






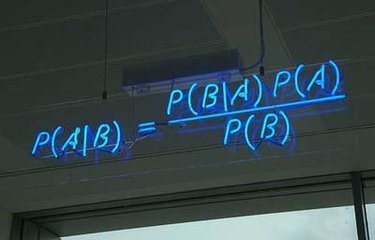
在推导逻辑回归的损失函数的过程中,我们希望让似然函数最大化。然而,最⼤大似然估计是统计学中的频率学派所推崇的估计方法,他们认为参数的值是亘古不变、独立地存在于世上的,他们的目的是通过已经观测到的数据去发现被隐藏起来的真实值。但在现实世界中,往往我们对参数是存在一定的先验知识的,而最大似然估计法则完全抛弃了这些先验知识,仅依靠观测数据做参数估计,因此很容易对数据形成过拟合,即在观测数据上表现非常好,但泛化能力很差。
与频率学派的观念不同,贝叶斯学派认为参数不是独立于世间万物的亘古不变的值,而是一个概率分布。即使在没有任何观测数据时,我们也知道参数服从某一个先验概率分布。当拥有越来越多的观测数据时,我们逐渐修正参数的概率分布,最终得到一个既能拟合观测数据,又符合我们先验假设的一个概率分布,从而一定程度上避免对观测数据形成过拟合。
贝叶斯学派的理论根基在于贝叶斯定理,基于贝叶斯定理发展而来的统计参数估计方法叫做最大后验估计(Maximum A Posterior estimation, MAP)。
贝叶斯定理:
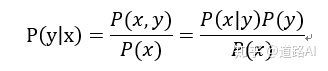
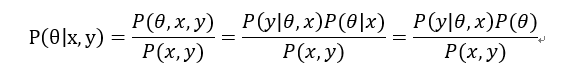
贝叶斯定理给出了在同时拥有观测数据和先验知识时,如何计算参数ϴ的概率分布的方法。下面我们的目的是最大化此概率分布的概率值。
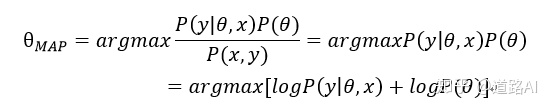
以上,我们推导出了最大后验估计的基本框架。下面我们要看到,当参数的先验分布分别是正态分布和拉普拉斯分布时,我们会得到怎样的损失函数?->公众号:灵隐杂谈















 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









