






 本文介绍了一个用于自动驾驶的开放数据集OPV2V,包含丰富的车对车通信场景,用于评估信息融合策略。提出了一种注意力中间融合管道,即使在大压缩率下也能提升性能。实验结果显示,该方法在融合性能上表现出色。
本文介绍了一个用于自动驾驶的开放数据集OPV2V,包含丰富的车对车通信场景,用于评估信息融合策略。提出了一种注意力中间融合管道,即使在大压缩率下也能提升性能。实验结果显示,该方法在融合性能上表现出色。
OPV2V
摘要
在自动驾驶技术中,利用车对车通信来提高感知性能最近引起了相当大的关注;然而,由于缺乏合适的开放数据集用于基准测试算法,开发和评估合作感知技术变得困难。为此,我们提出了第一个用于车对车感知的大规模开放模拟数据集。它包含70多个有趣的场景、11464帧和232913个带注释的3D车辆边界框,这些场景来自CARLA的8个城镇和洛杉矶卡尔弗市的一个数字城镇。然后,我们用总共16个实现的模型构建了一个全面的基准,以评估几种信息融合策略(即早期、晚期和中期融合)与最先进的激光雷达检测算法。此外,我们提出了一种新的注意力中间融合管道来聚合来自多个连接车辆的信息。我们的实验表明,所提出的管道可以很容易地与现有的3D激光雷达探测器集成,即使在大压缩率的情况下也能获得出色的性能。为了鼓励更多的研究人员研究车对车感知,我们将在中发布数据集、基准方法和所有相关代码https://mobility-lab.seas.ucla.edu/opv2v/.
(本文主要侧重讲方法)
引言
我们提出了OPV2V,这是第一个具有V2V通信的大规模感知开放数据集。通过利用名为OpenCDA[18]和CARLA模拟器[19]的协同驾驶协同模拟框架,我们收集了73个不同数量的连接车辆的不同场景,以覆盖严重闭塞等具有挑战性的驾驶情况。为了缩小模拟与现实世界交通之间的差距,我们进一步构建了一个具有相同道路拓扑结构的洛杉矶卡尔弗市数字城镇,并在其上生成模拟现实交通流的动态代理。数据样本如图1和图2所示。我们将几种最先进的3D物体检测算法与不同的多车辆融合策略相结合,进行了基准测试。除此之外,我们还提出了一个专注中间融合管道,以更好地捕捉网络中连接代理之间的交互。我们的实验表明,所提出的流水线可以有效地降低带宽需求,同时实现最先进的性能。

注意力中间融合
由于来自不同连接车辆的传感器观测可能携带不同的噪声水平(例如,由于车辆之间的距离),因此一种能够关注重要观测而忽略干扰观测的方法对于稳健检测至关重要。因此,我们提出了一个关注中间融合管道来捕捉相邻连接车辆特征之间的相互作用,帮助网络关注关键观测结果。所提出的注意力中间融合管道由6个模块组成:元数据共享、特征提取、压缩、特征共享、注意力融合和预测。总体架构如图5所示。
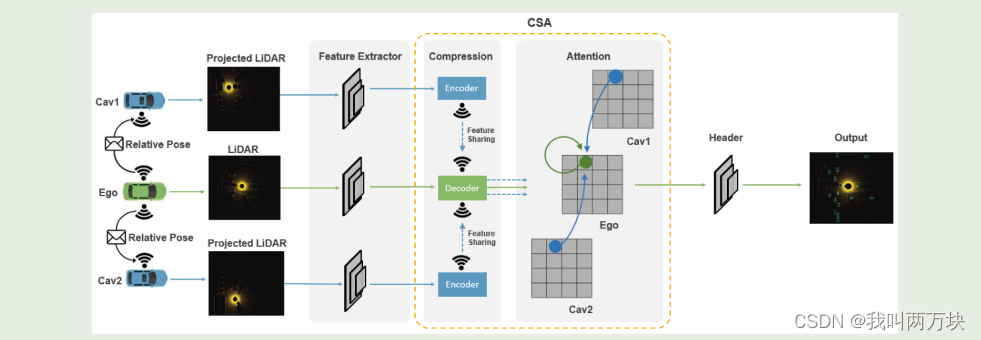 Attentive Intermediate Fusion管道的体系结构。我们的模型由6个部分组成:
Attentive Intermediate Fusion管道的体系结构。我们的模型由6个部分组成:
1)元数据共享:在相邻的CAV之间建立连接图和广播位置。
2) 特征提取:根据每个检测器的主干提取特征。
3) 压缩(可选):使用编码器-解码器压缩/解压缩功能。
4) 功能共享:与联网车辆共享(压缩)功能。
5) 注意力融合:利用自我注意力来学习同一空间位置的特征之间的互动。
6) 预测头:生成最终的对象预测。
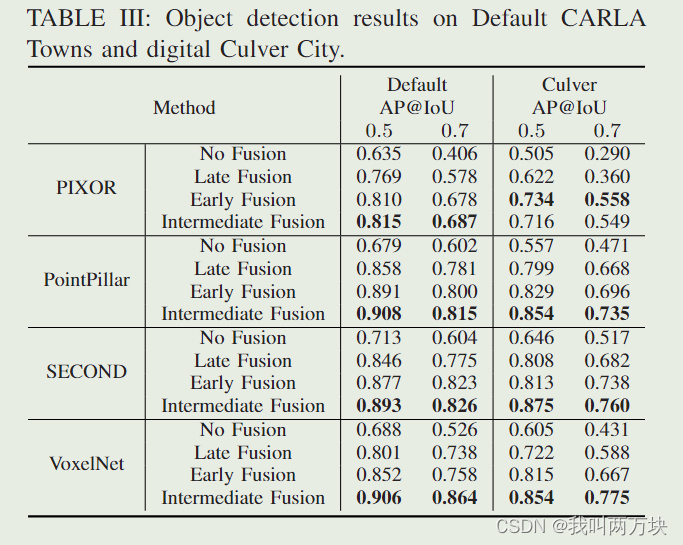
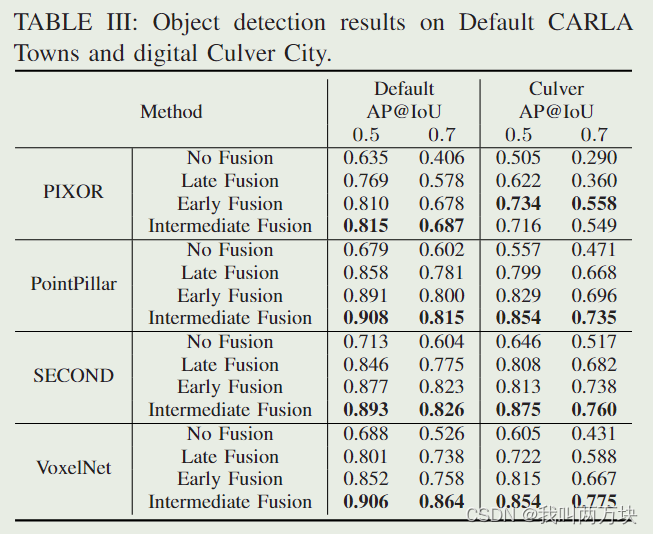
拟议的管道是灵活的,可以很容易地与现有的基于深度学习的激光雷达探测器集成(见表III)。
