







基于时间序列的预测,一定要明白它的原理,不是工作原理,而是工程落地原因。
基于时间序列,以已知回归未知----这两句话是分量很重的。
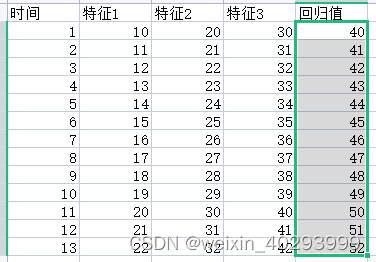
多因素单步单输出组合
时间序列:t=1 是 特征 1,2,3 预测t=2 的回归值41
多因素单步多输出组合
时间序列:t=1 是 特征 1,2,3 预测t=2 的回归值1 41 回归值2 xxxx
所以在看lstm git项目的时候,通常会有一个充足数据集的过程:
叫做 构造多元监督学习型数据
# 构造多元监督学习型数据
def split_sequences(sequences, n_steps):
X, y = list(), list()
for i in range(len(sequences)):
# 获取待预测数据的位置
end_ix = i + n_steps
# 如果待预测数据超过序列长度,构造完成
if end_ix > len(sequences)-1:
break
# 取前n_steps行数据的前5列作为输入X,第n_step行数据的最后一列作为输出y
seq_x, seq_y = sequences[i:end_ix, :5], sequences[end_ix, 5:]
X.append(seq_x)
y.append(seq_y)
return array(X), array(y)
实际就是完成数据的重新错位分配,
原始数据是
t1 的 feature1, feature2, feature3, feature4 和 y1在一列,
t2 的 feature1, feature2, feature3, feature4 和 y2在一列,
t3 的 feature1, feature2, feature3, feature4 和 y3在一列,
t4 的 feature1, feature2, feature3, feature4 和 y4在一列,
基于
3因素单步单输出组合 但经过这个函数 要改成
t1 的 feature1, feature2, feature3, feature4 和 y2在一列,
t2 的 feature1, feature2, feature3, feature4 和 y3在一列,
t3 的 feature1, feature2, feature3, feature4 和 y4在一列,
3因素2步单输出组合
[
