






Nomic AI 发布开源多模态嵌入模型,多模态RAG正当时!
原创 ully AI工程化 2025年04月04日 12:04 北京
Nomic AI 近日发布了 Nomic Embed Multimodal 系列模型,这是一套开源的多模态嵌入模型,能够处理文本、图像、PDF 和图表等多种数据类型。该系列旨在提升对复杂文档的理解能力,并在视觉文档检索任务上取得了当前最佳(SOTA)性能。
本次发布的核心亮点包括:
- 原生多模态处理:模型能直接处理图像和文本内容,无需 OCR 或预处理步骤,有效捕捉文档布局、视觉元素、图表和结构信息,解决了传统模型仅依赖提取文本而丢失关键信息的痛点。
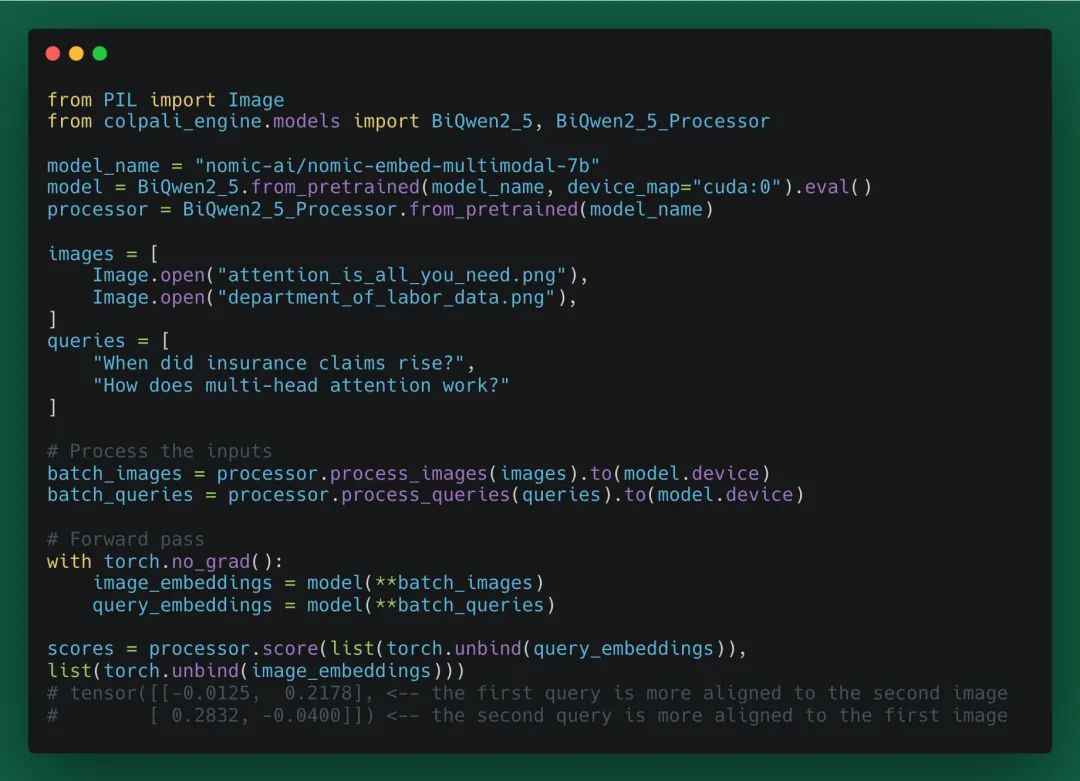
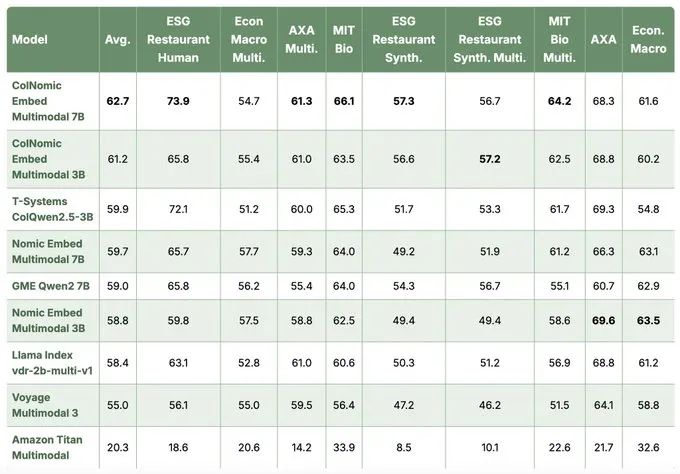
- SOTA 性能:在 Vidore-v2 视觉文档检索基准测试中,ColNomic Embed Multimodal 7B 模型的 NDCG@5 得分达到 62.7,较之前的 SOTA 提升了 2.8 个百分点。同时,Nomic Embed Multimodal 7B(密集向量模型)在单向量模型中表现领先。
- 模型多样性:发布了 7B 参数和 3B 参数两种规模的模型,每种规模均提供 Colbert (ColNomic) 和密集向量(dense)两种变体,以适应不同应用场景的需求。
- 完全开源:7B 模型遵循 Apache 2.0 许可证,3B 模型遵循 Qwen 2.5 许可证,并开放了模型权重、训练代码和训练数据,推动社区发展。
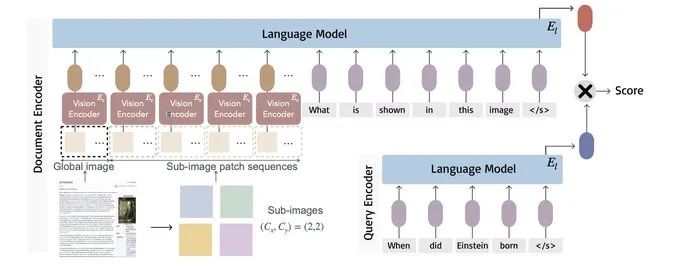
从技术角度看,Nomic Embed Multimodal 的创新在于其无需 OCR 的原生多模态处理能力。传统方法通常先提取文本,忽略了 PDF 和技术文档中重要的布局、图表等视觉信号。Nomic 的模型通过统一处理文本和图像信息,能够更全面地理解文档内容。Colbert 变体特别适用于需要精细化匹配的检索任务,而密集向量模型则提供通用的语义表示。
该技术的应用价值主要体现在增强处理复杂文档(如包含图表、图像的 PDF 和技术报告)的 RAG(检索增强生成)系统。通过更准确地理解和检索包含视觉信息的文档片段,可以显著提升信息检索的准确性和相关性,为金融分析、科研文献回顾、技术支持等领域带来更智能的解决方案。
社区反馈显示,该模型在代码检索等场景也表现出色。开发者 Michael Jentsch 表示:"在 Java 源代码 RAG 系统测试中,nomic-embed-code 模型表现近乎完美。"
Nomic AI 此次发布的开源模型,为开发者构建下一代文档理解和多模态检索应用提供了强大的基础工具。

















 4415
4415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