Metadata Sharing and Feature Extraction
我们首先广播每个CAV的相对姿态和外部特征,构建一个空间图,其中每个节点都是通信范围内的CAV,每个边表示一对节点之间的通信通道。构建图形后,将在组中选择一辆自我车辆。在训练过程中,随机选择组内的一辆CAV作为自我车辆,而在推理过程中,为了公平比较,自我车辆是固定的。这里的特征提取器可以成为现有3D目标检测器的主干。
Compression and Feature sharing
V2V通信的一个重要因素是硬件对传输带宽的限制。原始高维特征图的传输通常需要较大的带宽,因此必须进行压缩。与共享原始点云相比,中间融合的一个关键优势是压缩后的边际精度损失[15]。这里我们部署一个编码器-解码器架构来压缩共享消息。编码器由一系列二维卷积和最大池化组成,瓶颈中的特征映射将广播到自我车辆。在ego vehicles一侧包含几个反卷积层的解码器[27]将恢复压缩信息并将其发送到细心融合模块。
Attentive Fusion
采用自注意模型[28]来融合解压缩后的特征。同一特征图中的每个特征向量(图5所示的绿色/蓝色圆圈)对应于原始点云的一定空间区域。因此,简单地压缩特征图并计算特征的加权和将打破空间相关性。相反,我们为特征图中的每个特征向量构建一个局部图,其中为来自不同连接车辆的相同空间位置的特征向量构建边。一个这样的局部图如图5所示,自注意将在图上操作,以推理交互,以便更好地捕获代表性特征。
# -*- coding: utf-8 -*-
# Author: Hao Xiang <haxiang@g.ucla.edu>, Runsheng Xu <rxx3386@ucla.edu>
# License: TDG-Attribution-NonCommercial-NoDistrib
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
class ScaledDotProductAttention(nn.Module):
def __init__(self, dim):
super(ScaledDotProductAttention, self).__init__()
self.sqrt_dim = np.sqrt(dim)
def forward(self, query, key, value):
score = torch.bmm(query, key.transpose(1, 2)) / self.sqrt_dim
attn = F.softmax(score, -1)
context = torch.bmm(attn, value)
return context
class AttFusion(nn.Module):
def __init__(self, feature_dim):
super(AttFusion, self).__init__()
self.att = ScaledDotProductAttention(feature_dim)
def forward(self, x, record_len):
split_x = self.regroup(x, record_len)
C, W, H = split_x[0].shape[1:]
out = []
for xx in split_x:
cav_num = xx.shape[0]
xx = xx.view(cav_num, C, -1).permute(2, 0, 1)
h = self.att(xx, xx, xx)
h = h.permute(1, 2, 0).view(cav_num, C, W, H)[0, ...]