[t1 的 feature1, feature2, feature3, feature4 ]、 [t2 的 feature1, feature2, feature3, feature4] , y3],在一列
[
[t2 的 feature1, feature2, feature3, feature4 ]、 [t3 的 feature1, feature2, feature3, feature4] , y4],在一列
理就是这么个理论,但是写出能实现 m因素n时间步长预测,p时间步长,q特征的回归并不太容易。
代码整理中,后续上传
------------------------------------------------------时间线---------------------------------------------------------------------------------
20231120 代码早就搞好了,忘了上传了 咳咳
# 导入必备库
from numpy import array
from numpy import hstack
import numpy as np
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
# 构造多元监督学习型数据
def split_sequences(sequences, n_steps):
X, y = list(), list()
for i in range(len(sequences)):
# 获取待预测数据的位置
end_ix = i + n_steps
# 如果待预测数据超过序列长度,构造完成
if end_ix > len(sequences)-1:
break
# 取前n_steps行数据的前5列作为输入X,第n_step行数据的最后一列作为输出y
seq_x, seq_y = sequences[i:end_ix, :5], sequences[end_ix, 5:]
X.append(seq_x)
y.append(seq_y)
return array(X), array(y)
读数据
data=pd.read_csv("./yy_5.csv")
data.head()
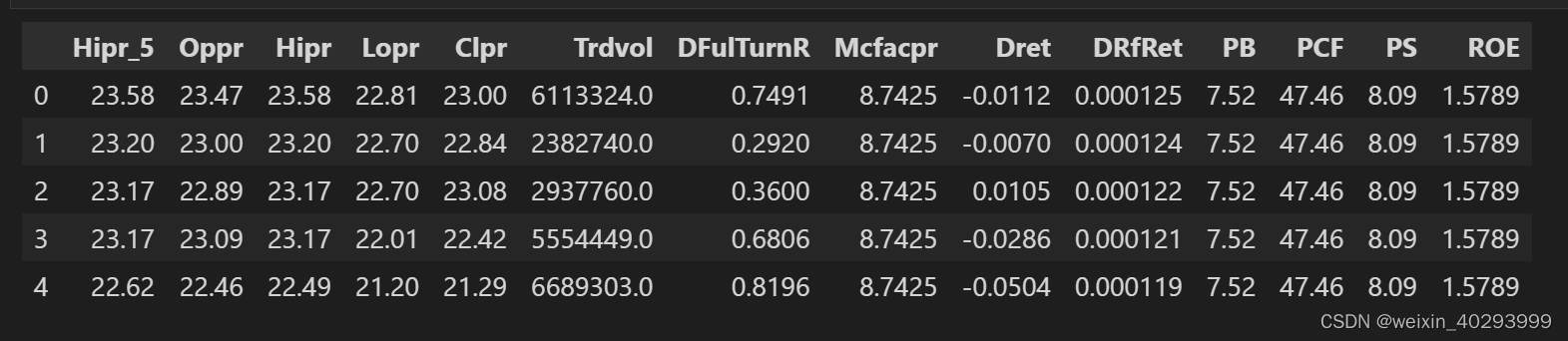
把无关的列清理调,调整列顺序
