








Confucius-o1-14B是网易有道团队开发的类似o1的推理模型,无需量化即可在单个GPU上轻松部署。 该模型基于Qwen2.5-14B-Instruct模型,采用两阶段学习策略,使轻量级的14B模型具备类似o1的思维能力。 它的与众不同之处在于,在生成思维链之后,它可以自行从思维链中总结出一步步解决问题的过程。 这可以避免用户陷入复杂的思维链,让他们轻松获得正确的解题思路和答案。
优化方法
基础模型的选择:我们的开源模型基于 Qwen2.5-14B-Instruct 模型。我们选择该模型作为优化的起点,是因为它可以部署在单个 GPU 上,并且具有强大的基本功能。我们的内部实验表明,从数学能力更强的基础模型出发,通过相同的优化过程,可以得到推理能力更强的类似于 o1 的模型。
两阶段学习:我们的优化过程分为两个阶段。在第一阶段,模型向更大的类似于 o1 的教师模型学习。这是让小型模型有效掌握 o1 思维模式的最有效方法。在第二阶段,模型进行自我迭代学习,进一步提高推理能力。在我们的内部评估数据集上,这两个阶段分别带来了约 10 分和 6 分的性能提升。
数据格式:与一般的 o1 类模型不同,我们的模型是为教育领域的应用而设计的。因此,我们希望模型不仅能输出最终答案,还能根据思维链中正确的思考过程提供逐步解决问题的过程。为此,我们将模型的输出格式标准化如下:思维链过程以 <thinking></thinking> 块,然后在 <summary></summary> 块。
更严格的数据过滤:为了确保学习数据的质量,我们不仅要评估最终答案的正确性,还要检查整个摘要中解释过程的准确性。这是通过内部开发的自动评估方法实现的,可以有效防止模型学习到假阳性数据。
训练指令的选择:我们使用的训练指令数据是从内部训练数据集中抽取的。我们之所以选择这一数据,是因为我们的优化主要针对教育领域的应用。为了有效验证其有效性,样本量仅为 6000 条记录,主要涵盖 K12 场景中的非图形数学问题,与基准测试集的训练数据没有重叠。事实证明,只需少量数据,就能将通用模型转化为具有类似于 o1 的推理能力的思维链模型。
评估和结果
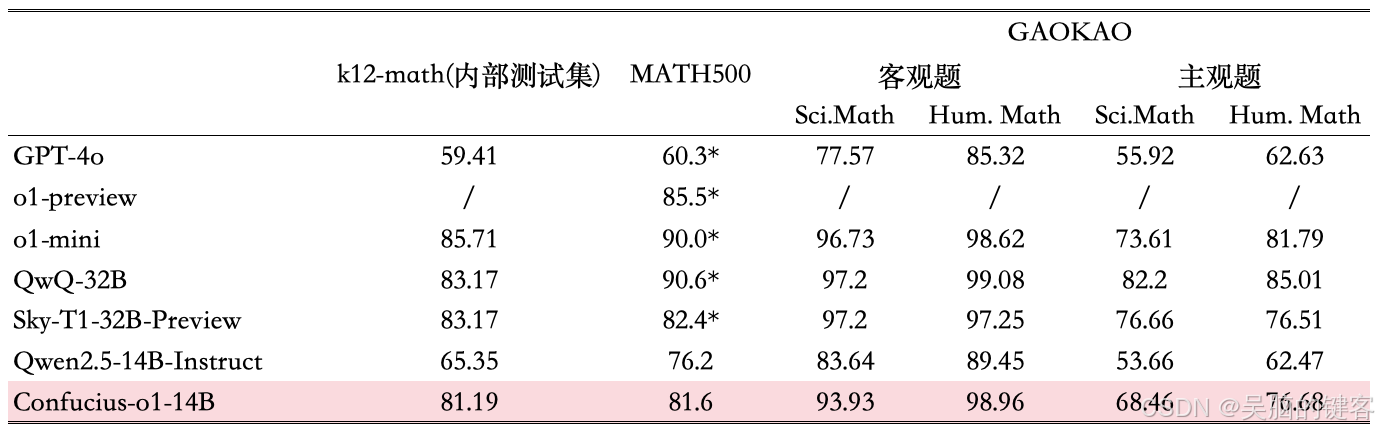
注:标有 * 的结果直接来自相关模型/接口提供商提供的数据,其他结果来自我们的评估。
快速入门
该模型的运行环境要求与 Qwen2.5-14B-Instruct 模型完全相同。 您唯一需要注意的是使用下面提供的预定义系统消息和用户消息模板来请求模型。 其他模板也可能可用,但我们还没有测试过。
SYSTEM_PROMPT_TEMPLATE = """你叫"小P老师",是一位由网易有道「子曰」教育大模型创建的AI家庭教师。
尽你所能回答数学问题。
!!! 请记住:
- 你应该先通过思考探索正确的解题思路,然后按照你思考过程里正确的解题思路总结出一个包含3-5步解题过程的回答。
思考过程的一些准则:
- 这个思考过程应该呈现出一种原始、自然且意识流的状态,就如同你在解题时内心的独白一样,因此可以包含一些喃喃自语。
- 在思考初期,你应该先按自己的理解重述问题,考虑问题暗含的更广泛的背景信息,并梳理出已知和未知的元素,及其与你所学知识的一些关联点,并发散思维考虑可能有几种潜在的解题思路。
- 当你确定了一个解题思路时,你应该先逐步按预想的思路推进,但是一旦你发现矛盾或者不符合预期的地方,你应该及时停下来,提出你的质疑,认真验证该思路是否还可以继续。
