







GPT-4o图像生成评估: 首次在三个成熟的基准测试中对GPT-4o的图像生成能力进行定量和定性评估,包括文本到图像的生成(GenEval)、编辑(Reason-Edit)和基于世界知识的语义生成(WISE)。我们的综合结果表明,GPT4o的图像生成和理解能力优于以前的模型。
生成架构分析:基于基准测试结果,我们对 GPT-4o 的潜在底层架构进行了深入分析。通过基于分类器的图像分析调查,我们确认解码器最有可能是一种 Diffusion 架构,并给出了一种潜在的编码器范式推测。
更详细的分析:我们对 GPT-4o 生成结果进行了详细分析,并对其弱点进行了系统的实证研究,包括常见的故障模式和生成伪影。此外,我们还利用现有的 SOTA 图像取证模型评估了 GPT-4o 生成的图像的可检测性,从而探讨了 AIGC 的安全性问题。
我们上传了 Reason-Edit 和 GenEval 数据集的 GPT 生成结果,可在此处下载。
我们还将在这两天上传我们的自动脚本,以方便更多人评估 GPT-4o 的图像合成能力。

🔥评估结果
从表中可以看出,GPT4o 的总得分最高,达到 0.84 分,在很大程度上优于冻结文本编码器方法和 LLM/MLLM 增强方法。
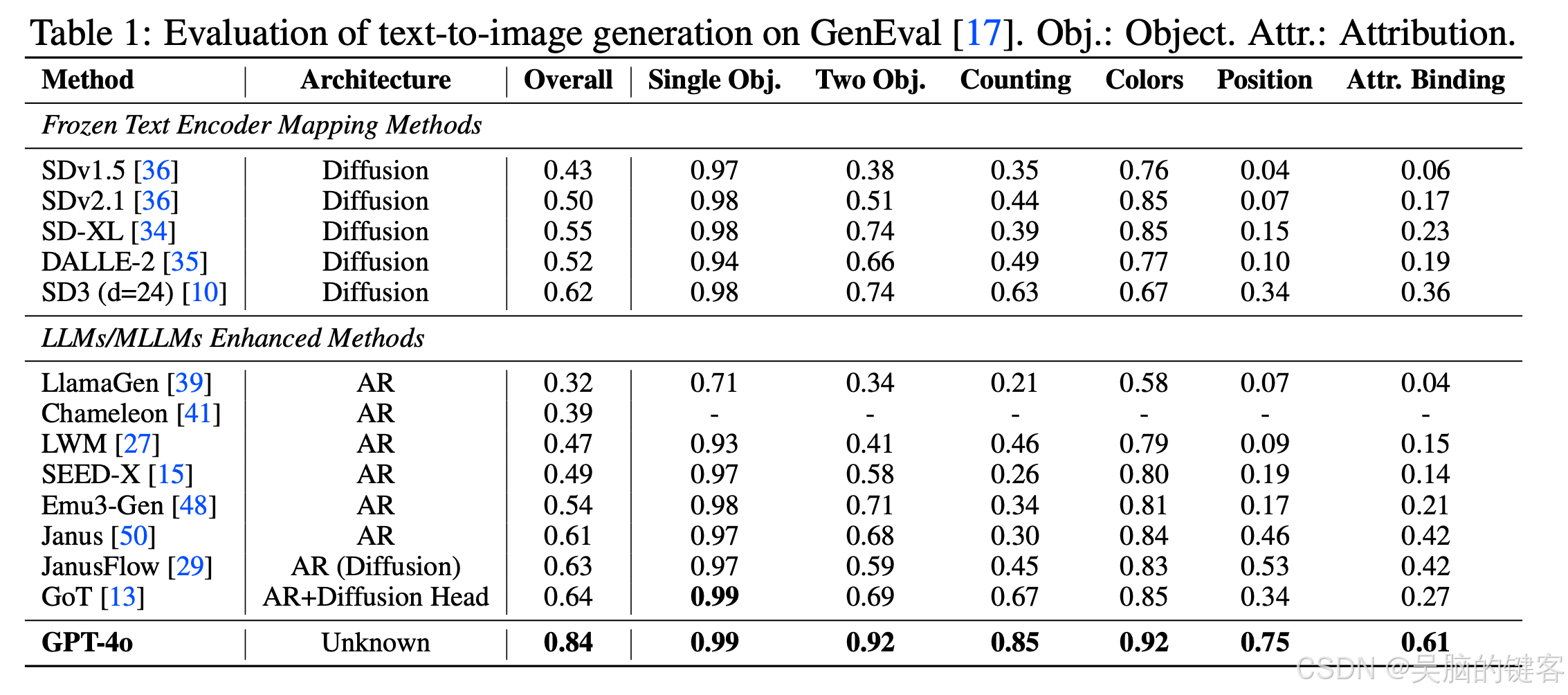
图中展示了 GPT-4o 在 GenEval 基准的六个核心评估类别中的合成文本到图像生成能力的定性示例。

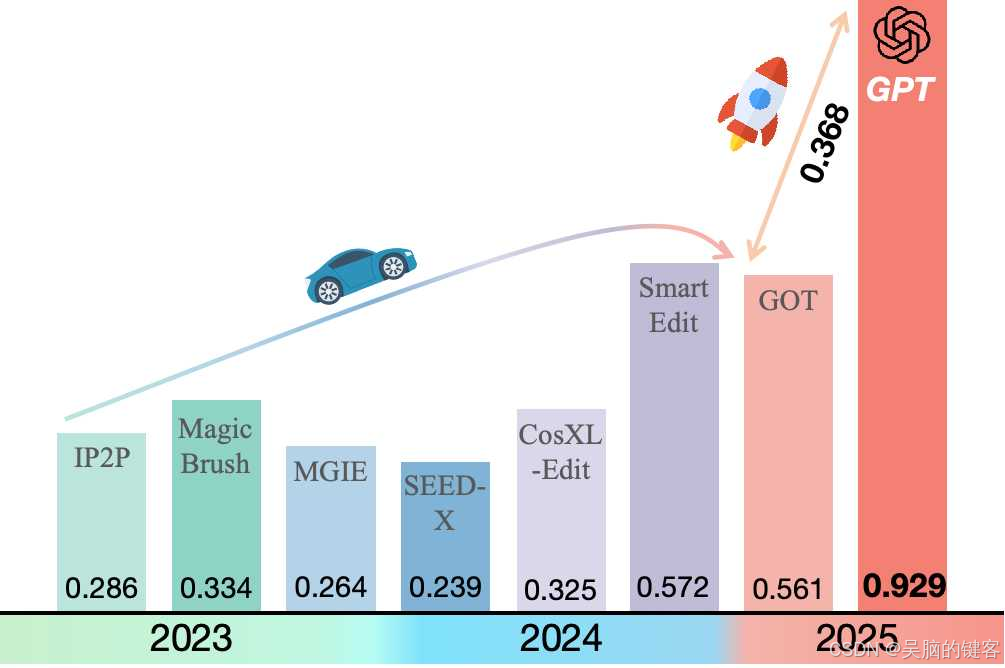
如柱状图所示,GPT-4o 在 Reason-Edit 基准测试中的表现明显优于现有的所有图像编辑方法,取得了 0.929 的优异成绩。这比 2025 年之前表现最好的方法(SmartEdit,0.572)大幅提高了 0.357 分,凸显了该模型强大的指令遵循能力和精细的编辑控制能力。