data.drop(columns=["DFulTurnR","Mcfacpr","Dret" ,"DRfRet","PB","PCF","PS","ROE"],inplace=True)
# 换一下列的顺序,看起来方便些
# 诉求:Hipr Lopr Clpr Trdvol-->Hipr_5,
# 前m天的4个特征,预测今天的1个特征Hipr_5
order = ['Oppr','Hipr', 'Lopr', 'Clpr', 'Trdvol','Hipr_5']
data = data[order]
data.head(5)
Oppr Hipr Lopr Clpr Trdvol Hipr_5
0 23.47 23.58 22.81 23.00 6113324.0 23.58
1 23.00 23.20 22.70 22.84 2382740.0 23.20
2 22.89 23.17 22.70 23.08 2937760.0 23.17
3 23.09 23.17 22.01 22.42 5554449.0 23.17
4 22.46 22.49 21.20 21.29 6689303.0 22.62
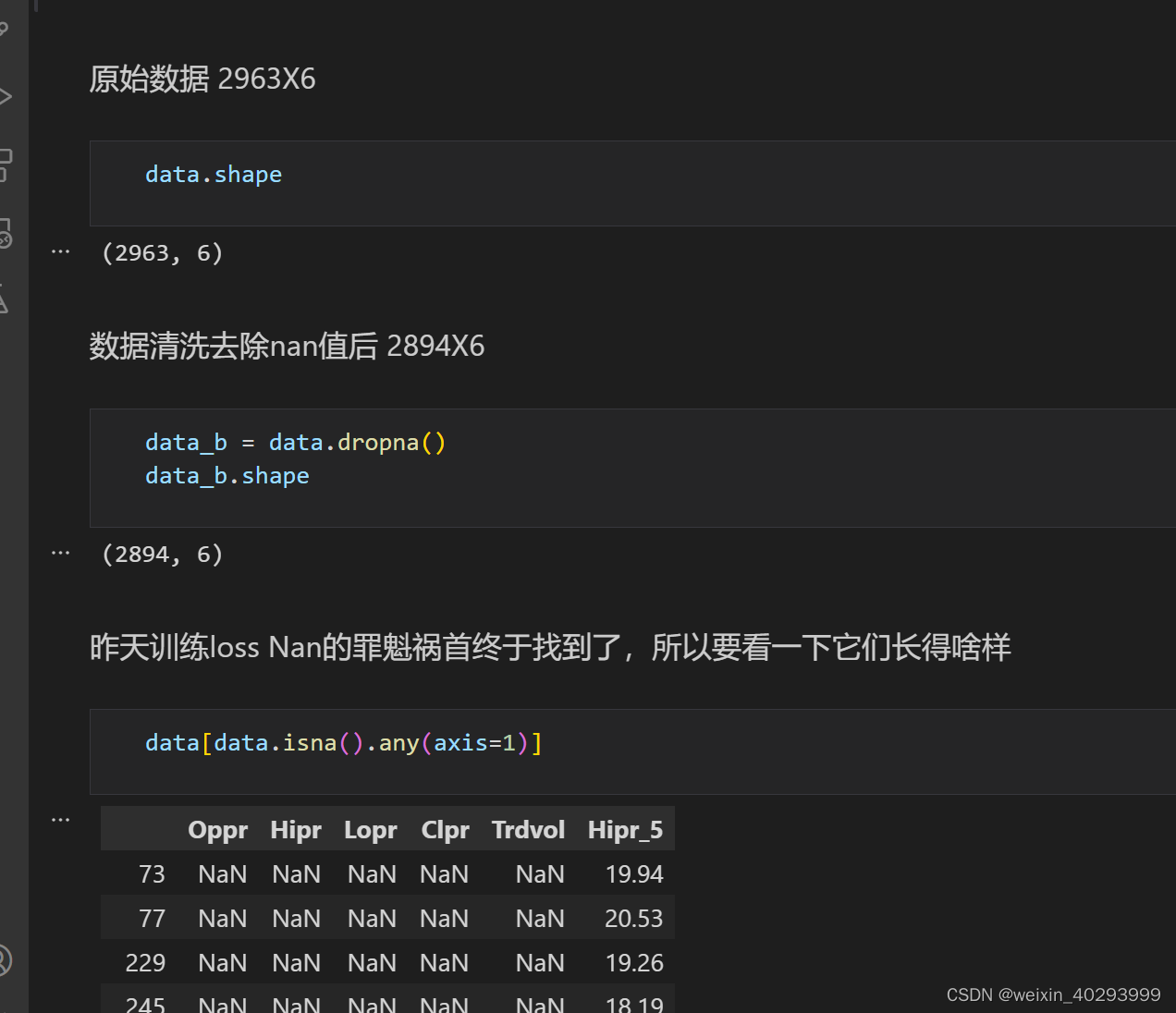
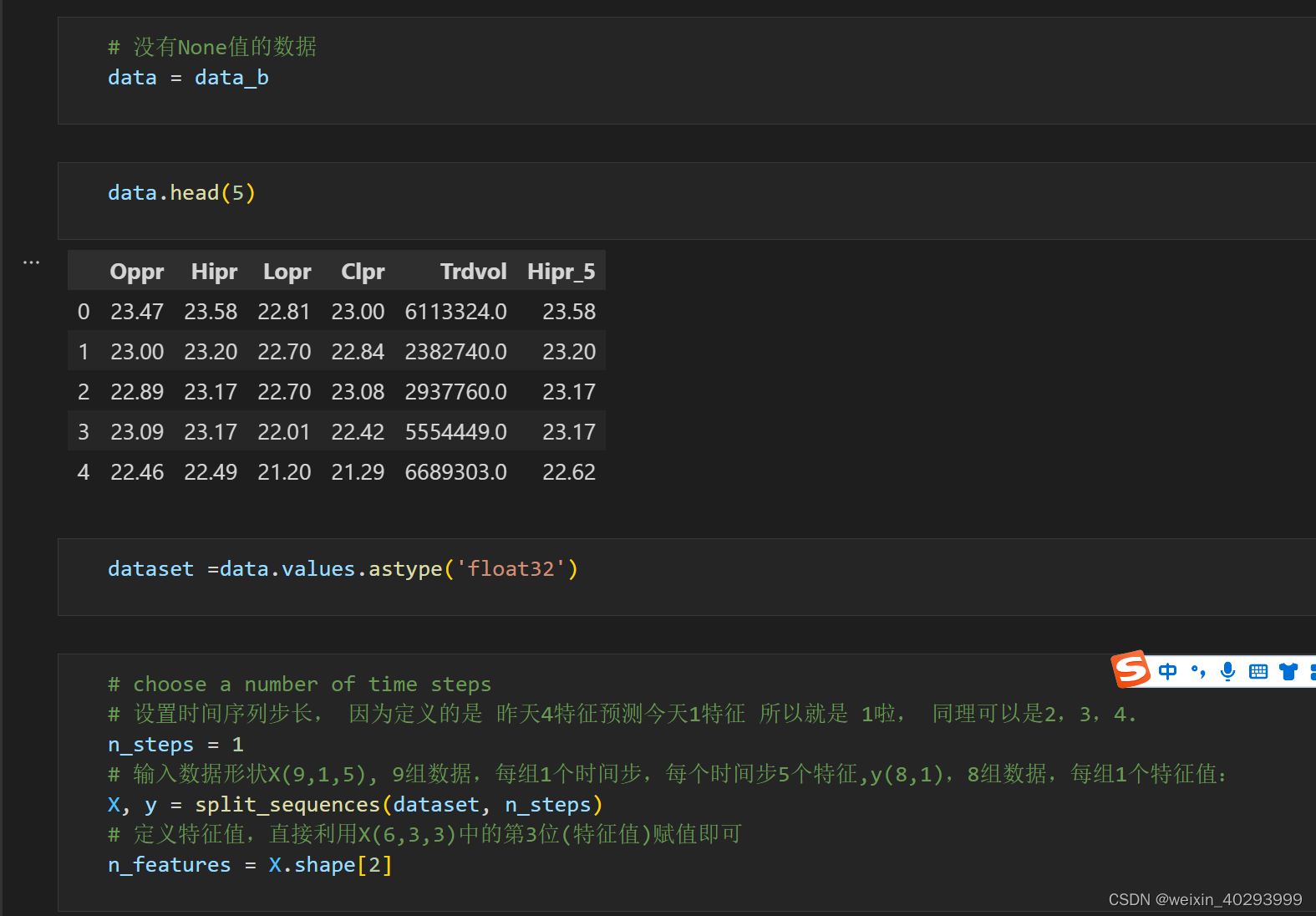
# choose a number of time steps
# 设置时间序列步长, 因为定义的是 昨天4特征预测今天1特征 所以就是 1啦, 同理可以是2,3,4.
n_steps = 1
# 输入数据形状X(9,1,5), 9组数据,每组1个时间步,每个时间步5个特征,y(8,1),8组数据,每组1个特征值:
X, y = split_sequences(dataset, n_steps)
# 定义特征值,直接利用X(6,3,3)中的第3位(特征值)赋值即可
n_features = X.shape[2]
# 切分训练集和测试集合
total_len = len(X)
train_len = int(total_len*0.9)
train_X = X[:train_len,:]
train_y = y[:train_len,:]
test_X =X[train_len:,:]
test_y =y[train_len:,:]
# 数据归一化
scaler_train_x = MinMaxScaler(feature_range=(0,1))
scaler_train_y = MinMaxScaler(feature_range=(0,1))
