







一、参考资料
万字长文理解纯视觉感知算法 —— BEVFormer: 知乎
论文链接: BEVFormer
视频链接: B站up
二、 BEVformer代码流程处理
2.1 输入数据和预处理
2.1.1 配置文件
configs/bevformer
这个文件夹下有3个不同大小的文件,一个tiny、一个small、一个base
【具体不同可以去文件中查看】
采用6个camera的图像作为输入,每个序列包含3个历史帧(3*6)【t-3,t-2,t-1,t】
2.1.2 数据预处理流程
以tiny.py中为例:
train_pipeline = [
dict(type='LoadMultiViewImageFromFiles', to_float32=True),
dict(type='PhotoMetricDistortionMultiViewImage'),
dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True, with_attr_label=False),
dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
dict(type='ObjectNameFilter', classes=class_names),
dict(type='NormalizeMultiviewImage', **img_norm_cfg),
dict(type='PadMultiViewImage', size_divisor=32),
dict(type='DefaultFormatBundle3D', class_names=class_names),
dict(type='CustomCollect3D', keys=['gt_bboxes_3d', 'gt_labels_3d', 'img'])
]
train_pipeline和test_pipeline中:
1)加载多视角图像
2)图像增强(光度失真、图像标准化、随机缩放)
3)加载3D标注
4)过滤处理(点云范围: point_cloud_range = [-51.2, -51.2, -5.0, 51.2, 51.2, 3.0]、类别: class_names = [
‘car’, ‘truck’, ‘construction_vehicle’, ‘bus’, ‘trailer’, ‘barrier’,
‘motorcycle’, ‘bicycle’, ‘pedestrian’, ‘traffic_cone’
])
5)图像填充
6)数据格式化(转为处理后的tensor,选取用于训练的数据和标签)
最后处理完,输入模型的数据格式:
- img_metas: <class 'mmcv.parallel.data_container.DataContainer'>
- gt_bboxes_3d: <class 'mmcv.parallel.data_container.DataContainer'>
- gt_labels_3d: <class 'mmcv.parallel.data_container.DataContainer'>
- img: <class 'mmcv.parallel.data_container.DataContainer'>
img_metas包括了:
- 4个历史序列,每个序列中又包括6张环视图像(路径)filename
- ori_shape (900, 1600, 3) *6
- img_shape (928, 1600, 3) *6
- lidar2img 4*4矩阵
**注意:**
1. BEV 坐标系 这里指 lidar 坐标系
2. 这里提到的`lidar2img`是经过坐标变换的,一般分成三步
第一步:lidar 坐标系 -> ego vehicle 坐标系
第二步:ego vehicle 坐标系 -> camera 坐标系
第三部:camera 坐标系 通过相机内参 得到像素坐标系
以上这三步用到的所有平移和旋转矩阵都合并到了一起,形成了`lidar2img` 旋转平移矩阵
-lidar2cam 4*4矩阵
-pad_shape (928, 1600, 3)
-scale_factor 1.0
-box_mode_3d <Box3DMode.LIDAR: 0>
-box_type_3d <class 'mmdet3d.core.bbox.structures.lidar_box3d.LiDARInstance3DBoxes'>
-img_norm_cfg {'mean': array([103.53 , 116.28 , 123.675], dtype=float32), 'std': array([1., 1., 1.], dtype=float32), 'to_rgb': False},
-sample_idx bfb240c35d3c4a52bd06ecf4968811d0
-prev_idx e4d098ea95664f45999c5009953b45ad
-next_idx 497dddd2036749619a3f60901ef1ccd9
-pts_filename data/nuscenes/samples/LIDAR_TOP/n015-2018-08-03-15-00-36+0800__LIDAR_TOP__1533279680650385.pcd.bin
-scene_token 4098aaf3c7074e7d87285e2fc95369e0
-can_bus (18,)对应18个不同参数
-prev_bev_exists True/False
2.2 模型结构与数据流
