







Paper Card
论文标题:Open X-Embodiment: Robotic Learning Datasets and RT-X Models
论文作者:–
论文原文:https://arxiv.org/abs/2310.08864
论文出处:–
论文被引:–(12/18/2023)
论文代码:https://github.com/google-deepmind/open_x_embodiment
项目主页:https://robotics-transformer-x.github.io/
Abstract
在不同数据集上训练的大型高容量模型在高效处理下游应用方面取得了显著的成功。在从 NLP 到计算机视觉等领域,这导致了预训练模型的整合,通用预训练骨干成为许多应用的起点。机器人技术能否实现这种整合?传统的机器人学习方法是为每种应用、每个机器人甚至每个环境训练一个单独的模型。能否训练出通用型的 X-Robot 策略,使其能有效地适应新的机器人、任务和环境?本文提供了标准化数据格式和模型的数据集,以便在机器人操作的背景下探索这种可能性,同时还提供了有效 X-Robot 策略的实验结果。汇集了 21 家机构合作收集的 22 种不同机器人的数据集,展示了 527 种技能(160266 项任务)。研究表明,在这些数据基础上训练出来的大容量模型 RT-X 可以利用来自其他平台的经验,实现正迁移并提高多个机器人的能力。
Summary

研究背景
通常在大型、多样化数据集上训练的大规模通用模型,其性能往往优于在较小但更具任务针对性的数据集上训练的模型。越来越多的情况是,处理特定狭窄任务的最有效方法是微调通用模型。然而,这些经验很难应用到机器人领域:任何单一的机器人领域都可能过于狭窄,虽然计算机视觉和 NLP 可以利用从网络上获取的大型数据集,但机器人交互领域却很难获得类似的大型、广泛数据集。这些数据集在某些变化轴上仍然很狭窄,要么只关注单一环境、单一物体集,要么只关注狭窄的任务范围。如何才能克服机器人学中的这些挑战,将机器人学习领域推向在其他领域取得巨大成功的那种大数据体系?
方法介绍
受在不同数据上对大型视觉或语言模型进行预训练可实现通用化的启发, 训练通用的机器人策略这一目标需要进行 X-embodiment 训练,即挖掘来自许多实验室、多个机器人平台和不同环境的数据,所有这些数据集的联合能更好地覆盖环境和机器人的变化。即使这些数据集目前的规模和覆盖范围不足以达到大型语言模型所展示的令人印象深刻的泛化结果,但在未来,这些数据的联合有可能提供这种覆盖范围。
