






Brief
cvpr2020的研究工作,于2020/4/9日开源,如下图所示,和最近才阅读的文章Point-GNN一同被CVPR2020录取,目前被接收的文章有在KITTI上的有四篇,分别是PV-RCNN,SA-SSD,Point-GNN和这一篇文章,应该说pvrcnn是独树一帜的,在前面的博客中,我也有介绍到。

这一篇来自港中文和港科,同样是贾佳亚组,他们组在3D检测方向基本上算是处于垄断的存在了,之前的诸如point-rcnn,fast point rcnn,STD都是这个组的工作,同样厉害的还有MM-LAB,出了PVRCNN ,Part^A等工作。
Abstruct
- 目前基于LIDAR点云输入的3D检测深度学习网络主要分voxel-based和point-based两大类,其中voxel-based的方法已经有了一定的发展,但是point-based方法没有得到很好的发展。
(1)基于voxel的方法的发展,CVPR18的voxelnet是voxel-based方法的开山之作, 但是当时voxelnet由于3D CNN的使用导致很大的显存占用,18年sensors的ECOND引入了稀疏卷积使得内存占用大大减少,同时该文引入了一个从标注集合sample的数据增广方案,次年的CVPR19的pointpillars则是直接将voxel改进为pillar直接跳过了3D卷积这一步骤,后续的19年ICCV则是将基于voxel的方法的参数优化(由于稀疏卷积的引入,使得更小的voxel可以被使用)以及改进为两阶段的方法fast pointrcnn,其中STD是直接将体素划分改为了球体划分(具有更好的方向性)。同样的19年的NIPS的文章有开始考虑从整个场景中粗略的先注意到大致的object,再对该场景进行划分。该类的方法的核心思想就是把点云的无序性通过体素划分使其规整,但是不可避免的会有信息丢失。
(2)基于Point的方法比较难以解决的是场景点云的无序性问题,19年的CVPR的Point RCNN是一篇完全基于点做的3D目标检测方法,但是该方法采用的anchor设置是对每一个场景点都会认为是,会造成很大的冗余,后续再次基础上延展性不是很大。
当然19年还有很多好的工作,比如CVPRW19中有文章采用RNN+attention的方式将大场景的点云裁缝后再送入RNN结构中,还有一些从小处入手的工作,将二维目标检测的IOU Loss引入到三维点云结构中;由于稀疏卷积的引入,将子流型卷积和3D稀疏卷积结构融合设计的3D backbone等等;为了提升效率,将voxel和point方式结合的方法等等
- 本文提出的3D-SSD是一个综合利率和精度的one-satge的目标检测框架。
作者这里提出观点,如果要point-based的方法提高效率,就必须要要改进或者丢掉耗时很久的上采样,因此作者的做法是设计了一种采样策略,通过下采样得到的少数点去预测detections也成为可能。
- 作者为了实现采用point-based的方法,同时又能兼顾精度和效率,设计了
candidate generation layer和anchor-free regression head以及3D center-ness assignment strategy。 - 这是一个 onestage anchor free的目标检测方法,比所有的 voxel-based的但阶段检测方法效果都要好,能达到25FPS。
这里值得一提的是,在3D目标检测中,称第一个anchor-free的文章应该是OHS,也是19年底的一个工作,它采用的方法类似part(作者文章中称为hotspots)去预测detection。
0. 本文主要内容概括
本文主要从point-based的研究入手,考虑如何解决掉以前的point-based的方法的瓶颈,即时间和内存占有远远大于voxel-based的方法,从而作者设计了新的SA模块和丢弃了FP模块到达时间上可达25FPS,此外本文采用一个anchor free Head,进一步减少时间和GPU显存,提出了3D center-ness label的表示,进一步提高的精度。可视化效果如下:

1. Introduction
经典开头,3D检测的应用,之后是目标的2D方法取得了很大的发展,但是在3D上并不能直接套用2D的检测方法,这是因为点云的稀疏性和无规则性。
- 为了解决上诉提到的点云的稀疏性和无规则性带来的挑战,一些方法开始采用将点云投影到图像中,这样就能得到密集的表达形式。
这类文章出现在17-18年的工作比较多,包括有CVPR17的[1],采用MV融合的方法;
而后在18年的CVPR上将深度学习完全引入点云检测中,开创了voxel-based方法的先河的voxelnet[2],这是一篇非常经典的张,目前已有500的引用,后续的很多工作都在此基础上发展的。
上诉的voxel-based方法尽管很高效,但是在划分体素过程中不可避免的会造成信息的丢失,这一点在MMLAB CVPR2020的文章PVRCNN中采用pointnet的可变感受野来减少信息丢失。
-
上诉的方法都是想着怎么把点先规整化,但是point-based方法是直接在每一个点上预测得到对应的Bbox,一般会分为两步,第一步是通过SA模块(出自 pointnet++)和下采样提取context feature,然后是通过FP(也是pointnet++模块)将全局特征上采样传递给那些没被采样到的点,采用反卷积,再然后通过RPN网络得到proposals;第二步是refine,在proposals的基础上优化得到最后的detections
-
本文的突出贡献点
这是一个 One-stage anchor free的方法。
提出了下采样融合策略F-FPS和D-FPS,目的是替换点上述的FP模块,使得计算损耗大大减少。
在KITTI上和NuScence上的实验效果很好 -
大体结构
在SA模块后,作者设计了CG层(candidate generation )提出候选框;在CG层中,作者首先将representative points生成候选点,这个生成过程的监督信息时这个代表点的和该点对应的object的中心坐标值的相对信息;接着作者将这个候选点看做为中心,再从F-FPS和D-FPS的集合点中找到他们的周围点,再采用MLP提取他们的特征。这些特征最终会被送入到一个anchor free head中来预测最后的3D bbos。
2 网络结构
2.1 Point-based方法的瓶颈
瓶颈1——FP层的丢弃与保留
以往基于点的检测方法通过SA模块可以得到context features,但是仅仅只有采样的点才会有这些特征,没有被采样的点就没有特征,因此需要FP模块将这些特征传递给没有被采样到的点,作者给出了如下的表格:

(1)这里的SA采用了4层SA layer(标准Pointnet++设计),FP是4层FP layer,同时refine 模块是3层SA layer
(2)这里的FP模块似乎占比并不大,但是如果将FP去掉,肯定是能降低计算损耗的,同时作者为一阶段的方式,后续的优化模块也是不存在的。
因此作者的想法是将FP层丢掉来降低运行时间,首先最容易想到的设计方案是直接采用SA最后剩下的采样点进行预测,但是由于前人的采样是D-FPS,也就是欧式距离的最远点采样,就会使得采样点中很多的背景点,仅仅靠仅存的几个前景采样点预测出结构几乎是做不到的,所以直接丢弃不做任何处理是不可行的。作者在NuScene给出了统计出的对比结果:
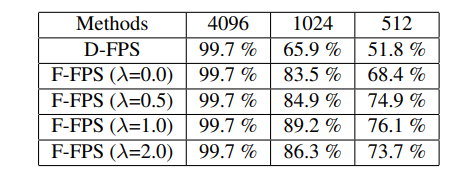
从表格中我们可以看出,采用D-FPS的采样方法,如果采样点为512个时,object的内点占比仅仅只有一半了,是很不足够的(比笔者想象的多一些),但是如果选用F-FPS(特征空间采样),那么效果会好一些。
总结一下,FP层如果保留,那么会保留很大的时间消耗,以致于和voxel-based的方法比较起来没有任何优势,如果直接丢弃,会造成很大精度损失。
作者的改进——F-FPS
前人采用的D-FPS算法是在欧式空间中进行的最远点采样,并不会考虑到该点的任何属性特征;作者因此引入了F-FPS,在语义信息的引导下,能够排除大量的背景点信息,保留更多的前景点信息。但如果仅仅只使用FFPS,会保留很多同一个object的点,也会导致精度下降,因此作者同时考虑了欧式和特征空间的采样信息。
C
(
A
,
B
)
=
λ
L
d
(
A
,
B
)
+
L
f
(
A
,
B
)
C(A, B)=\lambda L_{d}(A, B)+L_{f}(A, B)
C(A,B)=λLd(A,B)+Lf(A,B)
因此作者采用上述的综合采样方法。正如上表的采样结构显示得到了一定的效果提升。
瓶颈2——FFPS导致cls分数下降
作者指出,尽管采样使用FFPS可以提高前景点中的占比,这对reg是很有帮助的,但是背景点过少的时候对cls是不友好的,在后面的消融实验中也可以看出,尽管FFPS能提高REG得分,但是对cls却分数不如DFPS的方法。
为解决这个问题,作者采用融合采样的设计,如果最终采样点个数为
N
m
N_m
Nm个,那么其中的
N
m
2
\frac{N_{m}}{2}
2Nm个点分别采用的是上述的D-FPS和F-FPS的采样法。
2.2 bbox预测网络
CG Layer
前人的研究工作都是在得到每个点的feature后,接上三层的SA layer,分别用于中心点选择,周围点特征提取以及生成语义信息。
但是本文作者为了进一步降低计算成本,候选中心点的生成是直接在F-FPS采样后进行的,如下图所示,可以看的出来,F-FPS采样的点由于比D-FPS的点更加可能是前景点,所以后选点仅仅只是在F-FPS的点上生成,也就是candidate points;接着作者将这些候选中心点当做CG layer的中心点。(作者在这里挖坑表明不采用object的中心作为CGlayer的中心是考虑了最终的性能,在后续会提及到);同样的下一步则是根据候选中心点领域选择从FFPS和DFPS中采样得到的代表点进行局部特征提取,采用MLP进行特征提取。