scaler_test_x = MinMaxScaler(feature_range=(0,1))
scaler_test_y = MinMaxScaler(feature_range=(0,1))
train_X_sc = scaler_train_x.fit_transform(np.squeeze(train_X)).reshape(train_X.shape[0],train_X.shape[1],train_X.shape[2])
train_y_sc = scaler_train_y.fit_transform(train_y)
test_X_sc = scaler_test_x.fit_transform(np.squeeze(test_X)).reshape(test_X.shape[0],test_X.shape[1],test_X.shape[2])
test_y_sc = scaler_test_y.fit_transform(test_y)
构建网络
# 构建网络
model = Sequential()
# 输入 n_steps = 1 (前一天), n_features = 5 (5 特征)
model.add(LSTM(100, activation='relu', return_sequences=True, input_shape=(n_steps, n_features)))
model.add(LSTM(100, activation='relu'))
# 输出一个数字 所以就写死了 1
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
训练
history = model.fit(train_X_sc, train_y_sc, epochs=20, batch_size=30, verbose=2, validation_data=(test_X_sc, test_y_sc),shuffle=False)
Epoch 1/20
87/87 - 3s - loss: 0.0242 - val_loss: 0.0278 - 3s/epoch - 31ms/step
Epoch 2/20
87/87 - 0s - loss: 0.0124 - val_loss: 0.0135 - 314ms/epoch - 4ms/step
Epoch 3/20
