









Object:
执行 布线前的检查和设置
使用 route_auto 布线signal nets
报告 修复 DRC 的违例
优化设计使用route_opt
布线阶段的目标 (routing phase goal)
布局和时钟树综合此时应该是完成的;
可接受的拥塞 setup/hold time 以及逻辑DRCs
时钟树网络已经被布线了;
布线阶段的目标是:
在最小化物理DRC违例情况下 将所有的signal nets 布线
选择性的执行 布线后的 时钟树优化或者CCD;
优化数据路径逻辑的 时序 DRCs 以及功耗;
ICC II 的布线流程;
布线流程 包含几个关键的步骤:
- 布线前的检查和设置
- signal route
- 优化和二次布线;
建议的布线流程
时钟树的布线应该是已经完成的;
signal nets 被首次布线 -no cell optimization
route_auto
# 命令执行的三个阶段:
# GLOBAL routing - track assignment - detail routing
# 只是把cells 连起来 修physical DRC 不会插buffer 不会进行gate sizing
然后, 执行布线后的优化
route_opt
# 并行优化 时序& max-tran/max-cap | 时钟树 功耗 (可选择的) | 选择性的使用PrimeTime 计算delay 以及starRC提取 RC 及寄生参数;
# 之后再想重新route的话 就需要使用 route ECO 布线优化 更新布线信息
# 如果route_opt 之后还是存在较多的 max-tran max-cap 的违例 就需要考虑 是不是cell之间里的太远 导致的(detours 绕路) 需要重新摆放cells 或者回到CTS 看这些clock cell的位置
布线的执行: GLOBAL route (GR)
GR 并不是真正的布线 而是在GRC or Gcells (global route cell)上的 考虑拥塞的布线,为每个net基于金属层的优先布线方向分配layer;
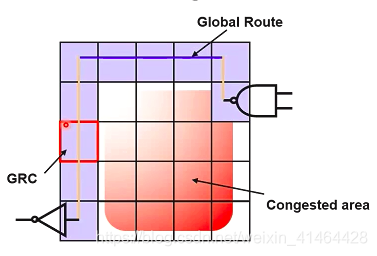
NO metal traces are created ; 使用的0宽度的带颜色的线去标记全局的布线,分配使用的金属层;
GR 会在最小化detours 的情况下 去避免congestion的产生;
Detour 会造成线网的延迟增加;
GR 会避免布线在 P/G net区域以及用户设置的routing blockage;
在GUI上看 GR 的结果 :是没有宽度的细线
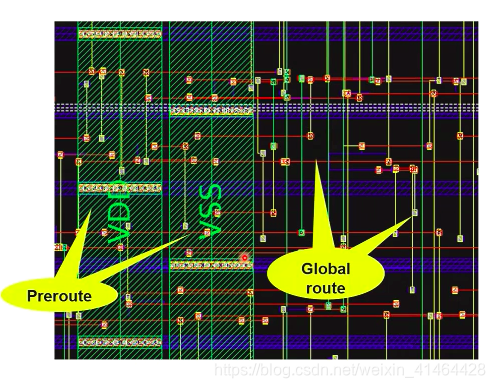
布线的执行: Track Assignment (track 分配) TA
TA 的主要任务就是为GR 的布线 分配真实的金属形状;
会尽力将track 弄的尽量长而直;
减少通孔的使用;
在 TA 之后 所有的线都是布好了的, 但是并不是仔细严谨的,会有很多违例,特别是在连接pin脚的地方, detail_route 会解决这些违例;
布线的执行 : detail routing 详细布线
DR 会修复布线的物理DRC违例;
执行多次迭代,
routing之前的检查
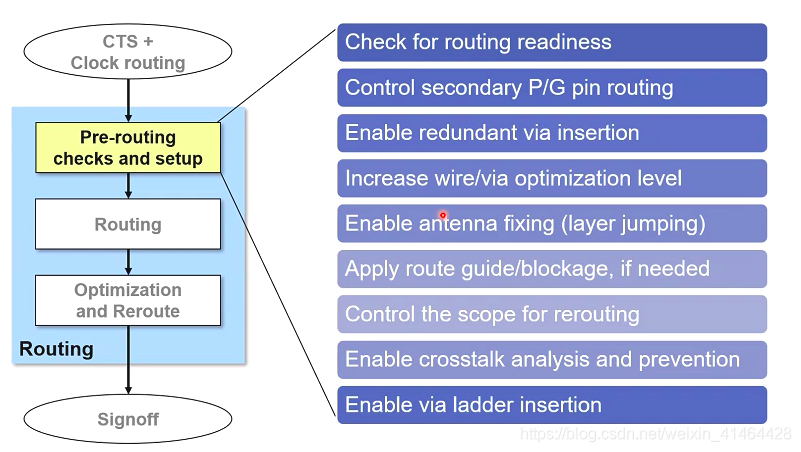
检查布线的准备情况
# 运行检查 确保设计已经准备好布线
check_design -checks pre_route_stage
check_routability
