,因此没有选择比784大的数字。通过选择使用比输入节点的数量小的值,强制网络尝试总结输入的主要特点。但是,如果选择太少的隐藏层节点,那么就限制了网络的能力,使网络难以找到足够的特征或模式,也就会剥夺神经网络表达其对MNIST数据理解的能力。给定的输出层需要10个标签,对应于10个输出层节点,因此,选择100这个中间值作为中间隐藏层的节点数量,似乎有点道理。
这里应该强调一点。对于一个问题,应该选择多少个隐藏层节点,并不存在一个最佳方法。同时,我们也没有最佳方法选择需要几层隐藏层。就目前而言,最好的办法是进行实验,直到找到适合你要解决的问题的一个数字。
7.1 一些改进:调整学习率
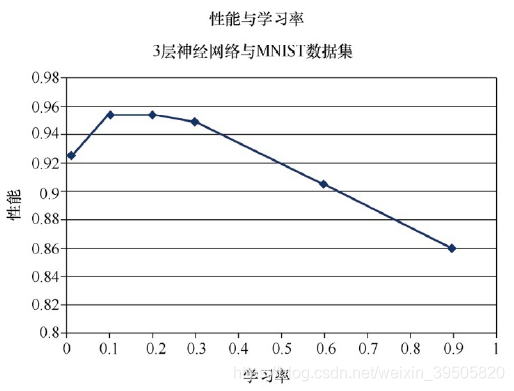
使用的步长太小了,限制了梯度下降发生的速度,对性能造成了损害;使用步长太大,无法到达谷底;所以这个结果也是有道理的。对于学习率存在一个甜蜜点。
7.2 一些改进:多次运行
使用数据集,重复多次进行训练。
有些人把训练一次称为一个世代。因此,具有10个世代的训练,意味着使用整个训练数据集运行程序10次。为什么要这么做呢?特别是,如果这次计算机花的时间增加到10或20甚至30分钟呢?这是值得的,原因是通过提供更多爬下斜坡的机会,有助于在梯度下降过程中进行权重更新。
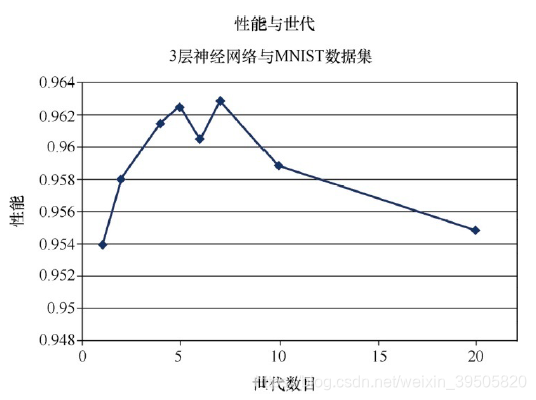
直觉告诉我们,所做的训练越多,所得到的性能越好。有人可能会注意到,太多的训练实际上会过犹不及,这是由于网络过度拟合训练数据,因此网络在先前没有见到过的新数据上表现不佳。不仅是神经网络,在各种类型的机器学习中,这种过度拟合也是需要注意的。
结果呈现出不可预测性。在大约5或7个世代时,有一个甜蜜点。在此之后,性能会下降,这可能是过度拟合的效果。性能在6个世代的情况下下降,这可能是运行中出了问题,导致网络在梯度下降过程中被卡在了一个局部的最小值中。事实上,由于没有对每个数据点进行多次实验,无法减小随机过程的影响,因此我们已经预见到结果会有各种变化。这就是为什么保留了6个世代这个奇怪的点,这是为了提醒我们,神经网络的学习过程其核心是随机过程,有时候工作得不错,有时候工作得很糟。
另一个可能的原因是,在较大数目的世代情况下,学习率可能设置过高了。继续这个实验,将学习率从0.2减小到0.1,看看会发生什么情况。
下图显示了在学习率为0.1情况下,得到的新性能与前一幅图叠加的情况。
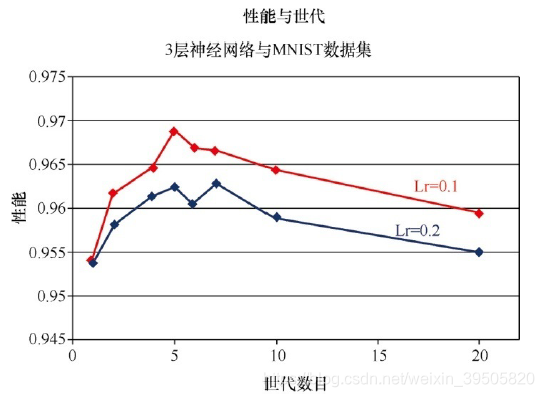
可以看到,在更多世代的情况下,减小学习率确实能够得到更好的性能。0.9689的峰值表示误差率接近3%,这可以与Yann LeCun网站上的神经网络标准相媲美了。