工作有两个主要目标:
- 1)证明根据来自多个不同机器人和环境的数据训练的策略可以实现正向增益,比仅根据来自每个评估设置的数据训练的策略获得更好的性能。
- 2)为机器人界提供数据集、数据格式和模型,以促进未来对 X-embodiment 模型的研究。
工作重点是 机器人操作(robotic manipulation)。
- 针对目标 1),证明了最近的几种机器人学习方法,只需极少的修改,就能利用 X-embodiment 数据并实现正迁移。具体来说,在 9 个不同的机器人操纵器上训练 RT-1 [8] 和 RT-2 [9] 模型。结果表明,RT-X 的模型可以改进仅在评估域数据上训练的策略,表现出更好的泛化能力和新功能。
- 针对目标 2),提供了 Open X-embodiment(OXE),其中包括一个数据集,包含来自 21 个不同机构的 22 种不同的机器人装置,可以帮助机器人社区进一步研究 X-embodiment 模型,并提供开源工具以促进此类研究。目标不是在特定架构和算法方面进行创新,而是提供训练的模型以及数据和工具,方便研究者们围绕OXE展开研究。
相关工作
Transfer across embodiments
之前对跨机器人本体迁移方法的研究,通常引入了专门用于解决不同机器人之间差距的机制,例如:
- 共享动作表示[14, 30]
- 纳入表示学习目标[17, 26]
- 根据具身信息调整学习策略[11, 15, 18, 30, 31]
- 解耦机器人和环境表示[24]
之前的工作已经初步展示了 X-embodiment 训练 [27] 和 Transformer 模型的迁移 [25, 29, 32]。同样,用于在人类和具身机器人之间迁移的方法也经常采用减少具身差距(embodiment gap)的技术,即通过领域间转换或学习可迁移表征[33-43]。一些研究还关注问题的子方面,如从人类视频数据中学习可迁移的奖励函数 [17, 44-48],目标 [49, 50],动力学模型 [51] 或视觉表征 [52-59]。
与之前的大多数研究不同,直接在 X-embodiment 数据上训练策略,而不使用任何机制来减少具身差距,并通过利用这些数据观察到正向的迁移。
Large-scale robot learning datasets
机器人学习社区已经创建了开源机器人学习数据集,OXE 的目标是:将大量先前的数据集进行处理并汇总到一个单一、标准化的资源库中,名为 Open X-Embodiment。
Language-conditioned robot learning