# 上面的检查比较多, 适用于不同工具传递后的检查 如果全流程都用ICC II 仅使用check_routability即好;
# 检查 有没有port被block住, out_boundary pin(边界之外的pin)
# 检查 pin access edge rules honored
# 检查 minimum-grid violation
Secondary P/G pin 的连接
PG pin 除了在rail上的那些 不需要布线的primary power / ground pin 之外 还有 Secondary Power pin
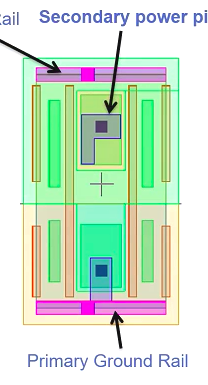
这些 Secondary P/G pin 是需要被首先布线的;
route_group -nets {VDDH}
# 默认 没有设置 最大的 PG pin 连接到power strap的via 的数量, 但是毕竟在底层, 布线资源比较紧张, 可选择设置maximum value 基于自己设计的电源网格;
set_app_options -value 4 -name route.commom.number_of_secondary_pg_pin_connections
NDRs for Secondary PG routing
为Secondary PG 应用NDRs 并不是不寻常的,
set_app_options -value true -name route.commom.separate_tie_off_from_secondary_pg
create_routing_rule sec_pg \
-width {M1 0.2 M2 0.2 M3 0.2}
-vias {...}
set_routing_rule {VDDH} -rule sec_pg \
-min_routing_layer M2
-max_routing_layer M3
route_group -nets {VDDH}
为signal nets 插入多余的vias;
将单个的(single-cut)vias替换为 multiple-cut via array (多次切割的通孔组) 或者另外有更好的解除方式(better contact code )
默认 单个的via 会被 两个的 via 组所替换;
使用 add_via_mapping 来进行定制化的via mapping
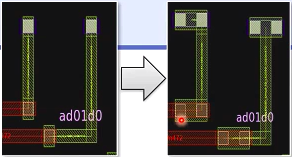
# 打开redundant via 的insertion ; 这种转换发生在每次 detail route ;
route.common.post_detail_route_redundant_via_insertion default: off -> medium
# 基于 redundant via insertion
redundant Vias & small Geometries (更小的几何大小)
在更先进的工艺,更小的几何宽度(<20nm),为了提高DRC convergence (集中度) 以及最小化设计的运行时间, 建议的流程是先保留redundant via 的空间(reserve space);然后在detail_route之后单独运行 add_redundant_vias
set_app_aptions -list {
route.common.post_detail_route_redundant_via_insertion off
route.commom.concurrent_redundant_via_mode reserve_space
route.commom.eco_route_concurrent_redundant_via_mode reserve_space
}
route_auto
route_detial -incremental true
add_redundant_vias
...
