







一、CenterFusion 概述
- 这个项目,重点研究毫米波雷达和相机传感器融合的方法
- 利用毫米波雷达传感器数据和相机传感器数据进行 3D 目标检测
- 并在 NuScenes 数据集上面进行评估
- CenterFusion 网络架构:
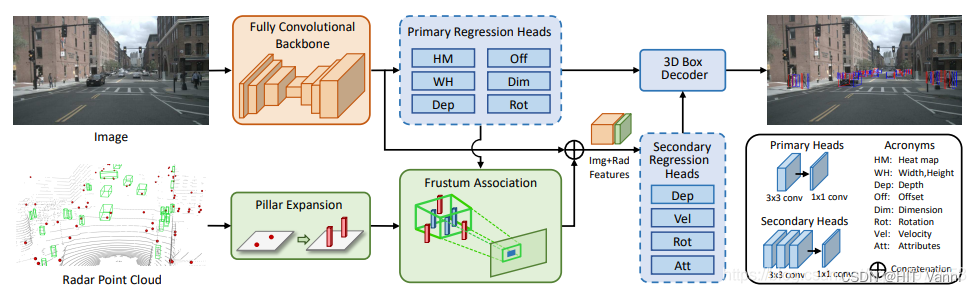
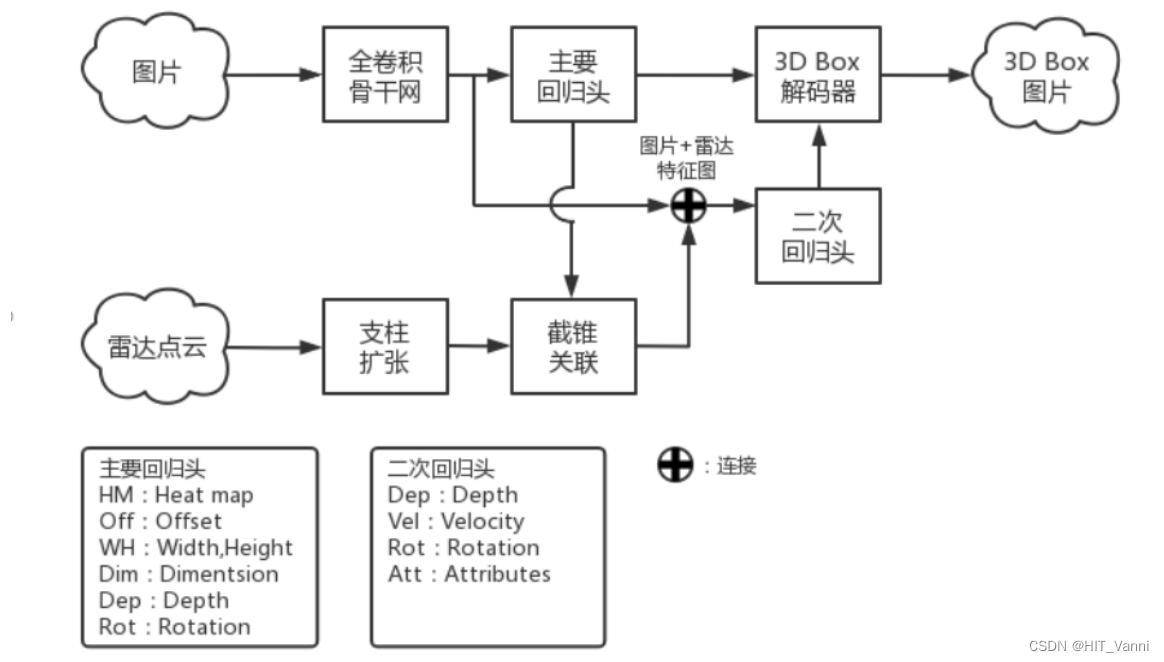
CenterFusion 网络架构首先利用全卷积骨干网提取目标物体中心点的图像特征,再回归到物体的其它属性,如三维位置、方向和尺寸,并获得初步的 3D Box
截锥关联模块将雷达检测结果与对应目标中心点关联(雷达检测结果映射到图像平面)并生成雷达特征
然后将图像和雷达特征连接起来, 再二次回归到目标属性,如深度、旋转以及速度等三维属性来细化初步的 3D Box
该网络架构主要可以分为两个部分分析,一个是上面一行的图像目标检测,另一个是下面一行的雷达点云数据处理。
二、图像目标检测
CenterNet 中主要提供了三个骨干网络 ResNet-18 (ResNet-101)、DLA-34、Hourglass-104
CenterFusion 网络架构在对图像进行初步检测时,采用 CenterNet 网络中修改版本的骨干网络 DLA(深层聚合)作为全卷积骨干网,来提取图像特征,因为 DLA 网络大大减少了培训时间,同时提供了合理的性能
再回归图像特征来预测图像上的目标中心点,以及目标的 2D 大小(宽度和高度)、中心偏移量、3D 尺寸、深度和旋转
主要回归头的组成:256 个通道的 3×3 卷积层、1×1卷积层。这为场景中每个被检测到的对象提供了一个精确的 2D 边界框以及一个初步的 3D 边界框
CenterNet 原理:
第 1 步:以图像
I
∈
R
W
×
H
×
3
I \in R^{W×H×3}
I∈RW×H×3作为输入,生成预测关键点热图
Y
∈
[
0
,
1
]
W
R
×
H
R
×
C
Y \in [0,1]^{\frac W R × \frac H R × C}
Y∈[0,1]RW×RH×C其中
W
W
W和
H
H
H是图像的宽度和高度,
R
R
R是下采样比,
C
C
C是物体类别的数
意思是将一张
W
×
H
W×H
W×H的图片作为输入,然后通过下采样(池化)生成
W
R
×
H
R
\frac W R × \frac H R
RW×RH的关键点热图,图中的每一个像素的热值在 [0,1] 之间。
第 2 步:再以
Y
^
=
1
\hat Y = 1
Y^=1作为输出的预测
意思是检测到一个以图像 ( x , y ) (x,y)(x,y) 为中心的 c cc 类目标
对于每个中心点,还预测了一个局部偏移量,以补偿由骨干网输出步数引起的离散误差
第 3 步:使用高斯核从地面真值 2D 边界框生成地面真值热图
Y
∈
[
0
,
1
]
W
R
