







(转载:上海交通大学计算机科学与工程系(CSE))
近期,上海交通大学计算机科学与工程系跨媒体语言智能实验室与苏州实验室的联合团队首次提出了一种面向化学材料领域的跨模态通用大模型 ChemDFM-X,在多项任务测试中性能表现卓越,相关成果在《中国科学:信息科学》(Science China Information Sciences)上发表。
文章来源: 文章链接

研究意义
构建跨模态化学材料大模型对于推动化学、材料及相关领域科研具有重要意义。材料科学本质上是一个多模态学科,其研究对象多样,数据形式也迥异,包括文本描述、分子结构、图像及光谱等多种类型。当前大多数人工智能模型主要聚焦于单一任务,输入数据通常限于单一模态,限制了此类模型在实际应用中的灵活性与泛化性。构建能够融合多种模态的大模型将有助于更全面地理解复杂的材料与化学体系,这类多模态大模型不仅能处理来自不同来源的数据,还能有效利用不同模态间的关系信息,从而加深对物质现象的理解。例如,结合分子结构信息与实验数据(如光谱)可更有效的设计实验、构建材料构效关系,甚至揭示传统方法可能忽略的新规律。
研究成果
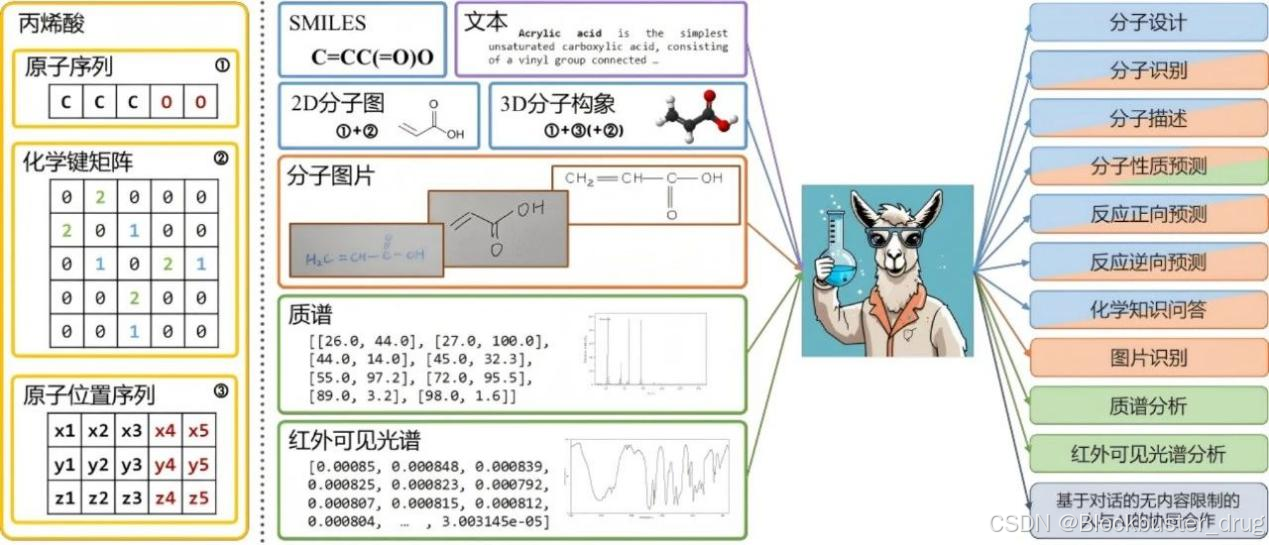