# 在运行完布线后的优化之后在执行一次
# 在RVI 之前需要确保 设计中没有布线的DRC存在;
route_opt
add_redundant_vias
打开 wire & Via 的优化
为了减小detour, Via & wire optimization 是建议在使用adding redundant vias 执行的;工具会尽力获得更长而知的traces, 去减少via 的数量;
set_app_options -value high -name route.detail.optimize_wire_via_effort_level
# 默认情况下 是low
# 建议在 route_auto之后 使用指令单独执行一次 via&wire的优化;
optimize_routes
天线效应的修复(antenna fixing) : layer jumping
在更先进的工艺尺寸,更小的栅极距离,更多的金属层的使用,会导致更容易产生天线效应;
解决天线效应的方法: layer jumping diode insertion 跳层 和插入反偏二极管;
layer jumping 建议在 detail route 阶段使用;
二极管的插入建议在布线之后使用;
默认情况下,layer jumping是在detail route阶段打开的;
需要以TCL 脚本的方式 提供antenna rules文件
source antenna_rules.tcl
# 下面的天线选项是默认的设置
route.detail.antenna true
route.detail.antenna_fixing_preference hop_layer
route.detail.hop_layers_to_fix_antenna true
# 除此之外还有好多 与天线效应相关的设置项
默认情况下, doide insertion 是没有打开的;
控制布线器的行为: Routing Guides
使用 routing guide 你可以改变指定范围内的默认的route behavior(布线行为) ,改变优先的布线方向;
create_routing_guide -name rg_0 -boundary {{270 340}{491 385}} \
-layers {M6} -switch_preferred_direction
还可用来改变 trace的利用率;
阻碍布线: route blockage;
防止在特定区域的signal route 可以定义一个routing blockage;
routing guides 以及 blockages 的定义需要在 place_opt 之前应用掉 ,它会在 global route的时候被完整的遵守;
控制rerouting的范围
默认 布线器是允许为所有 pre-route的nets 重新布线的; 除非形状被 route_custom 标记为 user_route ;
为了控制二次布线的范围 设置线网上的physical_status 属性;
set_attribute <nets> physical_status UNrestricted | minor_change | locked
Timing driven routing 时序驱动的布线
打开 timing-driven 布线选项 timing-critical 的路径会被布线器优先考虑;
set_app_options -list {
route.global.timing_driven true
route.track.timing_driven true
route.detail.timing_driven true
}
# 你可以使用以下选项 控制 timing-driven的 effort
route.global.timing_driven_effort_level default : high
# 高的effort 会使 对于时序的考虑会高于congestion; 为了得到更好的DRC 的结果 可以尝试将选项的effort 改低一点 low 或者medium;
crosstalk analysis串扰分析
打开crosstalk delta delay;
delta delay影响setup hold time;
会影响路径的时序,因此会影响时序驱动的布线;
set_app_options time.si_enable_analysis -value true
# delta delay 的计算会把timing arrival Window 纳入计算
time.enable_si_time_windows

crosstalk prevention串扰的预防
预防串扰发生在布线的整个阶段;
route_auto
# 会避免在临近的tracks上放置长平行的nets;
# 建议仅在 track assignments 阶段打开crosstalk prevention;
set_app_options -name route.global.crosstalk_driven -value false
set_app_options -俺么 route.track.crosstalk_driven -value true
# 在global routing阶段就打开 crosstalk prevention 可能会导致mixed results;
static noise (静态噪声)
噪声的分析 在SI 中也是enable的
time.si_enable_analysis
# 使用CCSN library
# 支持设置用户定义的 noise margin(set_noise_margin)
# 噪声的优化 当前并不是有效的 需要手动去修 (咋个修法 不知道)
report_noise
在ICC II中调用 Prime Time ;
为了提高延迟计算的准确度在ICC中调用PrimeTIme;
# 在时序分析期间使用 Synopsys CCS receiver capacitance model(RC 模型??)
set_app_options -俺么 time.enbale_ccs_rcv_cap -value true
# 打开 基于CCS 的波形的分析 (需要 有composite current source timing 以及CCS noise data的库)
set_app_options -name time.delay_calc_waveform_analysis_mode -value full_design
# 联合 Prime Time 和波形分析法则;
set_app_options -俺么 time.awp_compatibility_mode -value false
CCS 耦合电流源??