×
H
R
×
C
Y \in [0,1]^{\frac W R × \frac H R × C}
Y∈[0,1]RW×RH×C
这是为了与模型预测的结果进行比较,从而计算 loss 值(损失)
第 4 步:对于图像中 c cc 类的每个边界框中心点
p
i
∈
R
2
p^i \in R^2
pi∈R2,在
Y
:
,
:
,
c
Y_{:,:,c}
Y:,:,c上生成一个高斯热图:
Y
q
c
=
m
a
x
i
e
x
p
(
(
p
i
−
q
)
2
−
2
σ
i
2
)
Y_{qc}=\ \mathop{max}\limits_{i}\ exp( \frac {(p_i−q)^2}{−2σ_i^2} )
Yqc= imax exp(−2σi2(pi−q)2)
其中
σ
i
\sigma_i
σi是一个尺寸自适应标准差,根据每个对象的尺寸控制热图的大小,采用全卷积码-解码器网络对
Y
^
\hat Y
Y^进行预测
第 5 步:使用单独的网络头直接从检测到的中心点回归对象的深度、尺寸和方向,来生成 3D Box
在回归模块中
深度被作为额外的输出通道
D
^
∈
[
0
,
1
]
W
R
×
H
R
\hat D \in [0,1]^{\frac W R × \frac H R}
D^∈[0,1]RW×RH,因为使用了 sigmoidal 逆变换,并将其应用到了原始深度域
方向被编码为两个容器,每个容器中有 4 个标量
给定带注释的对象
p
0
,
p
1
,
.
.
.
p0,p1,...
p0,p1,...在一幅图像中,训练分类损失,即 focal loss 定义如下:
L
k
=
1
N
∑
x
y
c
{
(
1
−
Y
^
x
y
c
)
α
log
(
Y
^
x
y
c
)
Y
x
y
c
=
1
(
1
−
Y
x
y
c
)
β
(
Y
^
x
y
c
)
α
log
(
1
−
Y
^
x
y
c
)
otherwise
\mathrm{L}_{\mathrm{k}}=\frac{1}{\mathrm{~N}} \sum_{\mathrm{xyc}}\left\{\begin{array}{ll} \left(1-\hat{\mathrm{Y}}_{\mathrm{xyc}}\right)^{\alpha} \log \left(\hat{\mathrm{Y}}_{\mathrm{xyc}}\right) & \mathrm{Y}_{\mathrm{xyc}}=1 \\ \left(1-\mathrm{Y}_{\mathrm{xyc}}\right)^{\beta}\left(\hat{\mathrm{Y}}_{\mathrm{xyc}}\right)^{\alpha} \log \left(1-\hat{\mathrm{Y}}_{\mathrm{xyc}}\right) & \text { otherwise } \end{array}\right.