oveall structure

从如上的结构图可以看出上面提及到的作者设计的结构:
- SA layer
前人的SA layer都是按照pointnet++文章中的那样设计,但是本文的SA正如前面提到的融合的欧式空间和特征空间的采样方法,并且各自采取一半的点,然后多个SA模块组合就可以得到这样的backbone。
这里根据数据集的不同,在backbone的设计层数也是不同的,作者给出了在KITTI和Nuscence上的结构如下,看的出来NuScene场景大好多。

- CG layer
这一层的目主要是:
(1)得到候选中心点
(2)通过候选中心点整合周围采样点提取语义信息 - prediction head
如图,回归和分类
Anchor-free Regression Head
前面的overall structure中的第三部分的回归网络结构。作者首先指出假设本文采用anchor-based的方法的话,没增加一个类别,则需要在全场景增加不少的anchor。再考虑到旋转性,就更多了。
插入一点,在3D检测网络中,都是按照预先设置的object级别的大小anchor,在全场景中每隔一段距离就设置一个anchor,同时每个anchor有几个不同的朝向。就是说,每增加一类的物体,计算量就是线性增加的。
考虑到上面的计算量,作者采用的是anchor free的head,回归的也是一样的七个量,这里需要指出的是通过点预测是没有预先设置朝向的,因此作者采用分类和回归的混合表达式。后续讲到
3D Center-ness Assignment Strategy
在二维中,label分配的方法有采用IOU阈值,mask这两种方法;FCOS这篇文章将二值的pix label扩展为连续性的label,越是靠近object中心的pix所得到的分数也就设置越大;在3DLIDAR数据上,由于点云数据都在物体的表面,因此他们的center-ness都非常小并且接近的,这会导致从这些点得到好的预测不太可能。这里也就是前面为什么不用原始的采样点作为候选点,也是从FFPS采样后再朝向中心靠近后的点作为候选点,因为靠近中心的候选点可以有更加接近和更加准确的结果,同时根据center-ness label可以轻松和object的表面的点区分开。
作者采用定义center-ness label通过两步:
- 首先确定该点是否在一个object中
- 通过画出object的六面体,然后计算该点到其前后左右上下表面的距离,再通过以下公式得到其对应的center-ness值。
l ctrness = min ( f , b ) max ( f , b ) × min ( l , r ) max ( l , r ) × min ( t , d ) max ( t , d ) 3 l_{\text {ctrness}}=\sqrt[3]{\frac{\min (f, b)}{\max (f, b)} \times \frac{\min (l, r)}{\max (l, r)} \times \frac{\min (t, d)}{\max (t, d)}} lctrness=3max(f,b)min(f,b)×max(l,r)min(l,r)×max(t,d)min(t,d)
2.3 损失函数
全部损失函数分为分类损失、回归损失和偏移损失(这个是指从采样代表点到候选点得到时的损失函数)
L
=
1
N
c
∑
i
L
c
(
s
i
,
u
i
)
+
λ
1
1
N
p
∑
i
[
u
i
>
0
]
L
r
+
λ
2
1
N
p
∗
L
s
\begin{aligned} L=& \frac{1}{N_{c}} \sum_{i} L_{c}\left(s_{i}, u_{i}\right)+\lambda_{1} \frac{1}{N_{p}} \sum_{i}\left[u_{i}>0\right] L_{r} \\ &+\lambda_{2} \frac{1}{N_{p}^{*}} L_{s} \end{aligned}
L=Nc1i∑Lc(si,ui)+λ1Np1i∑[ui>0]Lr+λ2Np∗1Ls
上式的
N
c
N_c
