







模型结构创新(MLA+DeepSeekMoE)主要体现在DeepSeek-V2模型中,该模型通过结合MLA(Multi-head Latent Attention)架构和自研的DeepSeekMoE稀疏结构,实现了显著的性能提升和成本降低。
-
MLA架构:MLA是一种多头潜意识注意力机制,旨在减少计算量和推理显存。与传统的MHA(Multi-head Attention)相比,MLA通过低秩键值联合压缩和解耦旋转位置嵌入(RoPE),大幅降低了重复运算的开销,从而提高了推理效率。
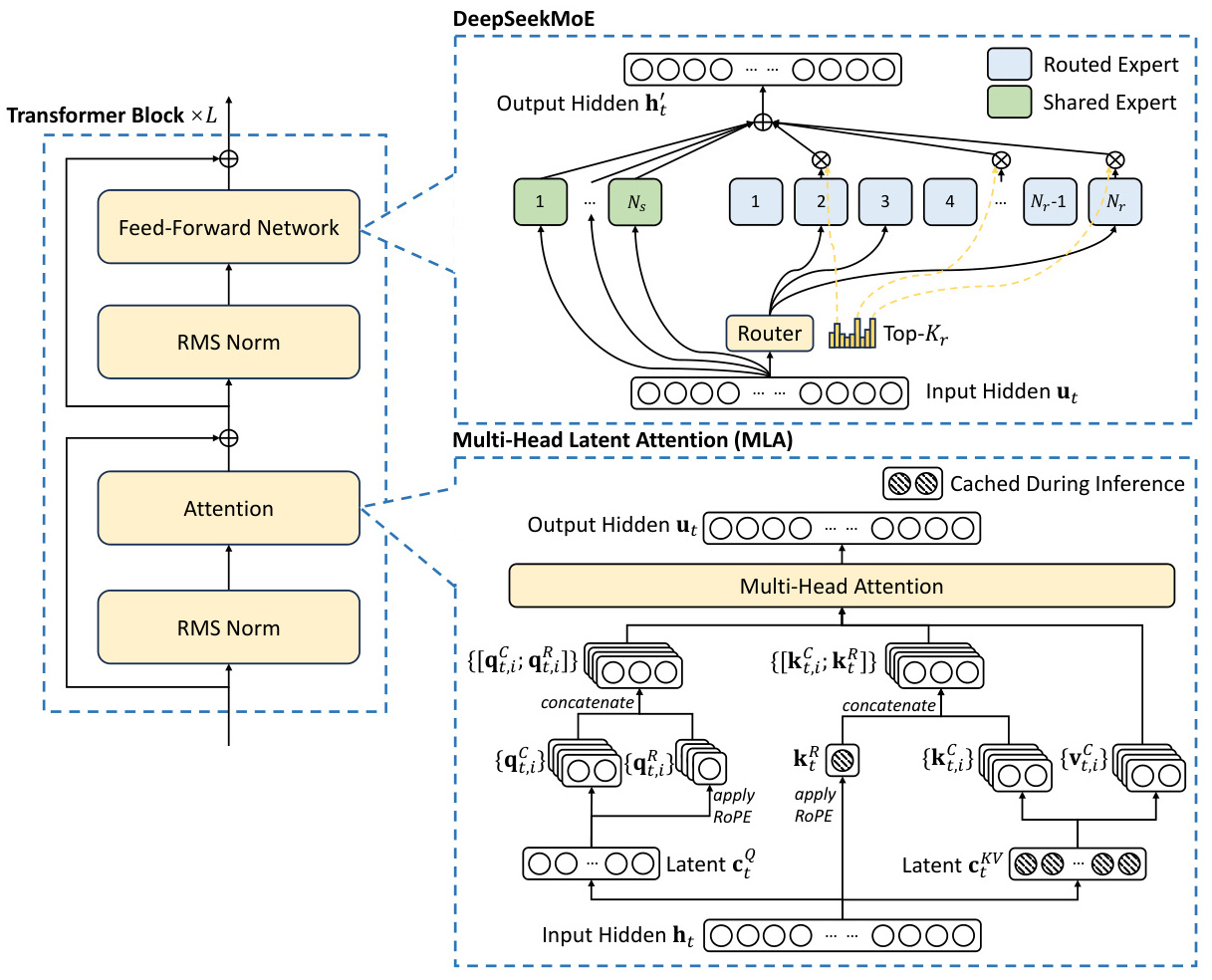
此外,MLA还通过减少KV缓存的需求,进一步优化了推理性能。 -
DeepSeekMoE稀疏结构:DeepSeekMoE是一种混合专家模型,通过细粒度专家分割和共享专家隔离策略,将计算资源分配给最相关的专家,从而捕捉通用信息和针对性信号。这种稀疏结构不仅减少了参数冗余,还降低了整体计算量,使得模型在保持强大性能的同时,显著降低了训练和推理成本。
-
性能与成本优势:DeepSeek-V2通过MLA和DeepSeekMoE的结合,实现了跨级别的性能提升。例如,在中文和英文综合能力测试中,DeepSeek-V2的表现与GPT-4-Turbo相当,甚至在某些领域超越了其他开源模型。同时,其API调用成本仅为GPT-4-Turbo的百分之一,显示出极高的性价比。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











