






 本文介绍了LGBPN网络,一种结合了空洞卷积和Transformer的自监督去噪方法,针对真实图像的噪声空间相关性和局部纹理混淆问题提出创新解决方案。网络结构包括DSPMC增强局部感知和DTB捕捉长距离依赖。损失函数采用L1范数。
本文介绍了LGBPN网络,一种结合了空洞卷积和Transformer的自监督去噪方法,针对真实图像的噪声空间相关性和局部纹理混淆问题提出创新解决方案。网络结构包括DSPMC增强局部感知和DTB捕捉长距离依赖。损失函数采用L1范数。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
上一篇博客撰写了AP-BSN网络进行自监督去噪论文的精读,包含代码的一些注解,今天来写一下在此基础上发展出来的LG-BPN网络,LG表示Local和Global,BPN表示Blind Patch Net,其中Local和Global分别通过空洞卷积和Transformer提取了局部和深空的特征,而BPN采用存在菱形孔洞的结构对特征图图像进行提取,尽可能的减少了空间相关性的影响。本篇博客完成后将着手构建自己的网络结构,并分析一下当前测试指标存在的问题等。来自github LGBPN作者的官方代码
一、real world image 存在的问题与文章的解决思路
该文章论述的主要问题同AP-BSN,主要问题为真是图像的噪声分布具有一定的空间相关性,不满足去噪网络的基本假设,本文做出的贡献为尽量打破噪声分布的空间相关性。另外一个是图像的局部纹理与空间噪声易混淆的问题。本文针对这两个问题分别提出了两种方案并进行结合,从而形成了该文章的三条创行点:
- 我们提出了一种用于真实世界图像去噪的新型自监督方法,称为 LGBPN,它能有效地编码局部细节结构和捕捉全局表示。
- 基于对真实噪声空间相关性的分析,我们提出了 DSPMC 模块,该模块可利用邻近像素较高的采样密度,实现更密集的感受野,从而改善局部纹理恢复。
- 为了在以往基于 CNN 的 BSN 方法中建立长距离依赖关系,我们引入了 DTB,它可以在遵守盲点感受野约束的同时聚合全局上下文。
二、网络结构
网络的总体结构如图1所示。主要由DSPMC+PD分别结合了空洞卷积增加局部感受野和结合DTB获得中长程的特征依赖。
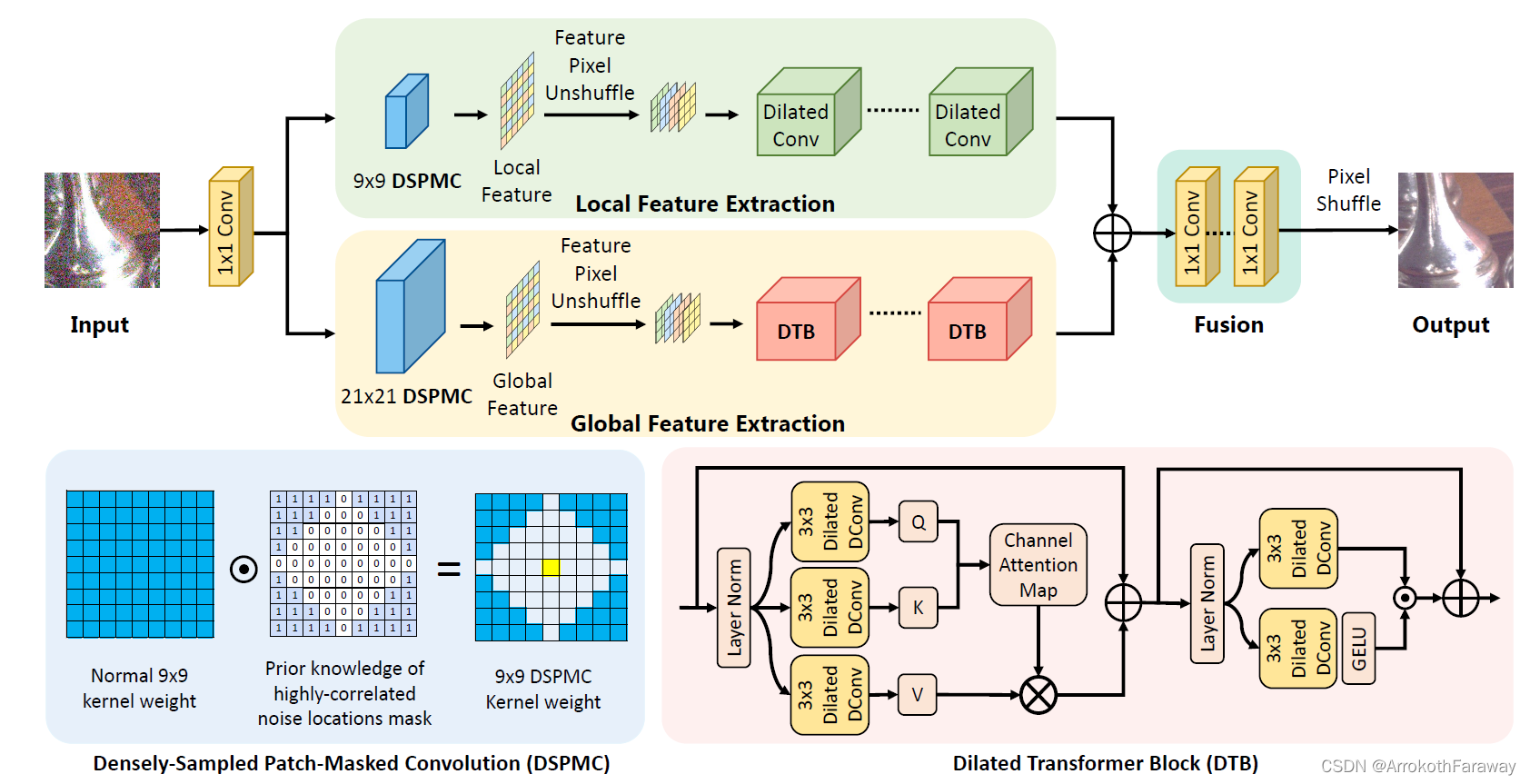
图1 网络结构图
1. DSPMC
传统的BSN的卷积核中,只有卷积核中心像素为0,本文提出的卷积核中,中心像素即部分相邻像素均为0,二者的对比如图所示。直接从图中对比可以发现,AP-BSN采用PD下采样后,在训练过程中一个的感受野范围是25×25,但是实际的特征采样点只有8个点,DSPMC对于11x11的感受野密集程度远大于AP-BSN,这带来了两种影响:
- 对局部的感知能力明显上升;
- 可训练参数与运算量的显著提升。
虽然第二类影响产生的运算负担被本文采用的漂移核策略减轻了很多,但依然导致了运算效率的下降。
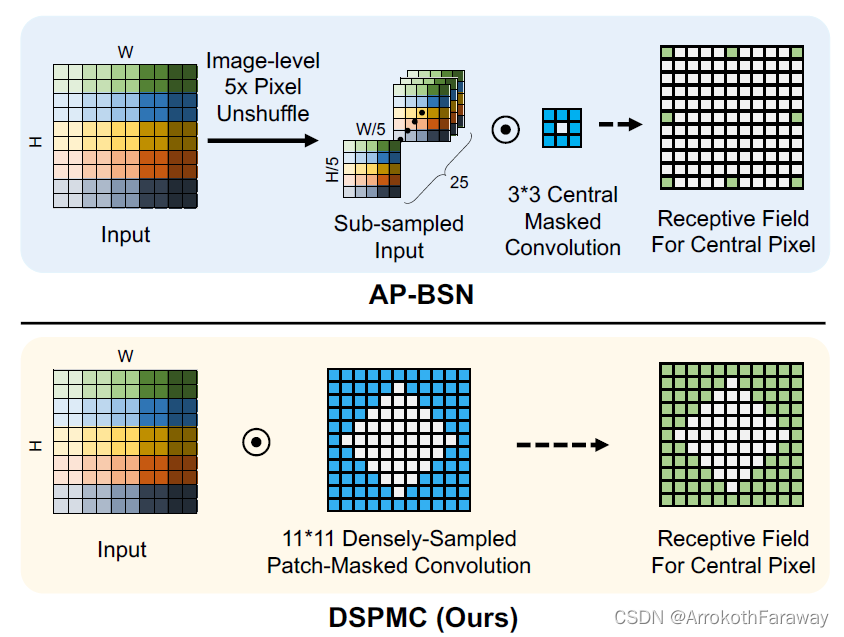
另外值得注意的:DSPMC也采用了DP的结构,只是与AP-BSN直接对原图进行DP不同,LG-BPN对DSPMC所提取的特征图进行DP,DP位置的变化可以更加显著的保留图像中的局部特征,即图像纹理信息。9×9的代码结构如下:来自github LGBPN作者的官方代码
