




深入浅出CenterFusion
Summary
自动驾驶汽车的感知系统一般由多种传感器组成,如lidar、carmera、radar等等。除了特斯拉基于纯视觉方案来进行感知之外,大多数研究还是利用多种传感器融合来建立系统,其中lidar和camera的融合研究比较多。
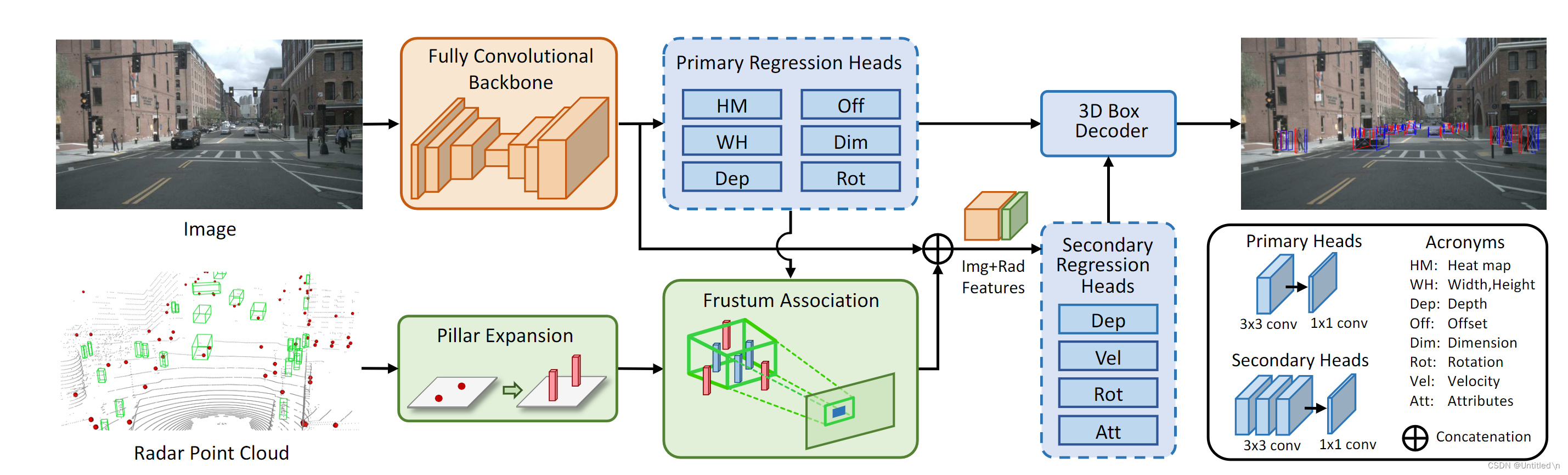
CenterFusion这篇文章基于nuscenes数据集研究camera和radar的特征层融合,图像部分采用的是CenterNet,radar点云部分采用了pillar expansion后通过roi frustum来与图像检测到的box进行匹配,radar特征提取与CenterNet类似,利用radar点云的vx、vy以及depth分别构建heatmap后与图像特征进行拼接来完成融合。官方代码仓库链接
总体思路还是将雷达点云投射到图像数据中,特征层进行通道拼接,再利用卷积网络进行回归。检测分为两个阶段,Primary Regression Heads的结果除了输出外,还用来进行点云数据和box的匹配;Secondary Regression Heads由于拼接了雷达特征,可以修正Primary Regression Heads的预测结果,同时给出额外的信息,目标速度和属性等等。
主要解决了如下问题:
| 问题 | 方案 |
|---|---|
| 毫米波雷达点云数据有很多杂波,和真实物体经常是一对多的关系,难以与图像box进行匹配 | 利用3D视椎体来过滤和筛选点云,加快匹配速度,同时过滤无效的点云 |
| 一般的毫米波雷达点云数据没有高度信息,很难准确与图像中的box进行匹配 | Pillar Expansion, 将点扩充为3D pillar,增大匹配概率 |
| 毫米波雷达点云数据非常稀疏,以致于表征能力弱,在整个网络中的权重较低 | 利用与之匹配的box来扩充雷达点云覆盖范围,由一个点转变成一小块矩形区域,提取点云heatmap作为点云特征 |
-
图片特征提取及Primary Regression
修改了CenterNet的Head,利用全卷积backbone进行特征提取的时候,进行一个初步的回归,得到目标的2D Box 和3D Box -
雷达点云和2D图像目标匹配
-
3D 视椎体
利用Primary Regression Heads得到的每个3D Box的深度depth、观测角alpha、3D框尺寸dim,再加上相机标定矩阵来生成3D视椎体(每个可能的Box都生成一个),类似Roi提取,加快匹配速度的同时,过滤无效的点云。观测角和标定矩阵是为了计算yaw角
-
雷达点云Pillar Expansion
雷达点云没有高度信息,将点云扩充为固定大小的3D柱子,增大点云匹配的概率(相对用点表示目标物,用柱子表示能够增加在3D空间中的体积,进而增大匹配的概率) -
点云匹配
pillar投影到pixel坐标系与2D box进行匹配; pillar投影到相机坐标系与构造的3D视椎体进行深度值匹配
-
-
雷达点云特征提取