out.append(h)
return torch.stack(out)
def regroup(self, x, record_len):
cum_sum_len = torch.cumsum(record_len, dim=0)
split_x = torch.tensor_split(x, cum_sum_len[:-1].cpu())
return split_x
ScaledDotProductAttention公式:
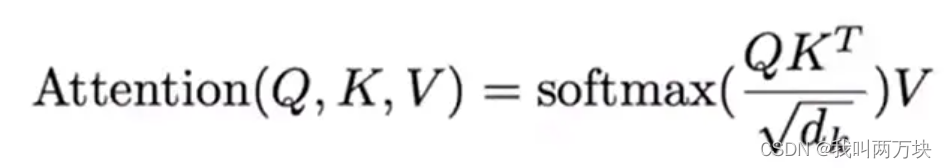
AttFusion中的forward函数逐行解析
- x表示tensor类型的特征
- regroup按照record_len的长度,将x进行分割
- 提取split_x的维度
- 定义空的out,存放融合特征
- 得到xx的通道数
- 按(cav_num, C, -1)重新排列矩阵的形状,permute对维度进行换位。
- 使用ScaledDotProductAttention
- 把维度换回来
- 存入out中
- 将融合的特征堆叠到一起变成一个single tensor。
AttFusion中的regroup函数逐行解析
- cum_sum_len = torch.cumsum(record_len, dim=0): 计算record_len张量沿着指定维度(dim=0)的累积和。这将得到一个包含记录长度累积和的张量。
- split_x = torch.tensor_split(x, cum_sum_len[:-1].cpu()): 使用torch.tensor_split根据累积和长度将输入张量x分成多个块。cum_sum_len[:-1]用于排除累积和的最后一个元素。.cpu()用于确保累积和张量在CPU上,这是tensor_split的要求。
- 返回分割后的张量列表
实际上regroup就起到了一个融合的作用
Prediction Header
融合的特征将被馈送到预测头部以生成边界框建议和相关联的置信度得分。
实验
结论
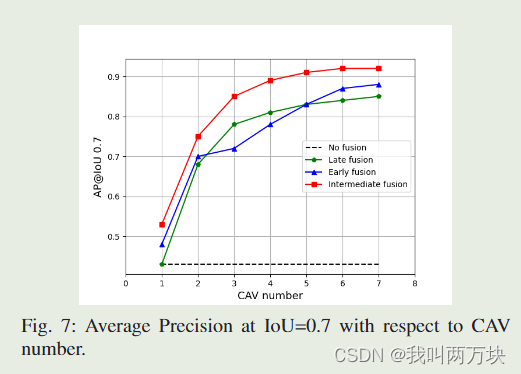
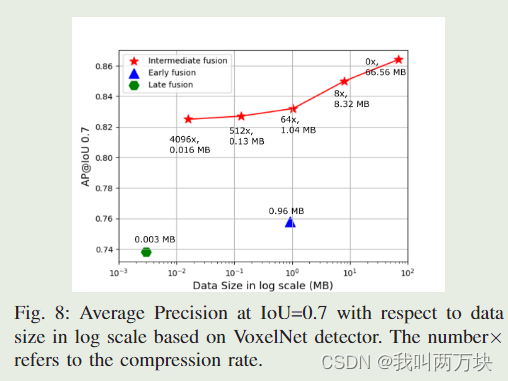
在本文中,我们提出了第一个用于 V2V 感知的开放数据集和基准融合策略。我们进一步提出了一个注意力中间融合管道,实验表明所提出的方法可以优于所有其他融合方法,即使在较大的压缩率下也能实现最先进的性能。未来,我们计划扩展具有更多任务和传感器套件的数据集,并在 V2V 和车辆到基础设施 (V2I) 设置中研究更多多模态传感器融合方法。我们希望我们的开源努力能够为 V2V 感知的标准化过程向前迈进,并鼓励更多的研究人员研究这个新方向。















 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