先前的研究旨在赋予机器人和其他智能体理解并遵循语言指令的能力[96-101],通常是通过学习语言条件策略[8, 40, 45, 102-106]。我们通过模仿学习来训练语言条件策略,这与之前的许多研究一样,但使用的是大规模多实验演示数据。
Open X-Embodiment
Open X-Embodiment 资源库,包括用于 X-embodied 机器人学习研究的大规模数据和预训练模型检查点。更具体地说,为更广泛的社区提供并维护以下开源资源:
- Open X-Embodiment Dataset:机器人学习数据集,包含来自 22 个机器人实验的 100 多万条机器人轨迹
- Pre-Trained Checkpoints:精选的 RT-X 模型检查点,可用于推理和微调
Dataset Information
Open X-Embodiment 实验数据集包含 100 多万条真实机器人轨迹,涵盖 22 种机器人实验,从单臂机器人到双臂机器人和四足机器人。该数据集是通过汇集来自全球 34 个机器人研究实验室的 60 个现有机器人数据集而构建的,并将其转换为统一的数据格式,以方便下载和使用。使用 RLDS 数据格式 [119],它以序列化的 tf-record 文件保存数据,可适应不同机器人设置的各种动作空间和输入模式,如不同数量的 RGB 摄像头,深度摄像头和点云。它还支持所有主要深度学习框架的高效并行数据加载。
Dataset Analysis
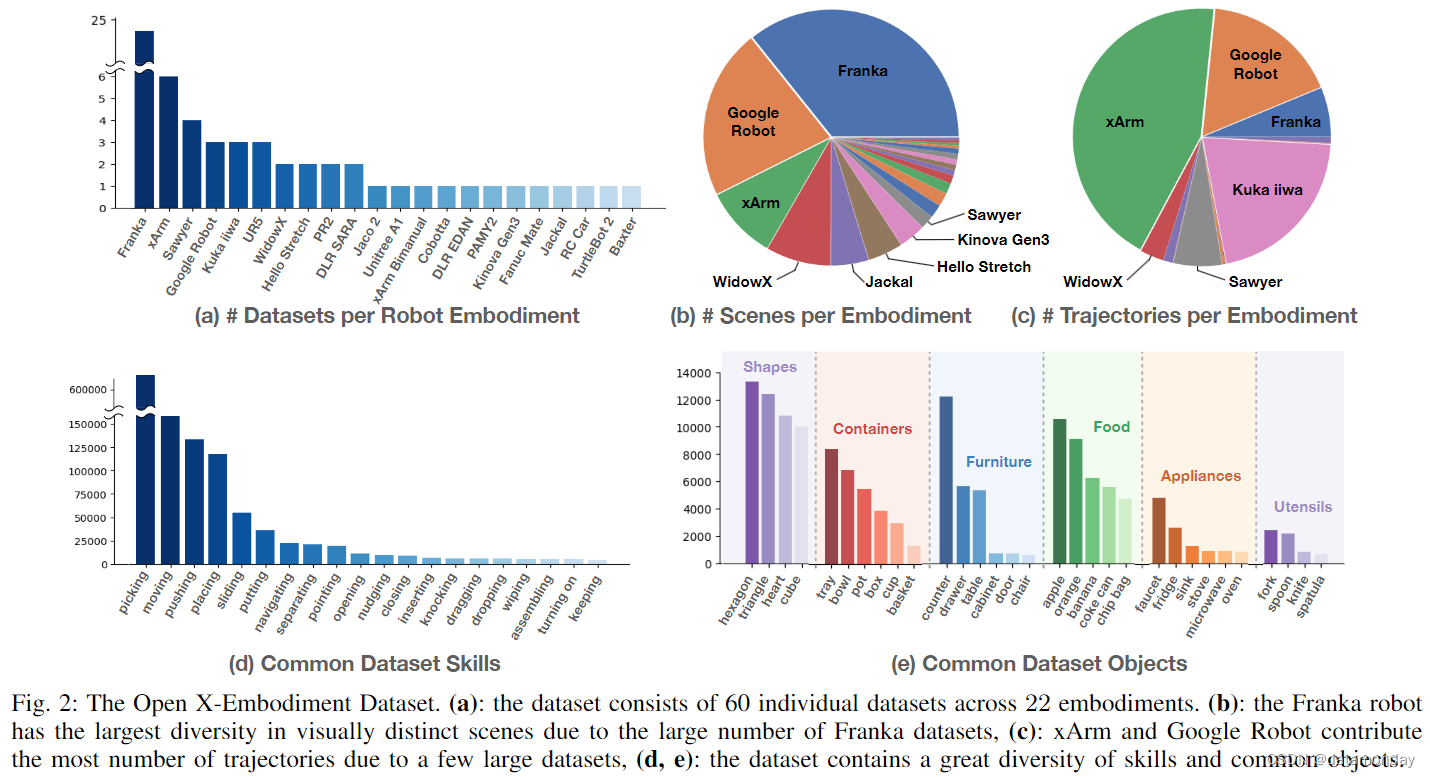
图 2(a) 显示了按机器人本体区分的数据集,其中 Franka 最常见。图 2(b) 显示了机器人采集场景分布,其中 Franka 最常见。图 2© 显示了每个机器人本体的轨迹分类。为了进一步分析多样性,使用 PaLM 语言模型 [3] 从语言指令中提取物体和行为,图 2(d,e) 显示了技能和物体的多样性。虽然大多数技能属于拾取-放置系列,但数据集的长尾部分包含了 “擦拭” 或 “组装” 等技能。此外,数据还涵盖了从家用电器到食品和器皿等一系列家用物品。
模型架构
为了评估 X-embodiment 训练能在多大程度上提高所学策略在单个机器人上的性能,需要模型有足够的能力来有效利用这种大型异构数据集。为此,以基于 Transformer 的机器人策略为基础:RT1 [8] 和 RT-2 [9]。
Data format consolidation