2.2.1 整体架构
1)图像backbone:Restnet50
2) Neck:FPN
3) BEV Encoder:PerceptionTransformer(3层
BEVFormerEncoder)
4) 检测Decoder:6层 DetectionTransformerDecoder
5)检测头:BEVFormerHead
2.2.2 BEV表示
tiny使用50*50的网格,覆盖范围为:x [-51.2,51.2]米,y [-51.2,51.2]米,z [-5,3]米 ,每个网格约为2米。
2.2.3 BEV表征生成
使用PerceptionTransformer将环视图转换为BEV表征。
- BEV Query初始化(Learned PostionalEncoding可学习的位置编码),初始化Query
- Encoder处理(BEVFormerEncoder)
Encoder内部流程:
a. TemporalselfAttention(包括当前时刻的BEV query与历史时刻BEV query特征交互,自车前后时刻特征对齐(旋转平移))
b. spatialcross Attention (每个BEV Query与6张图像交互)
c. FFN (两层MLP)
2.2.4 Decoder
1、number_query = 900 【DETR的操作】
2、经过MultiheadAttention和可变形注意力机制
2.2.5检测头输出
Bevformer将Decoder输出转化为最终的检测结果
1、分类损失:预测10个类别
2、回归损失:预测3D边界框
3、IoU损失
三、问题汇总(大部分是代码方面的)
问题1:BEV Query和num_query的区别
BEV Query用在编码器中,目得是构建BEV,大小为50*50;
num_query用在解码器中,用于检测场景中的目标。
问题2:p=(x,y)的Query Qp 和真实世界(x’,y’)的关系
两个坐标系是不一样的,Query 坐标系是BEV的坐标系,图像原点位于BEV的左下角,而真实世界(x’,y’)是自车坐标系,也就说要从BEV坐标系转化到自车坐标系。
x’ = (x- w/2)*s
y’ = (y -h/2)*s
todo:画图说明
问题3:如何用相机内外参矩阵将从柱状Query中采样的3D参考点投影到各个相机平面呢?然后再如何判断该点是否落在相机的视野范围内?
- 使用外参矩阵将3D点从世界坐标系转到相机坐标系(3D点)(x,y,z)
- 使用内参矩阵将相机坐标系投影到2D图像平面(u,v)
- 判断点是否落在相机视野范围内(a.点必须在相机前方 b.投影点必须在图像范围内)
这里再说明一下3D到2D之间投影的关系是如何建立的。
首先先把BEV提升到3维度(类似于魔方),得到每个网格的立体版了,再这这个立体网格上间隔选取4个点,每个点的索引坐标(x,y,z)就有了,然后再利用相机的内外参得到投影到图像上的坐标,但是不是每个图像上都会存在投影点(这就对了,前面的摄像头拍摄的图像,后面摄像头拍不到吧?),既然不是每个图像都能投影到,那就选那些有效的投影点。
【代码里不光选了有效的投影点(就是论文中的参考点ref_2D),还把query做了筛选,相当于是从 BEV 查询(query)中提取有效网格的特征,按相机重新分配,用于提问。】
zs = torch.linspace(0.5, ref_3d_z - 0.5, num_points_in_pillar, dtype=dtype,
device=device).view(-1, 1, 1).expand(num_points_in_pillar, bev_h, bev_w) / ref_3d_z
xs = torch.linspace(0.5, bev_w - 0.5, bev_w, dtype=dtype,
device=device).view(1, 1, bev_w).expand(num_points_in_pillar, bev_h, bev_w) / bev_w
ys = torch.linspace(0.5, bev_h - 0.5, bev_h, dtype=dtype,
device=device).view(1, bev_h, 1).expand(num_points_in_pillar, bev_h, bev_w) / bev_h
ref_3d = torch.stack((xs, ys, zs), -1)
ref_3d = ref_3d.permute(0, 3, 1, 2).flatten(2).permute(0, 2, 1)
ref_3d = ref_3d[None].repeat(bs, 1, 1, 1) # bs, num_points_in_pillar, bev_h * bev_w, xyz # torch.Size([1, 4, 50*50, 3])
# ref_3d:
# zs: (0.5 ~ 8-0.5) / 8
# xs: (0.5 ~ 50-0.5) / 50
# ys: (0.5 ~ 50-0.5) / 50
# return ref_3d
# ----------------------get_reference_points end----------------------
# ref_2d = self.get_reference_points(
# bev_h, bev_w, dim='2d', bs=bev_query.size(1), device=bev_query.device, dtype=bev_query.dtype)
# ---------------------get_reference_points start---------------------
ref_y, ref_x = torch.meshgrid(
