





系列文章目录
事件相机之一 空间目标检测
事件相机之二 去噪文章研读
摘要——动态视觉传感器(DVS)事件相机输出包括在昏暗照明下急剧增加的无信息背景活动(BA)噪声事件。现有的去噪算法在这些高噪声条件下是无效的。此外,很难定量比较算法的准确性。本文提出了一种新的框架,通过在已知信号和噪声DVS事件的情况下测量接收器的工作特性,更好地量化BA去噪算法。DVS在监控和驾驶中的固定和移动摄像头应用的新数据集用于比较3种新的低成本算法:算法1使用一个微小的固定大小窗口检查与过去事件的距离,并在保留固定摄像头场景的大部分信号的同时去除大部分BA。算法2使用与像素数成比例的内存来改进相关性检查。与现有方法相比,它在保留更多信号的同时去除了更多的噪声。算法3使用由局部事件时间曲面驱动的轻量级多层感知器分类器,在所有数据集上实现最佳精度。代码和数据作为DND21与论文共享。
文章目录
前言
基于事件的神经形态相机(“硅视网膜”)的灵感来自生物眼睛的非凡能力。近30年前的第一批设计已经成熟到现在有商用活动相机的阶段。活动摄像机有各种类型[3],但所有商业类型都使用动态视觉传感器(DVS)像素检测亮度变化。DVS摄像头输出是二进制签名的ON和OFF亮度变化事件流。事件表示对数强度因临界阈值时间对比度而变化。DVS的高动态范围和稀疏的亚毫秒输出使其能够在光线不足的情况下快速响应[3]。
事件相机的输出包括各种类型的噪声,包括事件抖动和量化噪声。这里我们关注的是背景活动(BA)噪声。即使在没有任何场景活动的情况下,这些BA噪声事件也来自像素,因此是非信息性的。在昏暗的灯光下,BA噪声主导了DVS输出。 使用DVS摄像头的机器人和监控系统越来越多地由DVS活动事件输出驱动,因此它们的功耗与活动成正比。通过降低相机输出端的BA噪声,我们可以将静态功耗降低几个数量级,特别是在噪声急剧增加的低光照条件下。现有的去噪方法在不去除信号事件的情况下,无法有效降低如此高的BA噪声水平。
图1显示了这种BA噪声的示例。DVS俯视赛道,信号事件由行驶的赛车产生。图1B所示的BA噪声事件掩盖了汽车运动引起的信号事件。DVS事件用于跟踪和控制汽车[1]。使用原始的噪声图1B输出跟踪汽车会导致噪声汽车速度估计,因为BA会干扰跟踪模型的更新,但去噪会产生图1C的输出。剩下的唯一要处理的事件是移动汽车产生的事件,这使得跟踪汽车位置和速度变得非常容易启动和精确估计。它还降低了静态事件数据速率,因此当汽车不移动时,计算工作量几乎为零。
之前的工作依赖于DVS像素动态的简化模型来预测理想化的事件,并开发了仅保留这些事件的方法。这种方法的根本问题是,它丢弃了不符合理想化模型的信息事件。相比之下,我们根据低光照和高光照条件下的详细测量开发了DVS BA噪声模型(第3节),并设计了一种新方法(第5节),将这种精确建模的BA噪声注入到所需的干净DVS数据中。因为我们知道什么是信号,什么是噪声,所以我们可以量化去噪的准确性。
先前的工作使用单个判别阈值量化去噪,这阻碍了去噪精度算法之间的公平比较,因为任何算法都可以通过增加判别阈值来过滤更多的噪声。相比之下,我们通过使用接收器工作特性(ROC)曲线来量化去噪精度,该曲线绘制了区分阈值的真阳性率(TPR)和假阳性率(FPR)。使用DVS像素的真实但无BA的模型从模拟场景中生成,然后将噪声(真实的合成BA噪声或单独记录的真实BA噪声)添加到信号DVS数据中(第3节)。这个过程使我们能够使用ROC曲线来衡量去噪的有效性。ROC方法允许独立于判别阈值对去噪能力进行公平比较。