timing window的模型比较准确
via ladders (通孔梯子)/ via pillars(通孔柱子)
最初工艺层 最底层金属线用铝线,随着工艺要求的不断提高,现在底层一般使用铜线; 铜线越来越细,铜截面与金截面的电子散射效应会越来越明显;随着铜线宽度越来越小 电阻也是呈指数增加的;底层绕线越来越接近一维绕线;
一个更好的pitches:
电阻:
regularity: 规则性
标准单元设计:
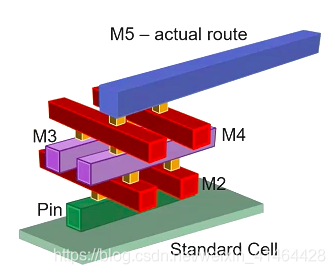
via ladder 就是从pin 那一层向上由通孔堆叠而成的;有布线器以提高EM的稳健性以及减少关键路径的via的电阻为目的动态的创建;
多目的种类的via ladders
via ladder 分很多类, 主要是为了EM 以及performance;
每一类又分很多不同的配置以及possibilities;
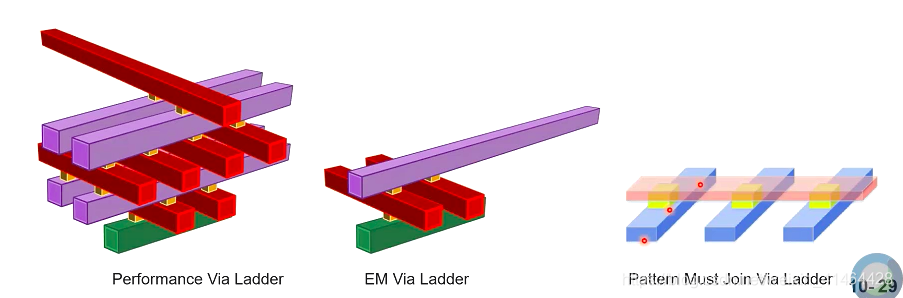
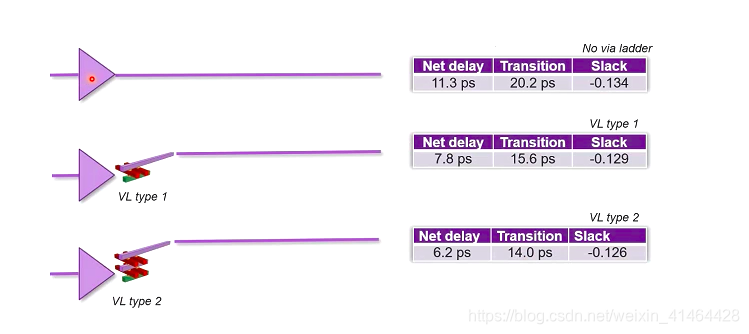
via ladder 的定义
via ladder 是在techfile中定义的 使用 viarules 或者使用TCL (create_via_rule) 来自己创建 via ladder;
一个可用的VL candidates 列表会提供给库单元的引脚;
一般是由library vendor 提供的;
via ladder 实现的流程;
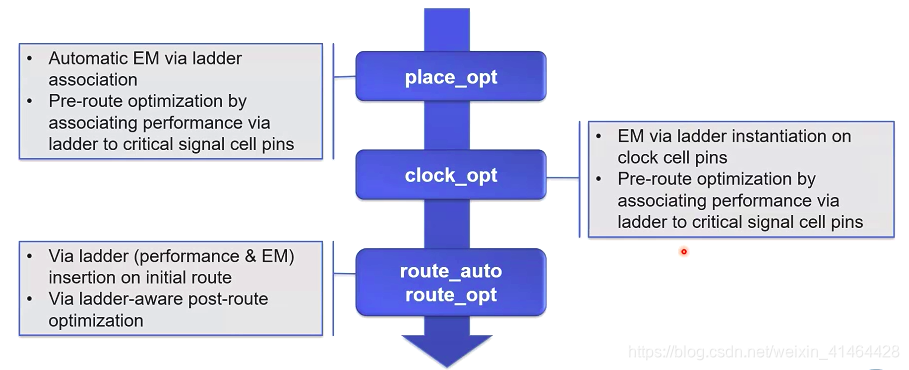
执行via ladder 的插入
EM VLs 是需要工艺文件 以及pin 上的定义;
performance via ladder 是和优化相关联的或者说是嵌入到关键路径的pin 有最小布线层约束的nets的pin的优化之中的;
# 打开 performance via ladder insertion
opt.commom.enable_via_ladder_insertion
# 默认情况下是关闭的
# via ladder 的插入发生在 place_opt 以及 clock_opt 的final_opto阶段
# 发生在 ropute_opt 的最后;
时钟网络的 performance & EM ladder 的插入
在执行完 CTS之后 在执行CT的布线之前 插入 performance & EM的 via ladder;
clock_opt -from build_clock -to build_clock
insert_via_ladeders -nets <clock_nets>
clock_opt -from route_clock -to route_clock
via ladder 的插入和更新
#如果 enable 的话 via ladder 在 route_auto 的最开始就插入了;
route.auto_via_ladder.update_during_route
# 默认情况下是关闭的;
# 如果 enable 的话 VLs 也会在 GR TA DR 运行的时候 进行更新;
# 利用 VLs 解决一些violation;
# 查看所有和 via_ladder相关的 application options
report_app_options *via_ladder*
routing & DRC fixing (布线以及DRC 的修复)
flow
布线阶段大致分以下三个步骤
routing signal nets
check DRCs
incremental routing (增量布线)
routing signal nets
# the main common
route_auto
# 或者分别执行下面三个指令 对应布线的是三个阶段
route_global
route_track
route_detail
# 根据需要在布线之前 修改 crosstalk options routing guides via mapping rules and reroute 的选项
detail route 的迭代;
默认情况下 , route_auto 会执行最大 40次的 iteration (迭代) 去修复DRC的问题;