直观上,如果你打算使用更长的时间(多个世代)探索梯度下降,那么你可以承受采用较短的步长(学习率),并且在总体上可以找到更好的路径,这是有道理的。确实,对于MNIST学习任务,我们的神经网络的甜蜜点看起来是5个世代。请再次记住,我们在使用一种相当不科学的方式来进行实验。要正确、科学地做到这一点,就必须为每个学习率和世代组合进行多次实验,尽量减少在梯度下降过程中随机性的影响。
7.3 一些改进:改变网络形状
我们还没有尝试过改变神经网络的形状,也许应该更早尝试这件事。让我们试着改变中间隐藏层节点的数目。一直以来,我们将它们设置为100!
在尝试使用不同数目的隐藏层节点进行实验之前,让我们思考一下,如果这样做可能会发生什么情况。隐藏层是发生学习过程的层次。请记住,输入节点只需引入输入信号,输出节点只要送出神经网络的答案,是隐藏层(可以多层)进行学习,将输入转变为答案。这是学习发生的场所。事实上,隐藏层节点前后的链接权重具有学习能力。
如果隐藏层节点太少,比如说3个,那么你可以想象,这不可能有足够的空间让网络学习任何知识,并将所有输入转换为正确的输出。这就像要5座车去载10个人。你不可能将那么多人塞进去。计算机科学家称这种限制为学习容量。虽然学习能力不可能超过学习容量,但是可以通过改变车辆或网络形状来增加容量。
如果有10 000个隐藏层节点,会发生什么情况呢?虽然我们不会缺少学习容量,但是由于目前有太多的路径供学习选择,因此可能难以训练网络。这也许需要使用10 000个世代来训练这样的网络。
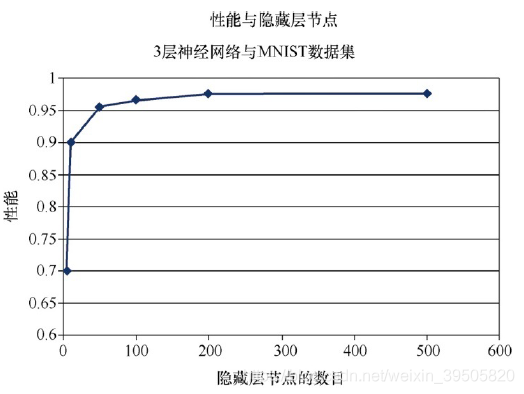
可以看到,比起较多的隐藏层节点,隐藏层节点数量少,其效果不是很理想,这是我们预期的结果。但是,只有5个隐藏层节点的神经网络,其性能得分就可以达到0.7001,鉴于只给了如此少的学习场所,而网络仍有70%的正确率,这已经相当惊人了。
请记住,迄今为止,程序运行的是100个隐藏层节点。只用10个隐藏层节点,网络就得到了0.8998的准确性,这同样让人侧目。只使用我们曾经用过的节点数目的1/10,网络的性能就跳到90%。只使用如此少的隐藏层节点或学习场所,神经网络就能够得到如此好的结果。这也证明了神经网络的力量。这一点值得我们赞赏。
随着增加隐藏层节点的数量,结果有所改善,但是不显著。由于增加一个隐藏层节点意味着增加了到前后层的每个节点的新网络链接,这一切都会产生额外较多的计算,因此训练网络所用的时间也显著增加了!因此,必须在可容忍的运行时间内选择某个数目的隐藏层节点。

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