torch.linspace(
0.5, bev_h - 0.5, bev_h, dtype=dtype, device=device),
torch.linspace(
0.5, bev_w - 0.5, bev_w, dtype=dtype, device=device)
)
ref_y = ref_y.reshape(-1)[None] / bev_h
ref_x = ref_x.reshape(-1)[None] / bev_w
ref_2d = torch.stack((ref_x, ref_y), -1)
ref_2d = ref_2d.repeat(bs, 1, 1).unsqueeze(2) # ref_2d其实就是ref_3d torch.Size([1, 4(4个高度), 50*50, 3(x,y,z)]) 去掉高度的一部分,
# bs, bev_h * bev_w, None, xy # torch.Size([1, 50*50, 1, 2])
# return ref_2d
# ----------------------get_reference_points end----------------------
# reference_points_cam, bev_mask = self.point_sampling(ref_3d, self.pc_range, kwargs['img_metas'])
# ------------------------point_sampling start------------------------
reference_points = ref_3d
# NOTE: close tf32 here.
allow_tf32 = torch.backends.cuda.matmul.allow_tf32
torch.backends.cuda.matmul.allow_tf32 = False
torch.backends.cudnn.allow_tf32 = False
lidar2img = []
for img_meta in ohb_img_metas:
lidar2img.append(img_meta['lidar2img']) # lidar2img 激光雷达到图像坐标的转换,将激光雷达坐标系当作自车坐标系
lidar2img = np.asarray(lidar2img)
lidar2img = reference_points.new_tensor(lidar2img) # torch.Size([1, 6, 4, 4]) 相机内外参合成一个矩阵4*4
reference_points = reference_points.clone()
# reference_points = ref_3d # normalize 0~1 # torch.Size([1, 4, 50*50, 3])
# pc_range = [-51.2, -51.2, -5.0, 51.2, 51.2, 3.0] 长102.4 宽102.4 高8
# 映射到自车坐标系下, 尺度被反归一化为真实尺度(米)
reference_points[..., 0:1] = reference_points[..., 0:1] * \
(pc_range[3] - pc_range[0]) + pc_range[0] # x 0~1 缩放到 0~102.4
reference_points[..., 1:2] = reference_points[..., 1:2] * \
(pc_range[4] - pc_range[1]) + pc_range[1] # y 0~1 缩放到 0~102.4
reference_points[..., 2:3] = reference_points[..., 2:3] * \
(pc_range[5] - pc_range[2]) + pc_range[2] # z 0~1 缩放到 0~8
# 变成齐次坐标
reference_points = torch.cat((reference_points, torch.ones_like(reference_points[..., :1])), -1)
# bs, num_points_in_pillar, bev_h * bev_w, xyz1 齐次坐标通过升维将平移纳入矩阵乘法 [x,y,z]-->[x,y,z,1]齐次坐标形式,为了和lidar2img[1, 6, 4, 4]做乘法
reference_points = reference_points.permute(1, 0, 2, 3)
# num_points_in_pillar, bs, bev_h * bev_w, xyz1
D, B, num_query = reference_points.size()[:3]
num_cam = lidar2img.size(1) # 6
reference_points = reference_points.view(D, B, 1, num_query, 4).repeat(1, 1, num_cam, 1, 1).unsqueeze(-1)
ref_3d = ref_3d[None].repeat(bs, 1, 1, 1) # bs, num_points_in_pillar, bev_h * bev_w, xyz # torch.Size([1, 4, 50*50, 3])