# 如果你所用的工艺需要更多的 iterations 通过以下选项设置
route_auto -max_detail_route_iteration 60
检查布线的DRC 违例
check_routes
# 检查 signal & clock nets 的 物理DRC NDR shorts oprns antenna 以及 voltage area 的违例
# 不会检查 那些 pre_route 的nets 比如 P/G grid 结构
# 这里的结果 并不是很精确的, 还需要使用calibre
查看单元的内部结构
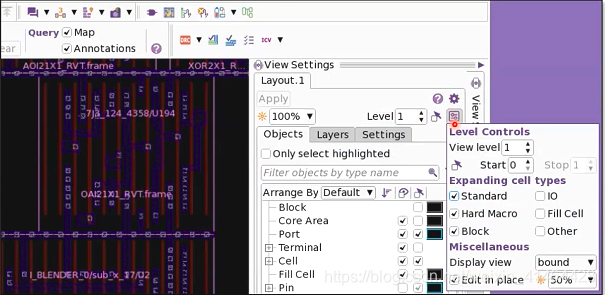
仅仅是提高 view level的等级 是看不到 cell 的internal instruction的
你需要打开标准单元和宏单元的 expanding cell types
layout vs schematic 的检查
使用 check_lvs 检查 open short 以及 floating 的nets ; 由于不会检查 DRC所以会很快; 使用 error browser 展示找到的错误;
check_lvs -checks all -open_reporting detail -check_child_cells true
# 能够使用GUI界面去定位 测物发生的地点;
detail route 的循环
运行附加的detail route 迭代 去修复DRC 的违例;
route_detail -incremental true -max_number_iteration 50 -coordinates {{}{}指定范围}
改变 布线选项
很多 detail route 以及一般的布线选项会影响布线的行为
# 以下面的关键词开头的app_options
report_app_options route.detail.*
report_app_options route.commom.*
#例如下面控制 花费在修复宏单元的shorts 的effort
set_app_options route.detail.repair_shorts_over_macros_effort_level -value off|low|medium|high
route_detail -incremental
对有问题的 nets 进行reroute
# 对于那些有DRC问题的nets 由于跳层产生的巨大的delay 以及 串扰的违例 都能通过 reroute 得到优化
# 使用 移除detail route
remove_nets
# 使用 重新布线
reroute_eco
# 要记得 你可以锁住魔衣nets的布线 如果你对他十分满意的话; 让他们在之后的reroute 中不会被破坏;
set_attribute -objects [get_nets nets_name] -name physical_status -value locked
opt post_route
布线后的优化
优化包括:
布线后的setup/hold timing 的优化;
逻辑DRC和面积的优化;
ECO 的布局和布线
# the main common
route_opt
# 可选的打开 power CTO CCD 的优化
# 影响优化的 app_options : route_opt.*
布线后的优化: Power & CTO
# 打开 power 优化选项
set_app_options -name route_opt.flow.enable_power -value true
# 功耗的优化一旦开启 就是基于 scenario 的配置
# 如果 有效的scenario 是leakage + dynamic 有效的 那么优化的就是total power
# 如果 有效的scenario 只有 leakage 有效;那么只会优化 leakage power
# 如果你使用的classic CTS 的流程 你可以使用下面的,命令 优化时钟树的skew 和 latency
synthesize_clock_trees -postroute -route_clock_stage detail_with_signal_routes
# 不要再 CCD有效的时候使用';
布线后的优化: CCD
