







我们提出了一种基于内适配器架构(Inner-Adaptor Architecture,IAA)的 MLLM。IAA 证明,在多模态理解和视觉接地任务中,使用冻结语言模型进行的训练可以超越使用微调 LLM 的模型。此外,在部署之后,我们的方法结合了多个工作流程,从而保留了语言模型的 NLP 能力。只需下载一次,就能对模型进行微调,以满足各种任务规范的要求。享受我们的 IAA 模型带来的无缝体验。
🔥 新闻
- [2025/04/15] IAA已被AAAI2025接受!
(https://ojs.aaai.org/index.php/AAAI/article/view/35400). - [2024/08/29] 我们把 IAA 放在拥抱脸社区上!🤗.
- [2024/08/29] 我们更新了 IAA github 代码库,现在您可以测试我们的模型了!
- [2024/08/26] 我们发布了论文:IAA: Inner-Adaptor Architecture。
安装
conda create -n IAA python=3.10 -y
conda activate IAA
bash deploy.sh
模型性能
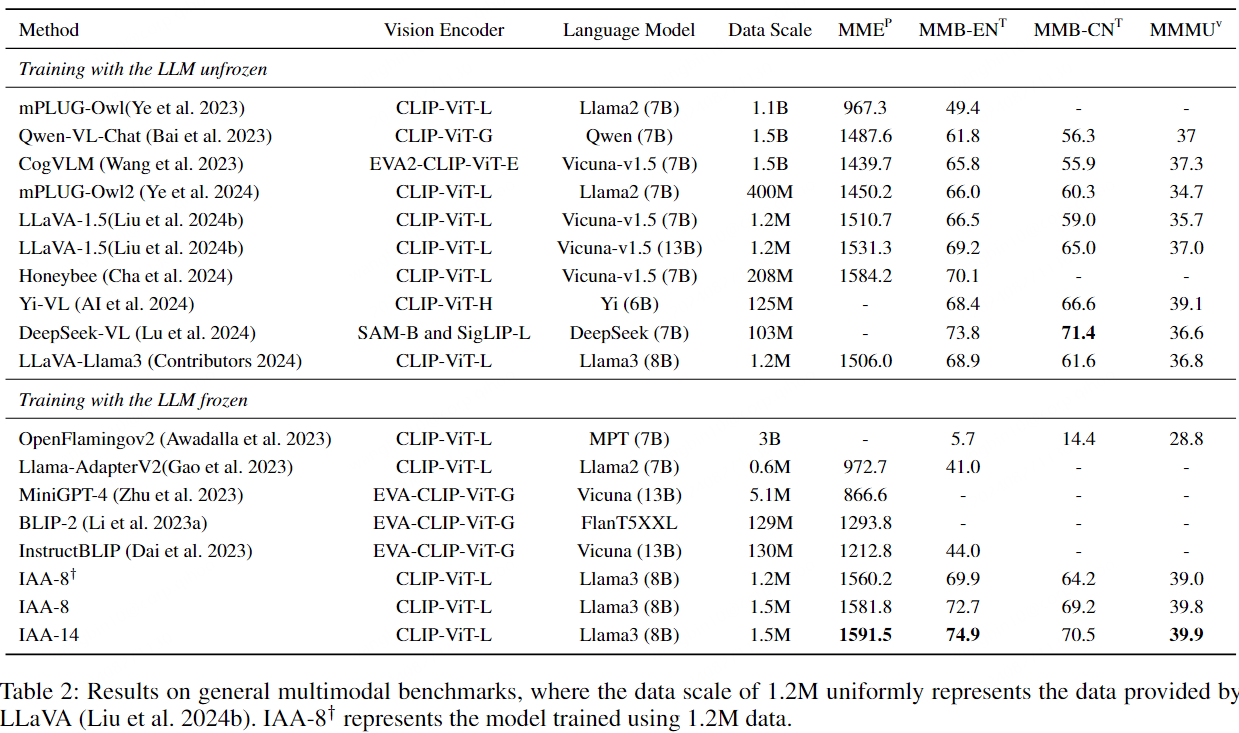
一般多模式基准的主要结果。
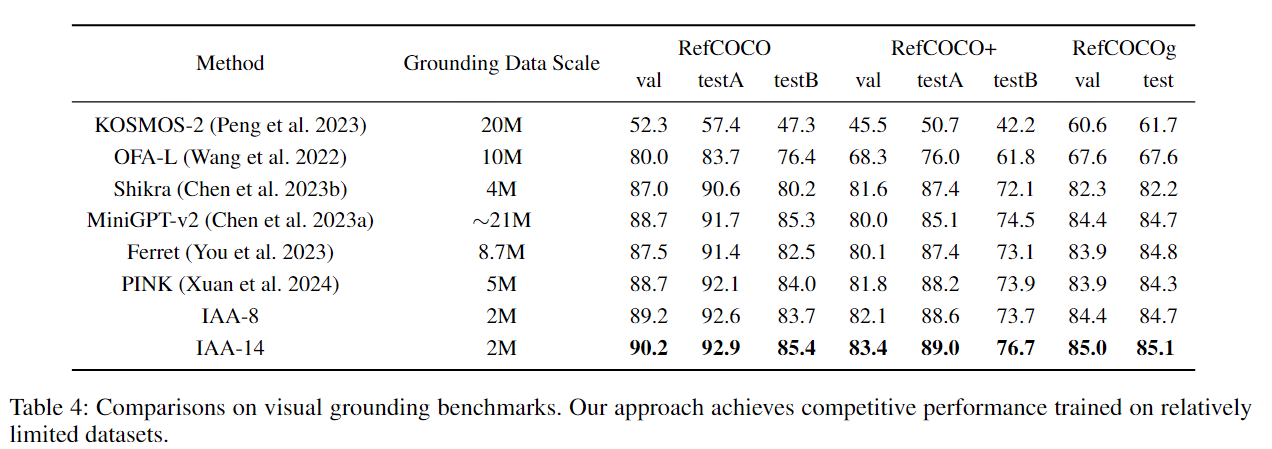
视觉接地基准测试结果。
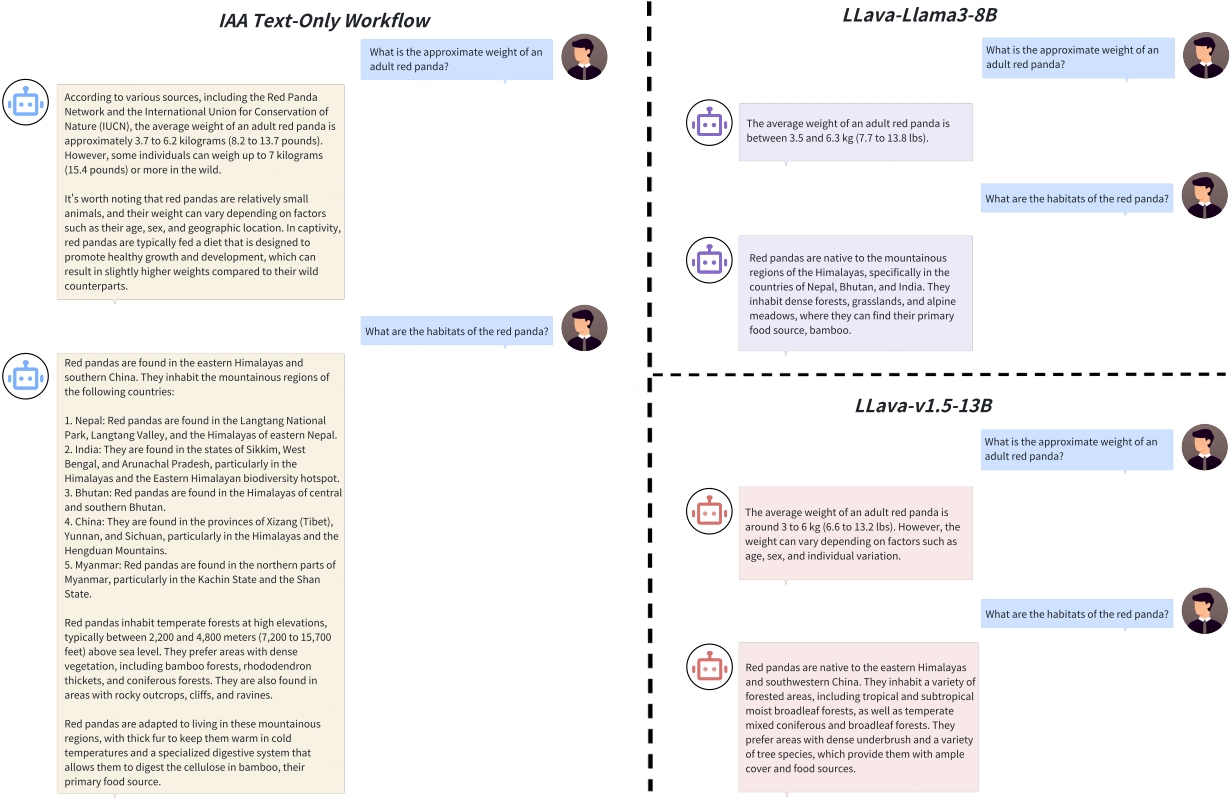
纯文本问题解答比较。
快速上手🤗
首先拉下我们的模型
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from PIL import Image
checkpoint = "qihoo360/Inner-Adaptor-Architecture"
model = AutoModelForCausalLM.from_pretrained(checkpoint, torch_dtype=torch.float16, device_map='cuda', trust_remote_code=True).eval()
tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
vision_tower = model.get_vision_tower()
vision_tower.load_model()
vision_tower.to(device="cuda", dtype=torch.float16)
image_processor = vision_tower.image_processor
tokenizer.pad_token = tokenizer.eos_token
terminators = [
tokenizer.convert_tokens_to_ids("<|eot_id|>",)
]
多模式工作流程: task_type=“MM”
image = Image.open("readpanda.jpg").convert('RGB')