创建 X-embodiment 模型的一个挑战是,不同机器人的观察和行动空间差异很大。在不同的数据集中使用粗略对齐的动作和观察空间。该模型接收近期图像和语言指令的历史记录作为观察结果,并预测一个控制末端执行器的 7 维动作向量(x,y,z,roll,pitch,yaw,gripper opening or the rates of these quantities)。从每个数据集中选择一个典型的相机视图作为输入图像,将其调整为通用分辨率,然后将原始动作集转换为 7 DoF 末端执行器动作。在离散化之前,对每个数据集的动作进行归一化处理。这样一来,模型的输出结果就可以根据所使用的机器人本体进行不同的反归一化操作。尽管进行了粗对齐,但不同数据集的摄像头观测结果仍有很大差异,例如,由于摄像头相对于机器人的位置不同,或者摄像头的属性不同,见图 3。同样,对于动作空间,不会在控制末端执行器的数据集之间对坐标框架进行对齐,而是允许动作值代表绝对或相对位置或速度,跟每个机器人最初选择的控制方案一样。因此,相同的动作矢量对不同的机器人可能会产生截然不同的运动。
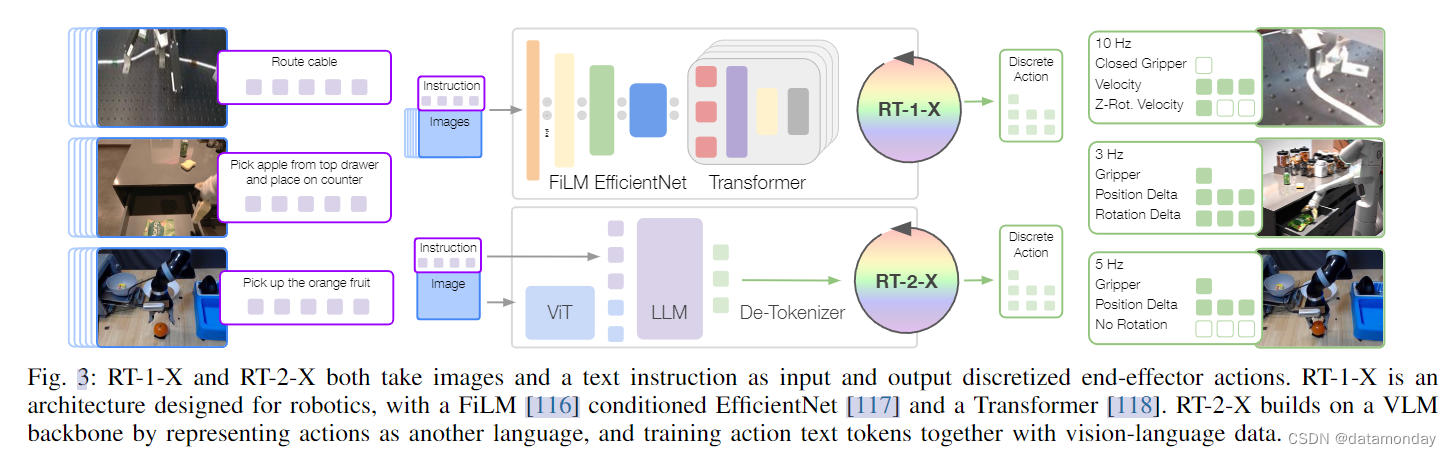
Policy architectures
在实验中考虑了两种模型架构:
- 1)RT-1 [8],一种基于 Transformer 的高效架构,专为机器人控制而设计;
- 2)RT-2 [9],一种大型视觉语言模型,经过共同微调,可将机器人动作输出为自然语言标记。
这两个模型都接收视觉输入和描述任务的自然语言指令,并输出标记化的动作。对于每种模型,动作都被标记为 256 个bins,沿 8 个维度均匀分布;1个维度用于终止episode,7个维度用于末端执行器运动
- RT-1 [8] 是一个基于 Transformer 架构 [118] 的 35M 参数网络,设计用于机器人控制,如图 3 所示。它接收 15 幅图像和自然语言的历史记录。每幅图像都会通过经过 ImageNet 训练的 EfficientNet 进行处理,自然语言指令则会转换为 USE 嵌入。然后,视觉和语言表征通过 FiLM 层交织在一起,产生 81 个视觉语言标记。这些标记被送入解码器 Transformer,输出标记化的动作。
- RT-2 [9]是一个大型视觉-语言-动作模型(VLA)系列,它是在互联网规模的视觉和语言数据以及机器人控制数据的基础上训练而成的。RT-2 将标记化动作(tokenized actions)转换为文本标记(text tokens),例如,一个可能的动作可能是 “1 128 91 241 5 101 127”。因此,任何经过预训练的视觉语言模型都可以针对机器人控制进行微调,从而利用视觉语言模型的骨干并迁移其部分泛化特性。在这项工作中,重点研究 RT-2-PaLI-X 变体[121],它建立在视觉模型 ViT [124] 和语言模型 UL2 [125] 的基础上,主要在 WebLI [121] 数据集上进行预训练。