尽早进行去噪对系统能效最有利,最近报道的事件摄像机可以产生高达1 GHz[6]、[7]、[11]的事件速率。为了实时对这些高事件率流进行去噪,我们开发了3种新算法(第4节),这些算法具有较小的计算复杂度和延迟,但去噪精度良好。
第4.1节提出了一对新的轻量级去噪滤波器,称为固定窗口滤波器(FWF)和双窗口滤波器(DWF)。它们的内存占用很小,但在使用固定摄像头的稀疏监控应用中可以有效地滤除噪声。
现有的低成本滤波器在运动相机产生的场景中的高噪声条件下无法有效地去噪。第4.2节提出了时空相关滤波器(STCF)。该滤波器比以前的方法更好地保留了缓慢移动的特征,同时即使在高噪声率下也能降低BA。
为了在保留最可能的信号事件的同时丢弃最多的噪声事件,第4.3节提出了一种轻量级的多层感知器去噪滤波器(MLPF),该滤波器利用过去事件的局部时空窗口中的结构线索来进一步提高TPR并降低FPR。它比以前的机器学习去噪方法便宜104倍以上。
三、DVS-BA噪声的特性
为了设计有效的BA去噪算法,了解真实的BA噪声特性非常重要。图3显示了高照度和低照度条件下DVS噪声的测量结果,绘制为BA事件之间的ISI直方图。继承自神经科学的指标 ISI 描述了尖峰事件的时间及其在单个像素和像素间的随机变化。我们从iniVation Davis346相机收集了这些数据[35]。这些测量表明,BA噪声在明亮和黑暗条件下的表现非常不同。
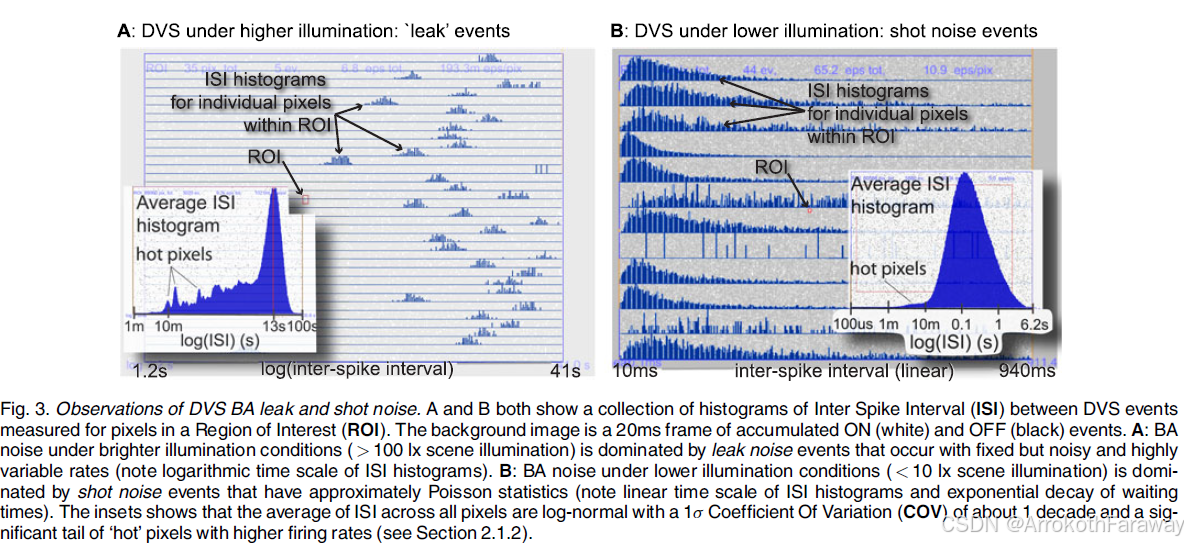
当场景明亮时,泄漏噪声事件 leak noise events 主导BA(图3A)。泄漏事件是由DVS变化检测器复位晶体管(图2B)中的结泄漏引起的,该晶体管对浮动节点充电,从而产生周期性的ON 事件。这里,ISI平均约为5秒,对应于约0.2赫兹/像素的速率,这与[3]表1中声称的标称速率一致。在一定强度以上,泄漏事件率与光强度成正比[9]。虽然它是周期性的,但由亮度变化等引起的每个事件都会重置周期,并且如图3A所示,ROI内单个像素的ISI直方图显示,像素之间存在较大的固定模式噪声(FPN)变化和周期性的定时抖动;速率变化约十年,抖动与ISI成正比。
当场景较暗时,散粒噪声事件主导BA(图3B)。散粒噪声是由DVS像素感光器和随机超过像素事件阈值的变化检测器电路的波动引起的。它具有近似泊松统计,并产生大致相等的ON和OFF活动。这里,散粒噪声率约为10Hz/像素,比泄漏噪声率高50倍。如ISI直方图所示,散粒噪声还具有较大的FPN,像素间的对数正态分布范围为0.5到1个十年。
在低照度下,每个像素的BA ISI分布接近泊松分布。泊松模型对于泄漏事件BA并不准确,但大的像素间可变性、抖动和任何导致对数强度变化的视觉信号输入都会使相邻像素的泄漏BA去相关性。第4.1.1节和第4.2.1节表明,我们对泄漏和散粒噪声的精确模拟模型产生的假阳性噪声分类率与记录的泄漏和散球噪声的真实样本相同。
四、去噪方法
图4显示了本文中比较的噪声滤波器,按内存要求分类。除了表征BAF[13]和ONF[8]滤波器外,我们还提出并表征了三种新的滤波器,FWF/DWF、STCF和MLPF。所有这些都是源代码3,MLPF包括训练数据和权重。