query = "What animal is in the picture?"
inputs = model.build_conversation_input_ids(tokenizer, query=query, image=image, image_processor=image_processor)
input_ids = inputs["input_ids"].to(device='cuda', non_blocking=True)
images = inputs["image"].to(dtype=torch.float16, device='cuda', non_blocking=True)
output_ids = model.generate(
input_ids,
task_type="MM",
images=images,
do_sample=False,
eos_token_id=terminators,
num_beams=1,
max_new_tokens=512,
use_cache=True)
input_token_len = input_ids.shape[1]
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
outputs = outputs.strip()
print(outputs)
接地工作流程: task_type=“G”
image = Image.open("COCO_train2014_000000014502.jpg").convert('RGB')
query = "Please provide the bounding box coordinate of the region this sentence describes: dude with black shirt says circa."
inputs = model.build_conversation_input_ids(tokenizer, query=query, image=image, image_processor=image_processor)
input_ids = inputs["input_ids"].to(device='cuda', non_blocking=True)
images = inputs["image"].to(dtype=torch.float16, device='cuda', non_blocking=True)
output_ids = model.generate(
input_ids,
task_type="G",
images=images,
do_sample=False,
eos_token_id=terminators,
num_beams=1,
max_new_tokens=512,
use_cache=True)
input_token_len = input_ids.shape[1]
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