Training and inference details
这两个模型在其输出空间(RT-1 为离散桶,RT-2 为所有可能的语言标记)上都使用了标准的分类交叉熵目标。
所有实验中使用 9 个机械臂的数据:
- RT-1 [8]
- QT-Opt [66]
- Bridge [95]
- Task Agnostic Robot Play [126, 127]
- Jaco Play [128]
- Cable Routing [129]
- RoboTurk [86]
- NYU VINN [130]
- Austin VIOLA [131]
- Berkeley Autolab UR5 [132]
- TOTO [133]
- Language Table [91]
RT-1-X 仅根据上述定义的机器人混合数据进行训练,而 RT-2-X 则通过联合精细调整(类似于原始 RT-2 [9])进行训练,原始 VLM 数据和机器人混合数据的比例大致为一比一。推理时,每个模型以机器人所需的速率(3-10 Hz)运行,RT-1 在本地运行,RT-2 托管在云服务上并通过网络查询。
实验结果
三个问题:
- 1)在 X-embodiment 数据集上训练的策略能否有效地实现正迁移,从而在多个机器人上收集的数据上进行联合训练,提高训练任务的性能?
- 2)对来自多个平台和任务的数据进行联合训练是否能提高模型对新的、未见过的任务的泛化能力?
- 3)不同的设计维度(如模型大小、模型架构或数据集组成)对所产生策略的性能和泛化能力有何影响?
对 6 种不同的机器人进行了总计 3600 次评估试验。
In-distribution performance across different embodiments
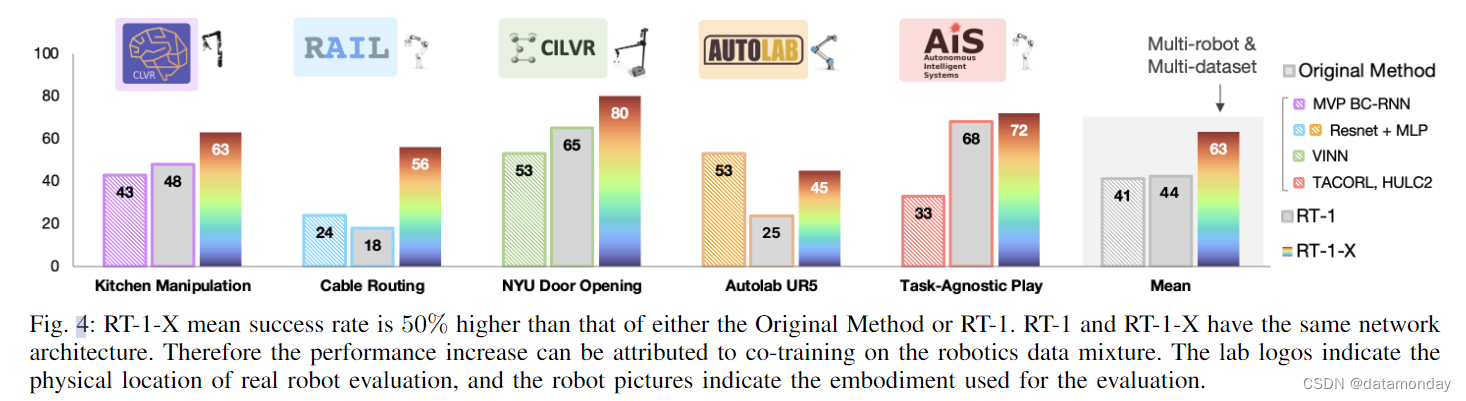
为了评估 RT-X 模型变体从 X-embodiment 数据中学习的能力,评估了它们在分布任务中的性能。将评估分为两类用例:
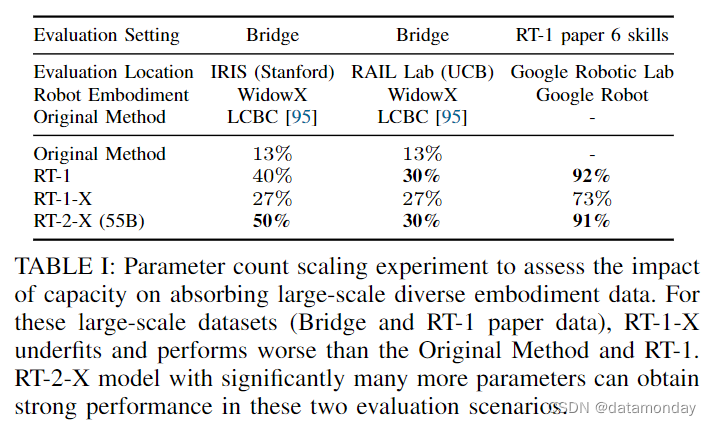
- 一类是对只有小规模数据集的领域进行评估(图 4),期望从更大规模数据集迁移数据能显著提高性能;