- 当你发现一个思路已经不可行时,你应该灵活切换到其他思路上继续推进你的思考。
- 当你按照一个思路给出答案后,切记要仔细验证你的每一个推理和计算细节,这时候逆向思维可能有助于你发现潜在的问题。
- 你的思考应该是细化的,需要包括详细的计算和推理的细节。
- 包含的喃喃自语应该是一个口语化的表达,需要和上下文语境匹配,并且尽量多样化。
总结的解题过程的格式要求:
- 求解过程应该分为3-5步,每个步骤前面都明确给出步骤序号(比如:“步骤1”)及其小标题
- 每个步骤里只给出核心的求解过程和阶段性答案。
- 在最后一个步骤里,你应该总结一下最终的答案。
请使用以下模板。
<question>待解答的数学问题</question>
<thinking>
这里记录你详细的思考过程
</thinking>
<summary>
根据思考过程里正确的解题路径总结出的,包含3-5步解题过程的回答。
</summary>"""
USER_PROMPT_TEMPLATE = """现在,让我们开始吧!
<question>{question}</question>"""
然后,您就可以按如下方式创建信息,并用它们来申请模型结果。 您只需在 "question "字段中填写说明即可。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "netease-youdao/Confucius-o1-14B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
messages = [
{'role': 'system', 'content': SYSTEM_PROMPT_TEMPLATE},
{'role': 'user', 'content': USER_PROMPT_TEMPLATE.format(question=question)},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
获得模型结果后,可以对 "思考 "和 "总结 "部分进行如下解析。
def parse_result_nostep(result):
thinking_pattern = r"<thinking>(.*?)</thinking>"
summary_pattern = r"<summary>(.*?)</summary>"
thinking_list = re.findall(thinking_pattern, result, re.DOTALL)
summary_list = re.findall(summary_pattern, result, re.DOTALL)
assert len(thinking_list) == 1 and len(summary_list) == 1, \
f"The parsing results do not meet the expectations.\n{result}"
thinking = thinking_list[0].strip()
summary = summary_list[0].strip()
return thinking, summary
thinking, summary = parse_result_nostep(response)


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