class DSPMC_9(nn.Conv2d):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# TODO:
self.register_buffer('mask', self.weight.data.clone())
_, _, kH, kW = self.weight.size()
# self.mask.fill_(0)
kwargs_test = kwargs
kwargs_test['stride'] = kW
kwargs_test['padding'] = (0, 0)
self.test_conv = nn.Conv2d(*args, **kwargs_test)
# y = F.conv2d(input=x_offset, weight=weight, bias=bias, stride=kW, groups=1)
self.mask.fill_(1)
dis = kH // 2
for i in range(kH):
for j in range(kW):
if abs(i-dis) + abs(j-dis) <= dis:
self.mask[:, :, i, j] = 0
a = 1
# self.mask.detach().cpu().numpy()[0,0,...]
def forward(self, x, refine=False, dict=None, SIDD=True):
if SIDD:
pd_test_ratio = 0.72
pd_refine_ratio = 0.46
else:
pd_test_ratio = 0.5
pd_refine_ratio = 0.4
if dict is not None:
pd_test_ratio = dict['pd_test_ratio']
pd_refine_ratio = dict['pd_refine_ratio']
if self.training:
self.weight.data *= self.mask
return super().forward(x)
elif not refine:
x_out = self.forward_chop(x, ratio=pd_test_ratio)
return x_out
else:
x_out = self.forward_chop(x, ratio=pd_refine_ratio)
return x_out
def forward_chop(self, *args, shave=8, min_size=200000, n_GPUs=1, ratio=1):
# scale = 1 if self.input_large else self.scale[self.idx_scale]
scale = 1
n_GPUs = torch.cuda.device_count()
n_GPUs = min(n_GPUs, 4)
# height, width
h, w = args[0].size()[-2:]
top = slice(0, h // 2 + shave)