# 打开concurrent clock& data optimization
set_app_options -name route_opt.flow.enable_ccd -value true
#布线后的CCD 能够在 即使在 clock_opt阶段使用 classic CTS 也能够被使用;
# 打开 route_opt 期间的CCD power recovery;
set_app_options -name route_opt.flow.enable_clock_power_recovery -value none| auto | area | power
# CCD 的power recovery 只是对于clock 单元和寄存器的优化
# 默认情况下 一旦CCD 被打开 就会执行 power 的recovery 否则就啥也不执行 (none)
使用 Prime Time 计算delay
在ICCII中执行 布线后的时序分析和优化route_opt 使用集成的PrimeTime的延迟计算模型; 能够提高准确性 使用PrimeTime SI 能够得到总体上更快的时序收敛;
PT delay计算在2018.06 及以后版本 自动打开的;
CLIBs 必须有2018.06及以后的版本生成
在更早的版本中,后者更早的CLIBs 参考库的原始的db文件必须附加到NDM 单元库上;
PT delaycalc 的设置
# 关联ICCII 和PT 的时序分析
set_app_options -list {
time.enable_ccs_rcv_cap true
time.delay_calc_waveform_analysis_mode full_design
time.si_enable_analysis true
time.enable_si_timing_windows true
}
# main common
set_app_options -list {time.use_pt_delay true}
# 打开可选择的 route_opt的优化选项
set_app_options -list {
route_opt.flow.enable_ccd true
route_opt.flow.enable_power true
}
# thelast
route_opt
StarRC InDesign
快速的QoR 收敛 (QoR convergence)
在一次route_opt的执行之后 QoR 能够收敛是非常少见的;
为了Qor 的收敛 tree-run 的方法是建议的;
- 为了更精确的时序分析 在第一轮route_opt 之后 使用 path_based 优化; 支持 path & exhaustive的优化
- 在ECO routing期间 关闭 soft-rule-based 的时需优化 限制影响多次布线 以及QoR收敛的spreading;
- 最后一轮route_opt 建议 size_only
如果你使用ECO flow 的话 我们建议 使用route_opt + eco_opt 来代替 三次 route_opt
推荐的 route_opt flow
# 确保 PT delay calc 是打开的 所有的时序设置是相关联的;你应该能看到information:
# information : Timer using 'PrimeTime Delay Calculation SI Timing Window Analysis AWP CRPR'
# 配置 StarRC
route_opt
set_app_options -list {
time.pba_optimization_mode path
route.detail.eco_route_use_soft_spacing_for_timing_optimization false
}
route_opt
set_app_options -list {
route_opt.flow.enable_ccd false
route_opt.flow.enable_power power
route_opt.flow.size_only_mode equal_or_smaller
}
route_opt


















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