- 另一类是对拥有大规模数据集的领域进行评估(表 I),期望进一步提高性能更具挑战性。
- 在小规模数据集实验中,考虑了 Kitchen Manipulation [128]、Cable Routing [129]、NYU Door Opening [130]、AUTOLab UR5 [132] 和 Robot Play [134]。使用了与相关出论文中相同的评估和机器人。
- 在大规模数据集实验中,使用 Bridge [95] 和 RT-1 [8] 进行分布式评估,并使用它们各自的机器人:WidowX 和 Google Robot。
对于每个小型数据集域,比较 RT-1-X 模型的性能;对于每个大型数据集,同时考虑 RT-1-X 和 RT-2-X 模型。在所有实验中,模型都是在完整的 X-embodiment 数据集上共同训练的。在整个评估过程中,与两个基准模型进行了比较:
- 1)数据集创建者开发的模型,仅在该数据集上进行了训练。这构成了一个合理的基准,因为该模型已经过优化,可以很好地处理相关数据;将该基准模型称为原始方法模型。
- 2)在数据集上单独训练的 RT-1 模型;这一基线允许我们评估 RT-X 模型架构是否有足够能力同时代表多个不同机器人平台的策略,以及在多实验数据上进行联合训练是否会带来更高的性能。
在 5 个数据集中的 4 个数据集上,RT-1-X 的表现优于在每个机器人特定数据集上训练的原始方法,平均改进幅度较大,这表明数据有限的领域从 X-embodiment 数据的联合训练中获益匪浅。
在大规模数据集设置中,RT-1-X 模型的表现并不优于仅在特定化身数据集上训练的 RT-1 基线模型,这表明该模型类别拟合不足。不过,更大的 RT-2-X 模型的表现优于原始方法和 RT-1,这表明 X-robot训练可以提高数据丰富领域的性能,但前提是必须使用足够大容量的架构。
Improved generalization to out-of-distribution settings
现在,将研究 X-embodiment 训练如何能够更好地推广到分布外环境以及更复杂、更新颖的指令。这些实验侧重于高数据域,并使用 RT-2-X 模型。
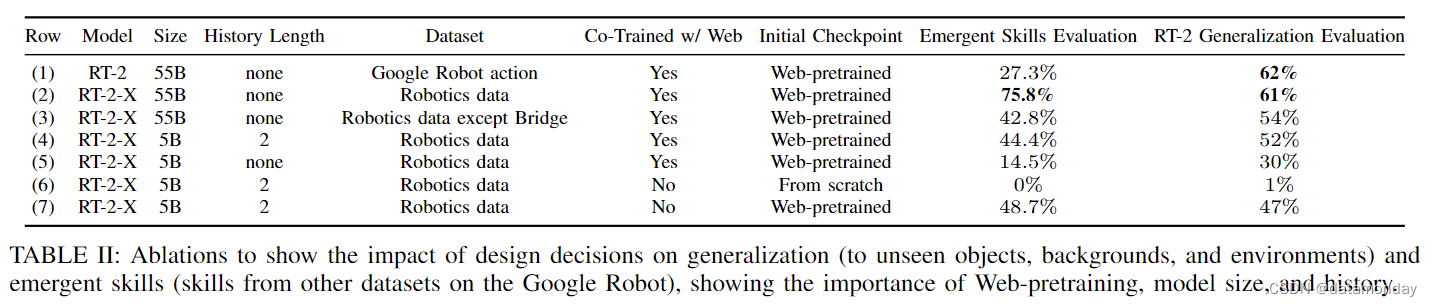
首先测试在未知环境和未知背景下操作未知物体的能力。RT-2 和 RT-2-X 的表现大致相当(表 II,第(1)(2)行,最后一列),因为 RT-2 在这些维度上的通用性已经很好([9]),这得益于其 VLM 骨干。
Emergent skills evaluation.