# bs, num_points_in_pillar, bev_h * bev_w, xyz # torch.Size([1, 4, 50*50, 3])
lidar2img = lidar2img.view(1, B, num_cam, 1, 4, 4).repeat(D, 1, 1, num_query, 1, 1)
# num_points_in_pillar, bs, num_cam, bev_h * bev_w, 4, 4
reference_points_cam = torch.matmul(lidar2img.to(torch.float32), reference_points.to(torch.float32)).squeeze(-1) # 每个 3D 点投影到 6 个相机上的齐次坐标 (u, v, s, 1)
# num_points_in_pillar, bs, num_cam, bev_h * bev_w, uvs1 s代表比例(x,y,s == kx,ky,ks s==1,x/s, y/s)
eps = 1e-5
bev_mask = (reference_points_cam[..., 2:3] > eps) # 只保留位于相机前方的点
# 齐次坐标下除以比例系数得到图像平面的坐标真值 : 将投影结果从 (u, v, s) 转换为实际的 2D 像素坐标 (x, y)
reference_points_cam = reference_points_cam[..., 0:2] / torch.maximum(
reference_points_cam[..., 2:3], torch.ones_like(reference_points_cam[..., 2:3]) * eps)
# num_points_in_pillar, bs, num_cam, bev_h * bev_w, uv
# 坐标归一化 都在0-1之间
reference_points_cam[..., 0] /= ohb_img_metas[0]['img_shape'][0][1]
reference_points_cam[..., 1] /= ohb_img_metas[0]['img_shape'][0][0]
# 去掉图像以外的点 先保证uv坐标都在0-1之间【在相机的视场内】 num_points_in_pillar, bs, num_cam, bev_h * bev_w, uv
bev_mask = (bev_mask & (reference_points_cam[..., 1:2] > 0.0)
& (reference_points_cam[..., 1:2] < 1.0)
& (reference_points_cam[..., 0:1] < 1.0)
& (reference_points_cam[..., 0:1] > 0.0))
问题4: 生成的PKL中有什么内容
pkl是create_data.py文件生成的,是字典格式,有2个键值对:metainfo和data_list;
mateinfo 中包含数据集基本信息,例如:categories, dataset, info_version;
data_list 列表形式:由字典组成,包含了单个样本所有信息
问题5: 代码中bev_mask的作用
bev_mask = torch.zeros((bs, bev_h, bev_w), device=bev_queries.device).to(dtype)
# bev_pos = self.positional_encoding(bev_mask).to(dtype)
# 这里只用到了bev_mask的shape和device信息,与bev_mask的值无关
bev_mask = (reference_points_cam[..., 2:3] > eps) # 只保留位于相机前方的点
# 齐次坐标下除以比例系数得到图像平面的坐标真值 : 将投影结果从 (u, v, s) 转换为实际的 2D 像素坐标 (x, y)
reference_points_cam = reference_points_cam[..., 0:2] / torch.maximum(
reference_points_cam[..., 2:3], torch.ones_like(reference_points_cam[..., 2:3]) * eps)
# num_points_in_pillar, bs, num_cam, bev_h * bev_w, uv
# 坐标归一化 都在0-1之间
reference_points_cam[..., 0] /= ohb_img_metas[0]['img_shape'][0][1]
reference_points_cam[..., 1] /= ohb_img_metas[0]['img_shape'][0][0]
# 去掉图像以外的点 先保证uv坐标都在0-1之间【在相机的视场内】 num_points_in_pillar, bs, num_cam, bev_h * bev_w, uv
bev_mask = (bev_mask & (reference_points_cam[..., 1:2] > 0.0)
& (reference_points_cam[..., 1:2] < 1.0)
& (reference_points_cam[..., 0:1] < 1.0)
& (reference_points_cam[..., 0:1] > 0.0))
bev_mask的值并不重要,它的目得是记录哪些BEV的网格点投影到图像平面后,有效的投影点(即哪些点落在了相机的视野范围内)。
问题6: 位置编码bev_pos为什么不用nn.parameter?