在第4.1.1节和第4.2.1节中,我们通过FWF和STCF滤波器播放录制的DVS噪声,以验证预测FPR的方程。我们的SM部分A和J.3考虑了去噪会阻断多少信号的双重问题。
1.FWF & DWF
对于内存严重受限和稀疏DVS数据的场景,所提出的固定窗口滤波器(FWF)仅依靠过去几个事件的窗口来检查时空相关性。我们定义了一个NNb固定窗口,以引用在当前事件之前发生的最新L事件。图4C显示了L=4时的FWF操作。固定窗口只存储 L事件中x、y的空间位置。时间隐含在事件流的顺序中。

选择L为事件计数,则考虑当前 e i e_i ei和其前L个事件 e i − L e_{i-L} ei−L,选取其中最小的马氏距离为 D m i n D_{min} Dmin,若 D m i n < σ D_{min}<\sigma Dmin<σ则认为 e i e_i ei为信号,否则,则认为其为噪声,流程如上图所示。
1.1 FWF噪声滤波的理论与测量
虚警(噪声残留的概率为)
r
F
W
F
(
L
,
σ
)
=
r
n
(
1
−
e
−
r
n
L
/
R
t
(
2
σ
2
+
2
σ
+
1
)
)
r_{FWF}(L,\sigma)=r_n(1-e^{-r_nL/R_t(2\sigma^2+2\sigma+1)})
rFWF(L,σ)=rn(1−e−rnL/Rt(2σ2+2σ+1))
总事件率
R
t
R_t
Rt的作用是填充长度为
L
L
L的固定窗口并控制有效相关时间窗口;总体事件发生率越快,相应的用于预处理的时间窗口就需要越短。下图展示了当选同数据率为90k的DAVIS346的情况下,噪声频率为0.1Hz,则总体噪声事件数为9kHz

我们发现测量结果与理论非常接近,这意味着我们可以用它来预测去噪对BA的影响,误差在10%以内。
1.2 双窗口滤波DWF
FWF的一个缺点是它在L个过去事件的窗口中的存储容量有限:该窗口经常被噪声事件占据,这些噪声事件也拒绝支持下一个即将到来的信号事件。DWF通过将固定窗口拆分为L=2长的信号窗口和L=2长噪声窗口来改进FWF的设计,前者用于存储预测信号事件,后者用于存储预测噪声事件。DWF检查过程类似于FWF:对于每个事件,我们检查两个窗口并获得 D m i n D_{min} Dmin,若 D m i n < σ D_{min}<\sigma Dmin<σ则认为 e i e_i ei为信号,更新信号窗口,反之则认为是噪声,更新噪声窗口。
2. 时空相关滤波器(STCF)
STCF是BAF的推广,其灵感来自[14],[22]。STCF过滤掉NNb内k个过去事件和相关时间t中缺乏支持的事件,而不仅仅是1个。对于1像素内的邻域,k可以从1(在功能上与BAF相同)变化到8像素。图1展示了STCF如何使有噪声的DVS输出基本无噪声,同时完全保留了移动汽车的有趣信号。
2.1 STCF噪声滤波的理论与测量
说明:文章里好像并未直接说明STCF的原理,但是通过对Section2和Section4.2的内容对比可以猜测其方法
计算BA噪声事件通过STCF的概率很简单(见SM第G.3节)。
总结
最近要写论文开题报告,头大,先到这里吧

















 1742
1742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