为了研究机器人之间的知识迁移,使用谷歌机器人进行了实验,评估其在图 5 所示任务中的表现。这些任务涉及的物体和技能在 RT-2 数据集中并不存在,但在不同机器人(WidowX-robot)的 Bridge 数据集中出现过[95]。结果如表 II 新兴技能评估一栏所示。比较第(1)行和第(2)行,RT-2-X 比 RT-2 高出 ∼ 3 倍,这表明,将其他机器人的数据纳入训练,即使机器人已经拥有大量可用数据,也能提高可执行任务的范围。使用其他平台的数据进行联合训练为 RT-2-X 控制器注入了该平台的额外技能,而这些技能在该平台的原始数据集中并不存在。
将 Bridge 数据集从 RT-2-X 训练中移除:第(3)行显示的是 RT-2-X 的结果,其中包括 RT-2-X 使用的所有数据,但 Bridge 数据集除外。这种变化大大降低了在保持任务上的性能,表明 WidowX 数据的迁移可能确实是 RT-2-X 与谷歌机器人一起执行额外技能的原因。
Design decisions
衡量不同设计决策对性能最好的 RT-2-X 模型的泛化能力的影响,结果如表 II 所示。包含短历史图像可显著提高泛化性能(第(4)行与第(5)行)。与 RT-2 论文[9]中的结论类似,基于网络的模型预训练对于大型模型实现高性能至关重要(第(4)行与第(6)行)。与 5B 模型相比(第(2)行与第(4)行),55B 模型在 “新兴技能” 项目中的成功率明显更高,这表明模型容量越大,跨机器人数据集的迁移程度就越高。与以前的 RT-2 研究结果相反,共同微调和微调在新兴技能和泛化评估中的表现相似(第(4)行与第(7)行),原因是 RT-2-X 中使用的机器人数据比以前使用的机器人数据集更加多样化。

实验结论
OXE数据集聚合了 21 家机构合作收集的 22 种机器人的数据,展示了 527 种技能(160266 项任务)。通过实验证明,在这些数据上训练出来的基于 Transformer 的策略可以在数据集中的不同机器人之间实现显著的正迁移。RT-1-X 策略的成功率比不同合作机构提供的最先进的原始方法高出 50%,而更大的基于视觉语言模型的版本(RT-2-X)与仅在评估体现数据上训练的模型相比,通用性提高了 ∼ 3 倍。此外,还为机器人社区提供了探索 X-embodiment 机器人学习研究的多种资源,包括:统一的 X-robot 和 X-institution 数据集、展示如何使用这些数据的示例代码,以及作为未来探索基础的 RT-1-X 模型。
局限性:
- 没有考虑具有截然不同的感知和执行模态的机器人
- 没有研究对新机器人的泛化
- 没有提供何时发生或不发生正向迁移的判定标准



















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