87/87 - 0s - loss: 0.0052 - val_loss: 0.0078 - 314ms/epoch - 4ms/step
Epoch 4/20
87/87 - 0s - loss: 0.0016 - val_loss: 0.0058 - 304ms/epoch - 3ms/step
Epoch 5/20
87/87 - 0s - loss: 0.0014 - val_loss: 0.0055 - 316ms/epoch - 4ms/step
Epoch 6/20
87/87 - 0s - loss: 0.0013 - val_loss: 0.0053 - 307ms/epoch - 4ms/step
Epoch 7/20
87/87 - 0s - loss: 0.0011 - val_loss: 0.0051 - 308ms/epoch - 4ms/step
Epoch 8/20
87/87 - 0s - loss: 0.0011 - val_loss: 0.0048 - 311ms/epoch - 4ms/step
Epoch 9/20
87/87 - 0s - loss: 9.8797e-04 - val_loss: 0.0048 - 314ms/epoch - 4ms/step
Epoch 10/20
87/87 - 0s - loss: 9.9258e-04 - val_loss: 0.0045 - 321ms/epoch - 4ms/step
Epoch 11/20
87/87 - 0s - loss: 9.1696e-04 - val_loss: 0.0045 - 320ms/epoch - 4ms/step
Epoch 12/20
87/87 - 0s - loss: 9.6857e-04 - val_loss: 0.0043 - 311ms/epoch - 4ms/step
Epoch 13/20
87/87 - 0s - loss: 9.1148e-04 - val_loss: 0.0043 - 319ms/epoch - 4ms/step
Epoch 14/20
87/87 - 0s - loss: 9.5715e-04 - val_loss: 0.0042 - 302ms/epoch - 3ms/step
Epoch 15/20
87/87 - 0s - loss: 9.2397e-04 - val_loss: 0.0042 - 316ms/epoch - 4ms/step
Epoch 16/20