outputs = outputs.strip()
print(outputs)
纯文本工作流程: task_type=“Text”
query = "What is the approximate weight of an adult red panda?"
inputs = model.build_conversation_input_ids(tokenizer, query=query)
input_ids = inputs["input_ids"].to(device='cuda', non_blocking=True)
images = None
output_ids = model.generate(
input_ids,
task_type="Text",
images=images,
do_sample=False,
eos_token_id=terminators,
num_beams=1,
max_new_tokens=512,
use_cache=True)
input_token_len = input_ids.shape[1]
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
outputs = outputs.strip()
print(outputs)
CLI 推断
使用 IAA 聊天,无需 Gradio 界面。
name="qihoo360/Inner-Adaptor-Architecture"
python -m iaa.eval.infer \
--model-path $name \
--image-path testimg/readpanda.jpg \
--task_type MM \
name="qihoo360/Inner-Adaptor-Architecture"
python -m iaa.eval.infer_interleave \
--model-path $name \
--image-path testimg/COCO_train2014_000000014502.jpg \
评估
首先,从以下链接下载 MME 映像:./MME/MME_Benchmark_release_version. https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation
bash scripts/mme.sh
关于 Refcoco 测试,请参考以下链接下载数据 https://github.com/lichengunc/refer
bash scripts/refcoco.sh
Github: https://github.com/360CVGroup/Inner-Adaptor-Architecture/tree/main?tab=readme-ov-file
Huggingface: qihoo360/Inner-Adaptor-Architecture



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









