






大语言模型的出现引发了深度学习领域的显著范式转变。尽管有这些进展,大量高质量数据仍然是构建稳健自然语言处理(NLP)模型的基础。然而,由于高成本、数据稀缺、隐私问题等原因,依赖人类数据来满足这些需求有时是具有挑战性甚至是不现实的。此外,多项研究表明,人类生成的数据由于其固有的偏见和错误,可能并不是模型训练或评估的最佳选择。这些考虑促使我们更深入地探讨是否有其他更有效和可扩展的数据收集方法可以克服当前的限制。
鉴于LLMs的最新进展,它们展示了生成与人类输出相当的流畅文本的能力,由LLMs生成的合成数据成为了人类生成数据的一种可行替代品或补充。具体来说,合成数据旨在模仿真实世界数据的特征和模式。下面两个优势使LLMs成为极具前景的合成数据生成器:
- 一方面,LLMs通过广泛的预训练,积累了丰富的知识库,并展现出卓越的语言理解能力,这为生成真实的数据奠定了基础。
- 另一方面,LLMs深厚的指令遵循能力允许在生成过程中实现更好的可控性和适应性,从而能够为特定应用创建定制的数据集,并设计更灵活的流程。
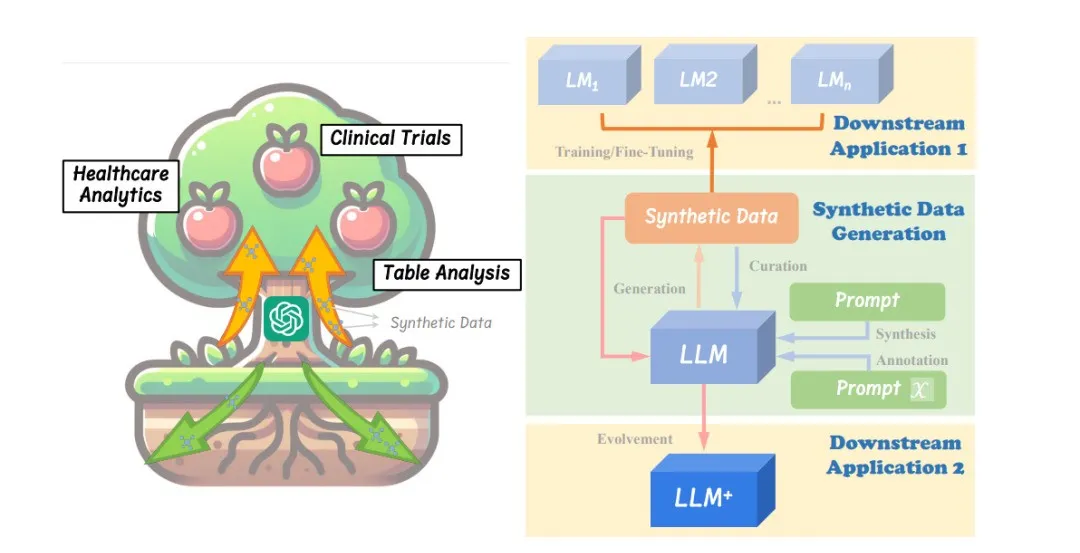
LLMs驱动的合成数据生成研究通常涵盖三个主要方面:生成、整理和评估。
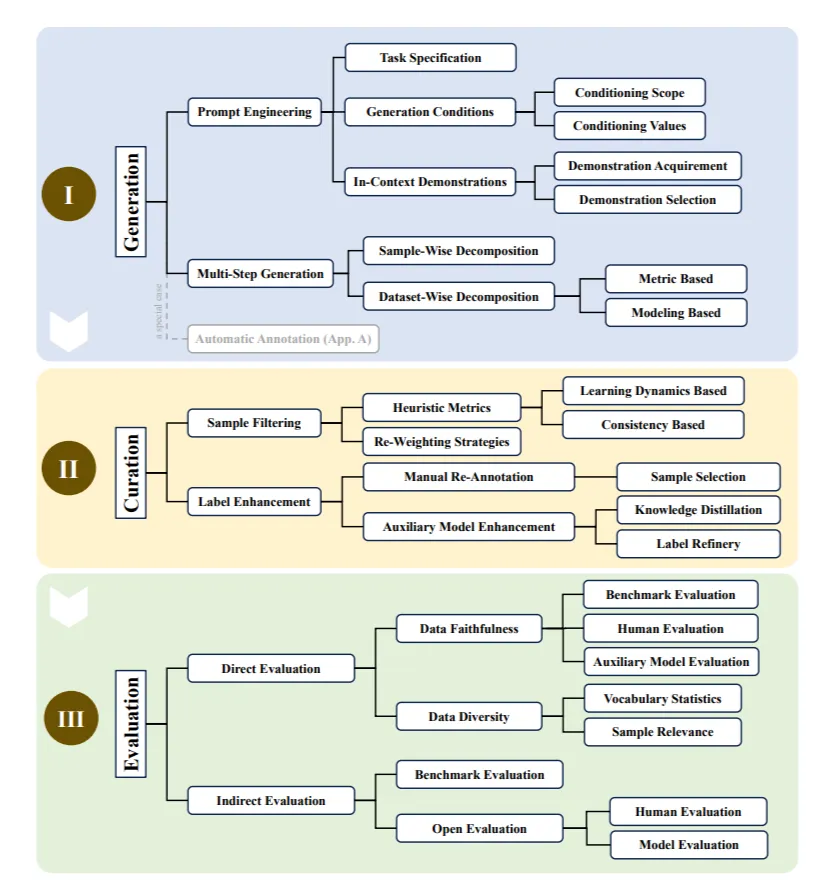
1 合成数据的生成
常见的合成数据生成实践可以大致分为提示工程和多步骤生成。
- 提示工程:LLMs的指令遵循能力使其在生成数据时具有很好的可控性。有效的提示通常包含三个关键元素:任务规范、生成条件和上下文演示,然后用模板将其包裹成自然指令。
- 多步骤生成:通过逐步生成数据来增强其多样性和真实性,具体方法根据不同任务和场景进行调整
2 合成数据的整理
数据整理:确保生成的数据在逻辑和内容上的一致性和连贯性。生成的数据必须在逻辑和语法上连贯。然而,LLMs固有的幻觉问题和知识分布的长尾效应可能会引入显著的噪声,表现为事实错误、标签错误或无关内容。
3 合成数据的评估
数据评估:使用多种评价指标来评估数据质量,如准确性、多样性和相关性。多样性反映了生成数据的变化,包括文本长度、主题或写作风格的差异。这对于生成模拟真实世界数据的样本至关重要,从而防止模型训练或评估过程中的过拟合和偏差。
4 结语
尽管看似简单,但生成同时具有高正确性和足够多样性的合成数据集需要精心设计过程,并涉及许多技巧,使得LLMs驱动的合成数据生成成为一个非平凡的问题。论文的主要目的是提供该领域的全面概述,确定关键关注领域,并突出需要解决的空白,希望为学术界和工业界带来见解,并推动LLMs驱动的合成数据生成的进一步发展。
论文题目:On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
论文链接:https://arxiv.org/pdf/2406.15126
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!


















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