87/87 - 0s - loss: 9.6084e-04 - val_loss: 0.0041 - 326ms/epoch - 4ms/step
Epoch 17/20
87/87 - 0s - loss: 9.1955e-04 - val_loss: 0.0041 - 305ms/epoch - 4ms/step
Epoch 18/20
87/87 - 0s - loss: 9.6290e-04 - val_loss: 0.0041 - 308ms/epoch - 4ms/step
Epoch 19/20
87/87 - 0s - loss: 9.2984e-04 - val_loss: 0.0041 - 304ms/epoch - 3ms/step
Epoch 20/20
87/87 - 0s - loss: 9.4243e-04 - val_loss: 0.0040 - 308ms/epoch - 4ms/step
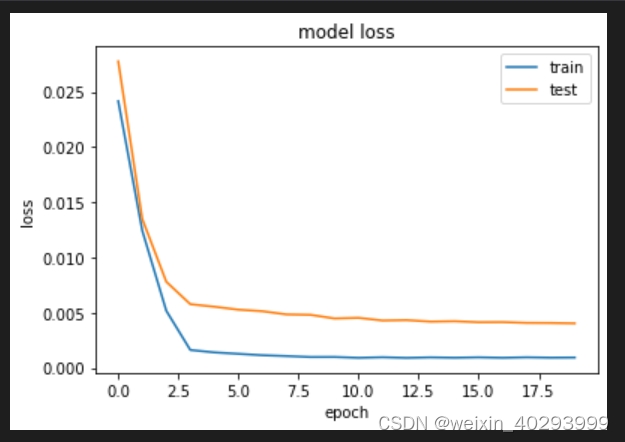
绘制损失图
plt.plot(history.history[‘loss’], label=‘train’)
plt.plot(history.history[‘val_loss’], label=‘test’)
plt.title(‘model loss’, fontsize=‘12’)
plt.ylabel(‘loss’, fontsize=‘10’)
plt.xlabel(‘epoch’, fontsize=‘10’)
plt.legend()
plt.show()
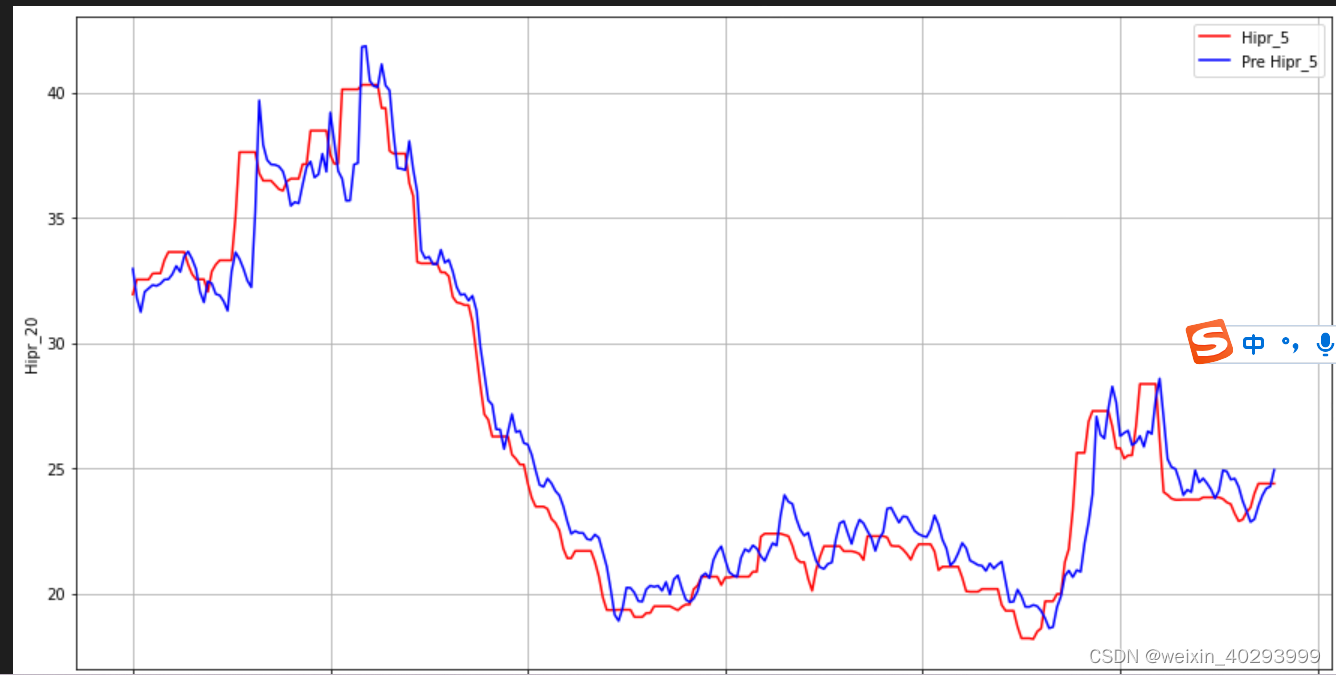
画出真实数据和预测数据的对比曲线(模型拟合效果不好,滞后性较明显)
plt.figure(figsize=(15,8))
plt.plot(real_y_inverse, color=‘red’, label=‘Hipr_5’)
plt.plot(y_predict_inverse, color=‘blue’, label=‘Pre Hipr_5’)
plt.legend()
plt.grid(“on”)
plt.xlabel(‘Time’)
plt.ylabel(‘Hipr_20’)
plt.legend()
plt.show()
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