就总体 WiScore 而言,GPT-4o 明显优于现有的专业 T2I 生成方法和基于 MLLM 的统一方法。GPT-4o 将卓越的世界知识理解与高保真图像生成相结合,展示了在多模态生成任务中的双重优势。
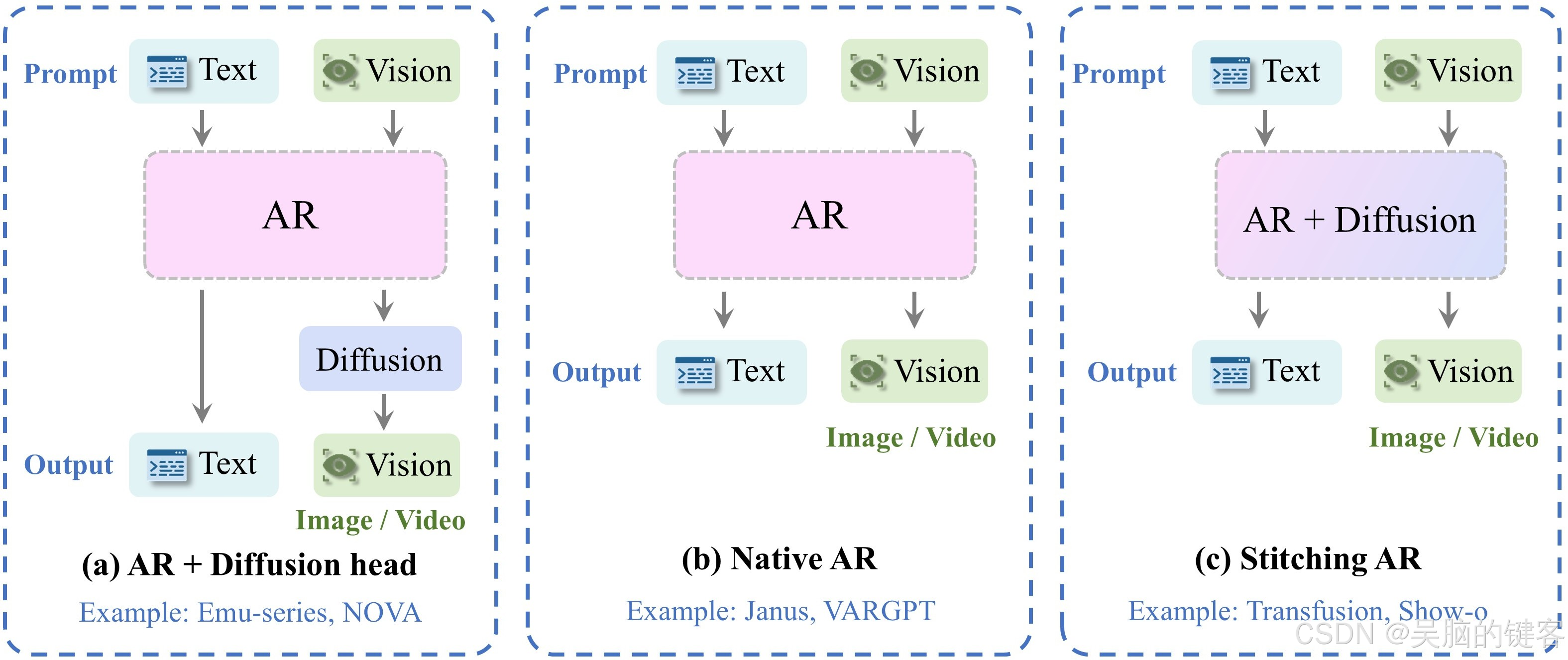
🤔生成架构
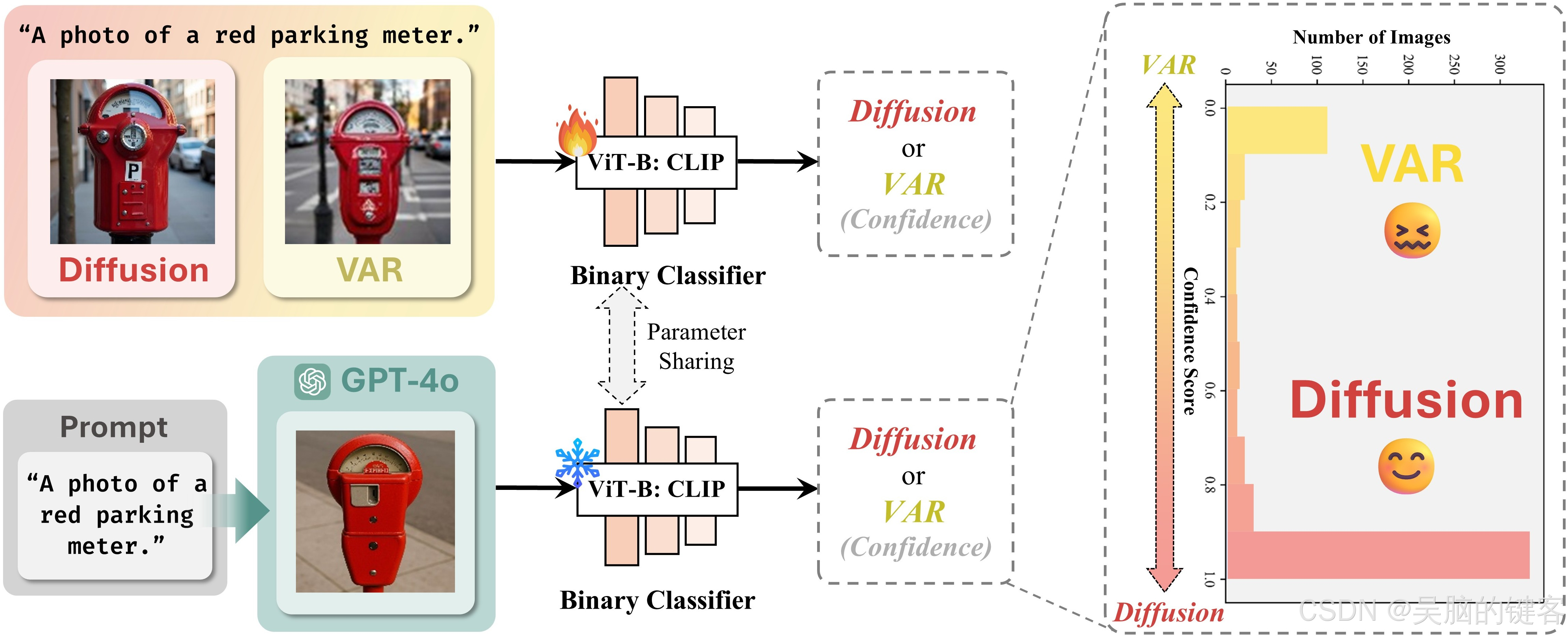
除了基准评估,我们还进行了更深入的分析,以揭示 GPT-4o 潜在的架构选择。具体来说,我们首先探索 GPT-4o 是依赖于基于扩散的解码器头还是自回归解码器头。为此,我们提出了一种基于模型的分类方法,即训练一个标准二元分类器来区分两种范式生成的图像,然后将其应用于 GPT-4o 的输出。有趣的是,分类器始终将 GPT-4o 的图像分类为基于扩散的图像,这为 GPT-4o 可能在内部使用扩散头进行图像解码提供了经验证据。


















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