对于每一个与视椎体关联到雷达目标,利用图像中2D检测框的位置生成三张heatmap,三张heatmap concat到图片的特征中作为额外通道,进而完成融合 -
利用融合特征进行Secondary Regression
除了估计目标速度之外,还重新估计了目标的深度和角度(结合了雷达特征,估计更精确) -
3D Box Decoder
综合Primary和Secondary Regression Heads的输出,还原出3D目标检测结果(位置、大小、姿态、速度,以及类别等属性),其中dep和rot在两个heads里都有,则只利用准确度更高的second regression heads
背景知识
如果没有了解过相关内容,可以按下顺序来看,CenterFusion里的大部分代码都是来自于CornerNet和CenterNet
重点内容
Backbone结构
Backbone沿用了CenterNet的DLA-34作为全卷积骨干网络, 并将可变形卷积DeformConv引入。关于网络结构内容可参考CenterFusion(基于CenterNet)源码深度解读: :DLA34

全卷积骨干网络以图像 I ∈ R W × H × 3 I \in R^{W \times H \times 3} I∈RW×H×3作为输入,生成key points heatmap: Y ^ ∈ [ 0 , 1 ] W R × H R × C \hat{Y} \in[0,1]^{\frac{W}{R} \times \frac{H}{R} \times C} Y^∈[0,1]RW×RH×C,其中 W 和 H是图像的宽度和高度,R是下采样比,C 是物体类别的数量。heatmap中的每一个像素的取值在[0,1]之间。再通过回归图像特征的方法来实现对图像上目标中心点的预测,以及对目标的 2D 大小(宽度和高度)、中心偏移量、3D 尺寸、深度和旋转等信息的提取。以上均继承于CenterNet。
训练数据的图像尺寸为 3 × 900 × 1600 3\times900\times1600 3×900×1600,下采样比为2,为了下采样不产生余数,入模图像的尺寸为 3 × 448 × 800 3\times448\times800 3×448×800。
雷达点云和2D图像目标匹配
基于视锥的匹配

-
3D视椎体缩小了匹配范围,进而加快匹配速度
-
相比于直接将雷达点云投射到2D图像,3D视锥能够区分2D图像中重叠或被遮挡的目标
-
使用参数 δ \delta δ来调节 ROI 视椎体的大小,这是为了解决估计的深度值的不准确性,因为ROI视椎匹配时,使用的深度值 d ^ \hat{d} d^是通过图像特征估计出来的。调节视椎体大小的目的是为了尽可能的给每一个box找到至少一个雷达点云来匹配,即使匹配到多个点云,后面直接取深度最小的点云来完成box内的点云去重。如下为BEV视角示意图
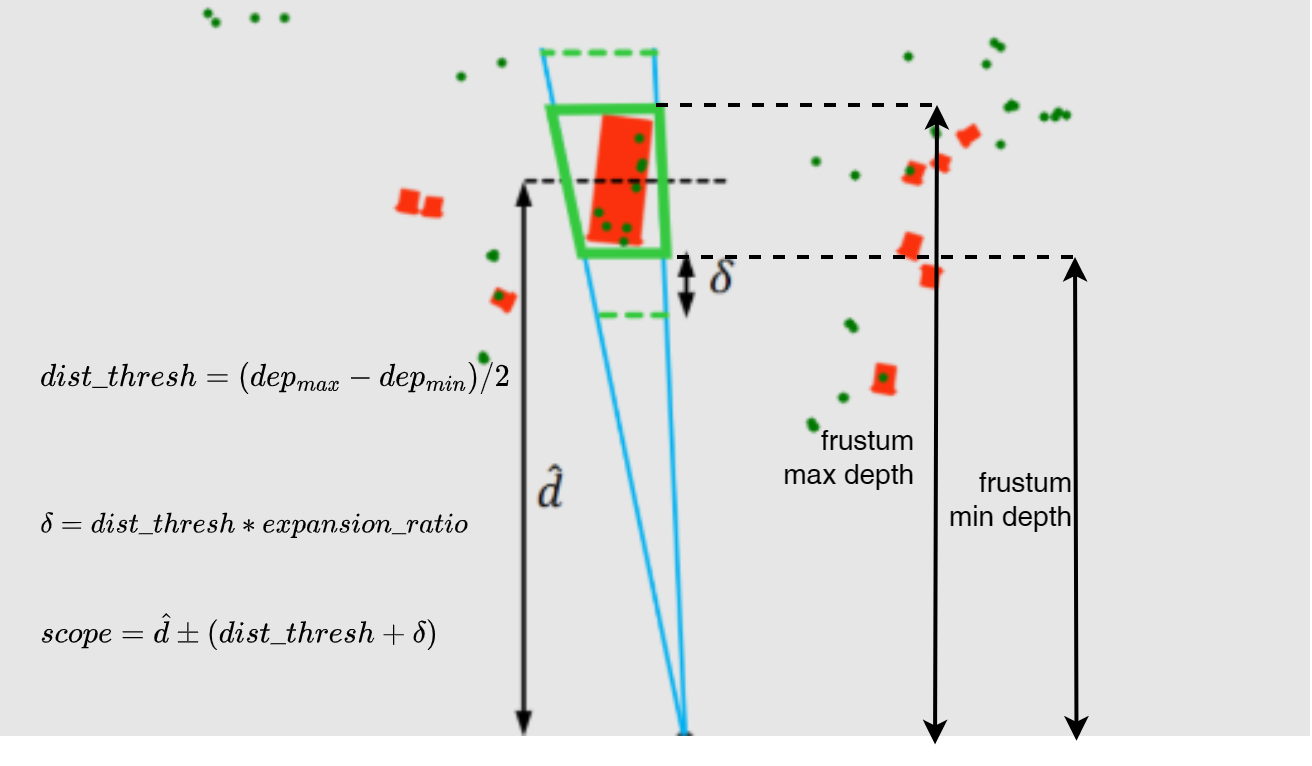
只在infer阶段用参数δ,实际调节的是视椎体的深度范围, 增加此参数的目的更多是降低漏检率。
代码中用