Nc表示所有候选点的个数,
N
p
N_p
Np表示为候选点中前景点的个数。
- 其中分类损失函数采用的是交叉熵损失函数,其中 s i , u i s_i,u_i si,ui分别表示预测得分和center-ness 分数。
- 回归loss中分为下面几部分:
(1)距离回归,即是中心点坐标的回归 x , y , z x,y,z x,y,z,采用smooth l1函数
(2)size回归,即是回归bbox的 l , w , h l,w,h l,w,h,采用smooth L1函数
(3)角度回归,回归偏航角 y a w yaw yaw,角度回归也分为两部分,第一部分是cls,第二部分是残差reg,如下:
L a n g l e = L c ( d c a , t c a ) + D ( d r a , t r a ) L_{a n g l e}=L_{c}\left(d_{c}^{a}, t_{c}^{a}\right)+D\left(d_{r}^{a}, t_{r}^{a}\right) Langle=Lc(dca,tca)+D(dra,tra)
(4)角点损失,corner loss,即是八个角点的损失函数,如下,其中 P m , G m P_m,G_m Pm,Gm分别表示对应的预测的角点坐标
L corner = ∑ m = 1 8 ∥ P m − G m ∥ L_{\text {corner}}=\sum_{m=1}^{8}\left\|P_{m}-G_{m}\right\| Lcorner=m=1∑8∥Pm−Gm∥
- shifting loss 偏移损失函数是在CG layer中被监督训练,即是预测候选采样点到object中心点的残差,采用smooth L1损失函数。这里是 N p ∗ N_p^* Np∗表示F-FPS采样到的postive的候选点。
3 实验
3.1 KITTI
一些实现细节
- 随机采样到16384个点输入
- 为了防止过拟合,作者采用了四中数据增广,分别是mix-up策略(SECOND的作者提出过这个解决方案),对每一个Bbox,有随机旋转和平移,第三,沿着x轴随机尺度变化。第四,全场景点云沿着z轴随意旋转。
最近有一篇文章有研究过数据增广在3D检测中的应用
实验结果

3.2nuScenes
这个数据集是19年CVPR推出的新的自动驾驶数据集,有着更大的场景和更复杂的分类任务,每一帧有超过4w个点,其中有一些关键帧,前人的方法都是将关键帧和随后的0.5s的帧结合以致于超过40w个点来做目标检测(最近有一篇通过点云流的方式做3D目标检测的文章[4],而且已经开源),这对于point-based的方法来说就是灾难。

值得一提的是,19年提出的数据集nuScence目前还有很多值得可做的,之前有一篇采用class balance loss的方法做到了nuscence的榜首,目前也已经开源,不过此时改了名字叫det3D的这样一个架构,该架构也已经集成了很多的sota的方法。
3.3消融实验
- 融合采样方法
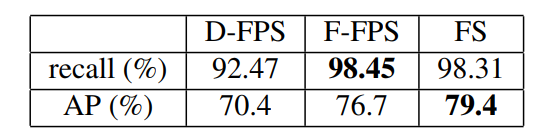
- shifting in CG layer

- point-based的方法的时间对比

推荐阅读文献
[1] Multi-view 3d object detection network for autonomous driving.
[2]Voxelnet: End-to-end learning for point cloud based 3d object detection
[3]Fcos: Fully convolutional one-stage object detection
[4]LiDAR-based Online 3D Video Object Detection with Graph-based MessagePassing and Spatiotemporal Transformer Attention















 1032
1032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