首先要明确 bev_queries 是干什么的? 它是 Transformer 编码器的 Query,用于生成 BEV 表示。为 BEV 空间的每个网格点提供一个初始的“问题”,例如“这个网格点对应的 3D 空间中有什么物体?”。代码中:
# BH_positional_encoding
pe_num_feats, pe_row_num_embed, pe_col_num_embed = pos_dim, bev_h, bev_w
pe_row_embed = nn.Embedding(pe_row_num_embed, pe_num_feats).cuda()
pe_col_embed = nn.Embedding(pe_col_num_embed, pe_num_feats).cuda()
pe_h, pe_w = bev_mask.shape[-2:] # bev_mask torch.Size([1, 50, 50])
pe_x = torch.arange(pe_w, device=bev_mask.device)
pe_y = torch.arange(pe_h, device=bev_mask.device)
pe_x_embed = pe_col_embed(pe_x) # torch.Size([50, 128])
pe_y_embed = pe_row_embed(pe_y) # torch.Size([50, 128])
pe_pos = torch.cat((pe_x_embed.unsqueeze(0).repeat(pe_h, 1, 1), pe_y_embed.unsqueeze(1).repeat(1, pe_w, 1)),
dim=-1).permute(2, 0, 1).unsqueeze(0).repeat(bev_mask.shape[0], 1, 1, 1)
# return pos
bev_pos = pe_pos # torch.Size([1, 256, 50, 50]) TODO: nn.Parameter([1, 256, 50, 50])?
上面代码自定义了一个可学习的参数,而没有用到nn.Parameter。
原因1:参数效率问题。当前代码中,pe_row_embed 和 pe_col_embed 的参数数量分别是 bev_h * pe_num_feats 和 bev_w * pe_num_feats,例如 50 * 128 = 6400 个参数(总共 12800 个参数)。
如果直接定义 bev_pos 作为一个 nn.Parameter,形状为 (1, 256, 50, 50),则参数数量是 256 * 50 * 50 = 640,000 个参数。这会极大地增加模型的参数量,导致过拟合和计算开销。
深度学习模型的参数越多,占用的 GPU 内存就越大。640,000 个参数(假设每个参数是 4 字节的 float32)占用约 2.56 MB,而 12,800 个参数只占用约 51.2 KB。参数量的增加会显著增加模型的内存需求,尤其是在大规模训练或多 GPU 并行时。
通过嵌入层的方式,参数数量大大减少,同时仍然能够为每个网格点生成独立的位置编码。
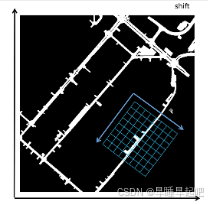
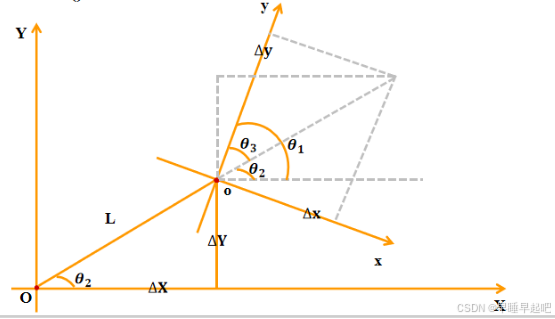
问题7:时间自注意力中,上一时刻的BEV特征如何与当前时刻对齐?
总的来看:对齐BEV,需要车辆的移动方向、上一帧的朝向、当前帧的朝向(这完全是估算出来的:bev_angle = ego_angle - translation_angle )
根据车辆的CAN_bus数据,计算从上一帧到当前帧的平移距离(translation_length)、平移方向(translation_angle)和旋转角度(bev_angle)

几个概念:
平移:车辆在x、y方向移动的距离
旋转:车辆的朝向变换(代表BEV要旋转)

















 2957
2957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