(图 1ChemDFM-X 概述。化学任务中涉及不同模态用颜色区分。结构模态用蓝色标记,图像用橙色标记,光谱用绿色标记。文本模态在输入中用紫色标记,在输出中省略。基于对话的自由形式人机协作可能涉及任何可实用的模态,用灰色标记)
跨模态化学材料大模型ChemDFM-X是研究团队在前期开源的通用化学材料大模型ChemDFM的基础上研发的,将模型只支持文本、SMILES模态扩展到支持更多的化学材料模态数据和任务类型。经过数百万多模态化学材料数据的对齐与微调,该模型能够理解文本、SMILES以及五种非文本形式的数据:二维分子结构、三维分子构象、分子或反应图片、质谱图和红外光谱图。
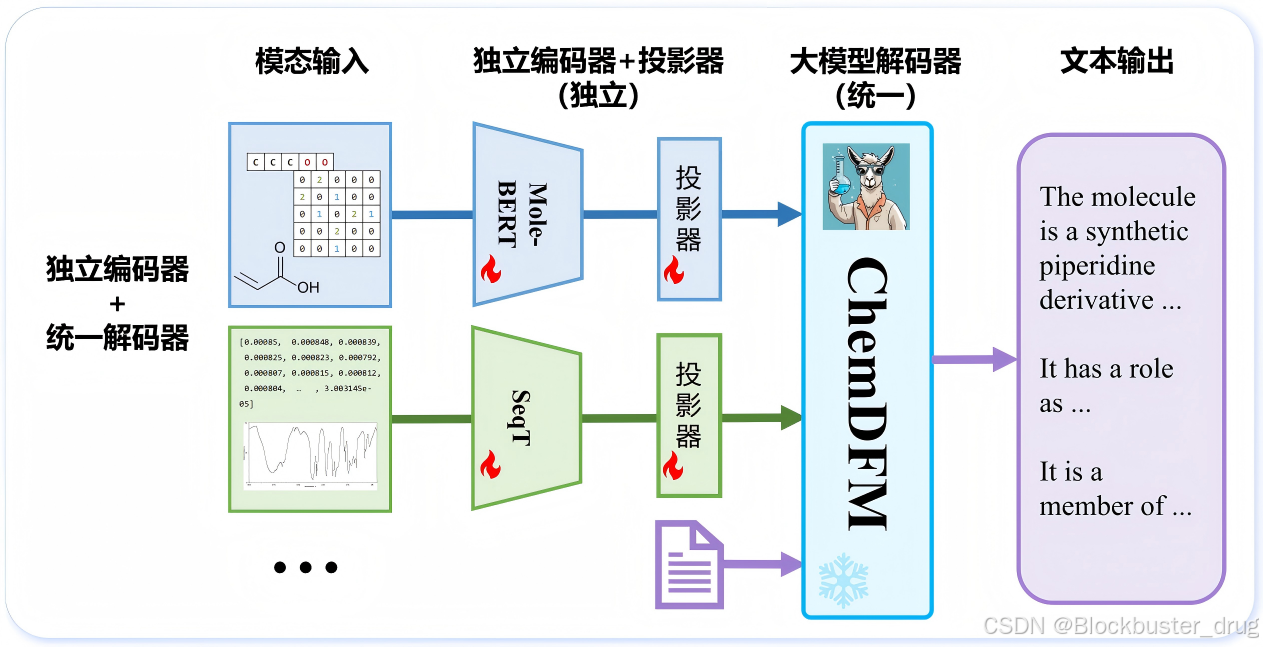 ChemDFM-X 模型架构
ChemDFM-X 模型架构
ChemDFM-X采用了独立编码器与统一解码器相结合的设计思路。首先对不同模态的编码器进行预训练,之后将其接入文本大模型中,并通过监督学习更新编码器及投影层的参数。在推理过程中,文本信息与其他模态的信息按照自然语言顺序混合输入到大模型中,由共享的大语言模型解码器负责信息整合与分析,使得同一组参数能够解释多种不同的物质科学数据模态。
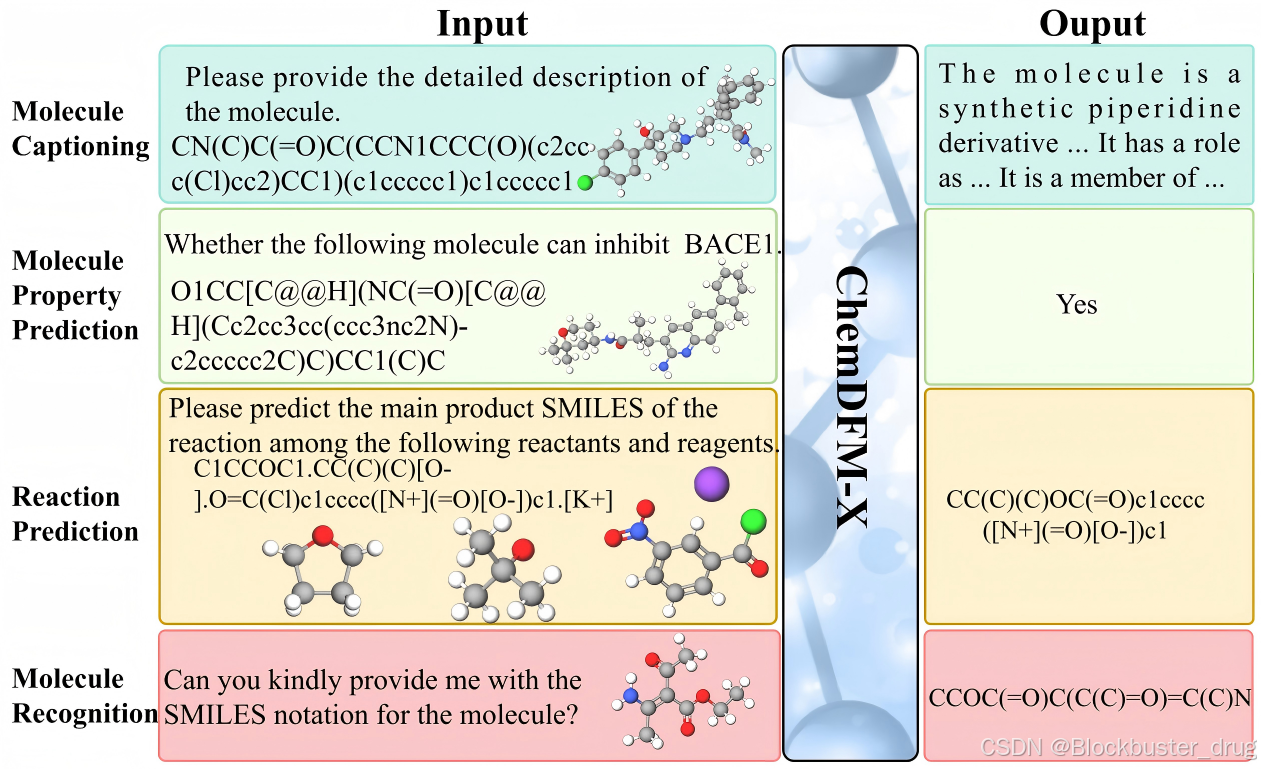
ChemDFM-X 应用示例
研究团队在不同任务、不同模态数据上评测了ChemDFM-X的跨模态理解与多任务支持能力。评测结果标明,ChemDFM-X通过有效整合多种模态的信息,大幅提高了大模型的泛化能力与整体性能。例如,ChemDFM-X能够理解并推断分子图和分子构象,在所有测试中表现均达到或超过了开源通用模型的最佳水平,尤其是当同时提供SMILES表示和3D分子构象时,ChemDFM-X的表现尤为优异。
Zihan Zhao, Bo Chen, Jingpiao Li, Lu Chen, Liyang Wen, Pengyu Wang, Zichen Zhu, Danyang Zhang, Yansi Li, Zhongyang Dai, Xin Chen & Kai Yu. ChemDFM-X: Towards Large Multimodal Model for Chemistry. Sci China Inf Sci, 2024, 67(12): 220109. (https://arxiv.org/abs/2409.13194)


















 1585
1585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