bottom = slice(h - h // 2 - shave, h)
left = slice(0, w // 2 + shave)
right = slice(w - w // 2 - shave, w)
x_chops = [torch.cat([
a[..., top, left],
a[..., top, right],
a[..., bottom, left],
a[..., bottom, right]
]) for a in args]
y_chops = []
if h * w < 4 * min_size:
for i in range(0, 4, n_GPUs):
x = [x_chop[i:(i + n_GPUs)] for x_chop in x_chops]
weight = self.weight
bias = self.bias
inc, outc, kH, kW = self.weight.size()
deform_conv = DeformConv2d(inc=inc, outc=outc, kernel_size=kW, stride=1, padding=kW//2, ratio=ratio)
x_offset = P.data_parallel(deform_conv, *x, range(n_GPUs))
# x_offset = deform_conv(x[0])
# y = F.conv2d(input=x_offset, weight=weight, bias=bias, stride=kW, groups=1)
self.test_conv.weight = weight
self.test_conv.bias = bias
y = P.data_parallel(self.test_conv, x_offset, range(n_GPUs))
# y = out
del x_offset
if not isinstance(y, list): y = [y]
if not y_chops:
y_chops = [[c for c in _y.chunk(n_GPUs, dim=0)] for _y in y]
else:
for y_chop, _y in zip(y_chops, y):
y_chop.extend(_y.chunk(n_GPUs, dim=0))
else:
for p in zip(*x_chops):
y = self.forward_chop(*p, shave=shave, min_size=min_size, ratio=ratio)
if not isinstance(y, list): y = [y]
if not y_chops:
y_chops = [[_y] for _y in y]
else:
for y_chop, _y in zip(y_chops, y): y_chop.append(_y)
h *= scale
w *= scale
top = slice(0, h // 2)
bottom = slice(h - h // 2, h)
bottom_r = slice(h // 2 - h, None)
left = slice(0, w // 2)
right = slice(w - w // 2, w)