frustumExpansionRatio来表示调节参数,根据视锥体的深度范围计算得到一个dist_thresh,
其中 δ = d i s t _ t h r e s h ∗ f r u s t u m E x p a n s i o n R a t i o n \delta = dist\_thresh * frustumExpansionRation δ=dist_thresh∗frustumExpansionRation, d ^ \hat{d} d^是primary head输出的3D box depth或GT depth。 图中绿色虚线是经过调节的视锥体深度值范围,深度值在此范围内的雷达点云,与这个对应的box匹配。其中roi frustum和dist_thresh构造程序如下:# 对每一个3D box,计算roi frustum的8个角点, roi frustum为3D box的包围盒, # 且roi frustum在pixel坐标系下的投影为2D box def comput_corners_3d(dim, rotation_y): # dim: 3 # location: 3 # rotation_y: 1 # return: 8 x 3 c, s = torch.cos(rotation_y), torch.sin(rotation_y) # dim是相机坐标系下的长宽高,下面计算的也是相机坐标系下的3D box的8个角点 # 自动驾驶车辆在地面上行驶,一般只考虑偏航角,利用rotation_y构造旋转矩阵 # 航向角为绕y轴旋转,所以旋转矩阵为 R = torch.tensor([[c, 0, s], [0, 1, 0], [-s, 0, c]], dtype=torch.float32) l, w, h = dim[2], dim[1], dim[0] x_corners = [l/2, l/2, -l/2, -l/2, l/2, l/2, -l/2, -l/2] y_corners = [0, 0, 0, 0, -h, -h, -h, -h] z_corners = [w/2, -w/2, -w/2, w/2, w/2, -w/2, -w/2, w/2] corners = torch.tensor( [x_corners, y_corners, z_corners], dtype=torch.float32) # 相机坐标下的3D box的8个角点左乘旋转矩阵,得到roi frustum的8个角点, # 对应的roi frustum在pixel坐标系下的投影,刚好为2D box corners_3d = torch.mm(R, corners).transpose(1, 0) return corners_3d def get_dist_thresh(calib, ct, dim, alpha): rota
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1523
1523








 到【灌水乐园】发言
到【灌水乐园】发言