Lk= N1xyc∑⎩
⎨
⎧(1−Y^xyc)αlog(Y^xyc)(1−Yxyc)β(Y^xyc)αlog(1−Y^xyc)Yxyc=1 otherwise
其中
N
N
N为对象数量
Y
∈
[
0
,
1
]
W
R
×
H
R
×
C
Y \in [0,1]^{\frac W R × \frac H R × C}
Y∈[0,1]RW×RH×C为标注对象的地面真值热图
α
\alpha
α和
β
\beta
β为焦损超参数
三、雷达点云处理
- 首先,需要搞清楚雷达点云检测的是径向深度和目标实际速度的不同,如图:
![[图片]](https://img-blog.csdnimg.cn/direct/2f662d83bd97401daec8bf11065ab1b7.png)
对于目标 A,车辆坐标系内速度与径向速度相同
(
v
A
)
(v^A)
(vA),另一方面,对于目标 B,雷达报告的径向速度
(
v
r
)
(v_r)
(vr)与目标在车辆坐标系中的实际速度
(
v
B
)
(v^B)
(vB)存在差异
支柱扩张:
-
在截锥关联之前,有一个支柱扩张模块,对雷达点云进行预处理:将每个雷达点云扩展成一个固定尺寸的柱状,如下图所示:
![[图片]](https://img-blog.csdnimg.cn/direct/1b05a0694c534e5a8639d0761784c86a.png)
-
这是为了解决每个雷达点云在截锥关联中高度信息不准确的问题
截锥关联 -
第 1 步:利用图像平面中对象的 2D 边界框及其估计深度和大小,为对象创建一个 3D 感兴趣区域(RoI)截锥,如下图所示:
![[图片]](https://img-blog.csdnimg.cn/direct/8218dd94f7f4451c8071f4d85feec54a.png)
有了截锥对象,缩小了需要检查关联的雷达点云探测范围,因为这个截锥之外的任何点云都可以忽略
如果该 RoI 内存在多个雷达检测点云,则取最近的点作为该目标对应的雷达检测点云
第 2 步:对于每一个与物体相关的雷达检测,我们生成三个以物体的二维包围框为中心并在其内部的热图通道,热图的宽度和高度与物体的 2D 边界框成比例,并由参数 α 控制
其中热图值是归一化对象深度(d),也是自中心坐标系中径向速度
(
v
x
)
(v_x)
(vx)和
(
v
y
)
(v_y)
(vy)的x和y分量:
F
x
,
y
,
i
j
=
1
M
i
{
f
i
∣
x
−
c
x
j
∣
≤
α
w
j
and
∣
y
−
c
j
i
∣
≤
α
h
j
0
otherwise
F_{x, y, i}^{j}=\frac{1}{M_{i}}\left\{\begin{array}{ll} f_{i} & \left|x-c_{x}^{j}\right| \leq \alpha w^{j} \text { and }\left|y-c_{j}^{i}\right| \leq \alpha h^{j} \\ 0 & \text { otherwise } \end{array}\right.
Fx,y,ij=Mi1{fi0
x−cxj
≤αwj and
y−cji
≤αhj otherwise
i
∈
1
,
2
,
3
i∈1,2,3
i∈1,2,3是地图通道的特性,
M
i
M_i
Mi是一种规格化因素,
f
i
f_i
fi是特征值
(
d
,
v
x
或
v
y
)
(d,v_x或v_y)
(d,vx或vy)
c
x
j
c^j_x
cxj和
c
y
j
c^j_y
cyj是 j 对象的 x 和 y 坐标对象的中心点的图像,
w
j
w^j
wj和
h
j
h^j
hj是 j 对象的宽度和高度的 2D 边界框
第 3 步:两个物体的热图区域重叠,深度值较小的那个占优势,因为只有最近的物体在图像中是完全可见的,如下图所示:
![[图片]](https://img-blog.csdnimg.cn/direct/56a5173844c443ca8992fbf90088863d.png)
第 4 步:生成的热图然后连接到图像特征作为额外的通道,这些特征被用作二次回归头的输入,以重新计算对象的深度和旋转,以及速度和属性
二次回归头由 3 个卷积层 (3×3 核) 和 1×1 卷积层组成,以产生所需的输出
最后一步是将回归头结果解码为 3D 边界框,3D Box 解码器块使用估计的深度、速度、旋转和二次回归头部的属性,并从主回归头部获取其他对象的属性

















 2106
2106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