right_r = slice(w // 2 - w, None)
if w % 2 != 0:
right_r = slice(w // 2 - w + 1, None)
bottom_r = slice(h // 2 - h + 1, None)
else:
right_r = slice(w // 2 - w, None)
bottom_r = slice(h // 2 - h, None)
# batch size, number of color channels
b, c = y_chops[0][0].size()[:-2]
y = [y_chop[0].new(b, c, h, w) for y_chop in y_chops]
for y_chop, _y in zip(y_chops, y):
_y[..., top, left] = y_chop[0][..., top, left]
_y[..., top, right] = y_chop[1][..., top, right_r]
_y[..., bottom, left] = y_chop[2][..., bottom_r, left]
_y[..., bottom, right] = y_chop[3][..., bottom_r, right_r]
if len(y) == 1: y = y[0]
return y
2. DTB(空洞transformer )
DTB的思想主要来自于文献2 Restormer,该文献将是下一篇研读的文献内容,是一篇将Transformer思想融入图像重建的文章。Transformer来自文章Attention is All You Need,具体是通过Q、K、V三个特征向量相互查询的方式实现的子注意力,即通过Q和K之间的相似性,对V进行投影。举例子来讲:算了,换别人举吧,这个博客有解释。自注意力机制的计算方式为:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
max
(
Q
K
T
)
V
X
^
=
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
+
X
{\rm{Attention}}({\bf{Q,K,V}}) = {\rm{soft}}\max \left( {{\bf{Q}}{{\bf{K}}^T}} \right){\bf{V}}\\ {\bf{\hat X}} = Attention({\bf{Q,K,V}}) + {\bf{X}}
Attention(Q,K,V)=softmax(QKT)VX^=Attention(Q,K,V)+X
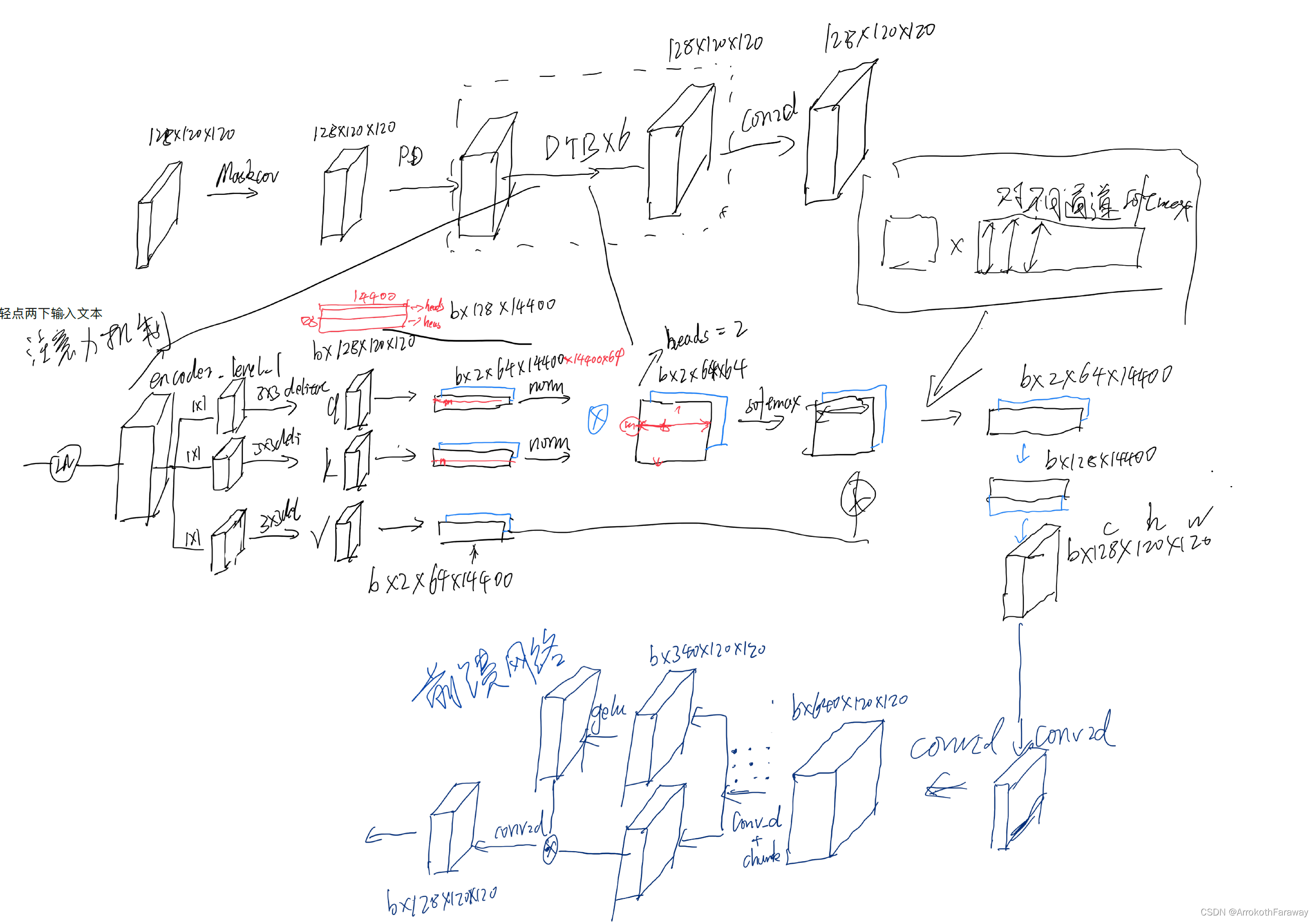
上图中表述了文章中对于global的branch,其中先进行了一次DSPMC的卷积,获得了特征密集、中间空洞的特征层,并进行了PD的额下采样(将多组下采样结果拼接后,不影响模块的大小),然后机内多次的DTB模块,文章中是六次,每一次的流程在途中的第二部分注意力机制,首先进行了特征通道的归一化,即Layer Normalization,之后采用1×1卷积将特征图复制三分,通过空洞卷积行程qkv的三个特征块(batch×ch×h×w)然后将h和w拉伸成1维向量,所以QKV的特征图在不考虑batch的情况下是二维的tensor,其中每一条红线表示一个通道(特征层)的所有特征,形成的注意力地图(Attention Map,batch×ch×ch)表征着不同特征曾之间的权重系数,对其按行(最后一维)进行softmax的归一化,减少不同特征层之间的梯度消失问题。最后对V进行映射后加上原始特征(忘画了)在经过前馈网络组成了每一个DTB的block。
三. 损失函数设计
未找到论文中明确的损失函数设计,通过代码查阅可知,采用模型输出和realnoisy图像自身(即模型输入)之间L1范数作为Loss函数,这也符合论文中所提自监督方法,如有不对敬请指正,代码内容如下。
@regist_loss
class self_L1():
def __call__(self, input_data, model_output, data, module):
if isinstance(model_output, dict):
output = model_output['recon']
else:
output = model_output
target_noisy = data['syn_noisy'] if 'syn_noisy' in data else data['real_noisy']
return F.l1_loss(output, target_noisy)
总结
总的来说,本文无论是逻辑上还是代码的质量上都较AP-BSN有一定的差距,但是其主要创行点在于结合了transformer获取了图像的全局特征参与局部的去噪,这对于一些较低频(具有明显缓变结构)的背景噪声特征具有较好的表达能力。
- 网络的参数量较AP-BSN有较大的变化;
- 本文的两篇主要参考文献为:
- Lee, W., et al. (2022). Ap-bsn: Self-supervised denoising for real-world images via asymmetric pd and blind-spot network. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- Zamir, S. W., et al. (2022). Restormer: Efficient transformer for high-resolution image restoration. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.
另外该论文的参考引用格式为,感谢作者在图像去噪领域做出的贡献:
Wang, Z., et al. (2023). LG-BPN: Local and Global Blind-Patch Network for Self-Supervised Real-World Denoising. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.

















 1555
1555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









