






词向量(Embeddings)将非结构化数据,如单词、句子或者整个文档,转化为实数向量的技术。这些实数向量可以被计算机更好地理解和处理。
在开发时可用现成的api进行封装,以Openai的api为例子:
import os
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
# 读取本地/项目的环境变量。
# find_dotenv()寻找并定位.env文件的路径
# load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())
# 如果你需要通过代理端口访问,你需要如下配置
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
os.environ["HTTP_PROXY"] = 'http://127.0.0.1:7890'
def openai_embedding(text: str, model: str=None):
# 获取环境变量 OPENAI_API_KEY
api_key=os.environ['OPENAI_API_KEY']
client = OpenAI(api_key=api_key)
# embedding model:'text-embedding-3-small', 'text-embedding-3-large', 'text-embedding-ada-002'
if model == None:
model="text-embedding-3-small"
response = client.embeddings.create(
input=text,
model=model
)
return response
response = openai_embedding(text='要生成 embedding 的输入文本,字符串形式。')
从response这行开始,将输入的文本的text封装成Embeddings。
文本数据处理--PDF篇
使用 LangChain 的 PyMuPDFLoader 来读取知识库的 PDF 文件。PyMuPDFLoader 是 PDF 解析器中速度最快的一种,结果会包含 PDF 及其页面的详细元数据,并且每页返回一个文档。
from langchain.document_loaders.pdf import PyMuPDFLoader
# 创建一个 PyMuPDFLoader Class 实例,输入为待加载的 pdf 文档路径
loader = PyMuPDFLoader("../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf")
# 调用 PyMuPDFLoader Class 的函数 load 对 pdf 文件进行加载
pdf_pages = loader.load()
文档加载后储存在 pages 变量中:
page的变量类型为List- 打印
pages的长度可以看到 pdf 一共包含多少页print(f"载入后的变量类型为:{type(pdf_pages)},", f"该 PDF 一共包含 {len(pdf_pages)} 页")
数据清洗 去除空格和换行
我们期望知识库的数据尽量是有序的、优质的、精简的,因此我们要删除低质量的、甚至影响理解的文本数据。
可以看到上文中读取的pdf文件不仅将一句话按照原文的分行添加了换行符\n,也在原本两个符号中间插入了\n,我们可以使用正则表达式匹配并删除掉\n。
import re
pattern = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)
pdf_page.page_content = re.sub(pattern, lambda match: match.group(0).replace('\n', ''), pdf_page.page_content)
print(pdf_page.page_content)
类似的去掉•和空格,用replace方法即可
pdf_page.page_content = pdf_page.page_content.replace('•', '')
pdf_page.page_content = pdf_page.page_content.replace(' ', '')
print(pdf_page.page_content)
文档分割
由于单个文档的长度往往会超过模型支持的上下文,导致检索得到的知识太长超出模型的处理能力,因此,在构建向量知识库的过程中,我们往往需要对文档进行分割,将单个文档按长度或者按固定的规则分割成若干个 chunk,然后将每个 chunk 转化为词向量,存储到向量数据库中。
在检索时,我们会以 chunk 作为检索的元单位,也就是每一次检索到 k 个 chunk 作为模型可以参考来回答用户问题的知识,这个 k 是我们可以自由设定的。
构建向量数据库
Langchain 集成了超过 30 个不同的向量存储库。我们选择 Chroma 是因为它轻量级且数据存储在内存中,这使得它非常容易启动和开始使用。
LangChain 可以直接使用 OpenAI 和百度千帆的 Embedding,同时,我们也可以针对其不支持的 Embedding API 进行自定义,例如,我们可以基于 LangChain 提供的接口,封装一个 zhupuai_embedding,来将智谱的 Embedding API 接入到 LangChain 中。
3.1 相似度检索
Chroma的相似度搜索使用的是余弦距离,
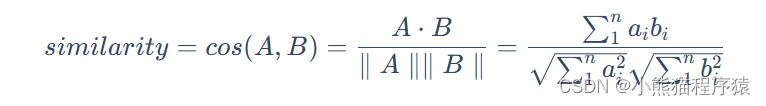
其中𝑎𝑖ai、𝑏𝑖bi分别是向量𝐴A、𝐵B的分量。
当你需要数据库返回严谨的按余弦相似度排序的结果时可以使用similarity_search函数。
question="什么是大语言模型"
sim_docs = vectordb.similarity_search(question,k=3)
print(f"检索到的内容数:{len(sim_docs)}")
检索到的内容数:3
for i, sim_doc in enumerate(sim_docs):
print(f"检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")
如果只考虑检索出内容的相关性会导致内容过于单一,可能丢失重要信息。
最大边际相关性 (MMR, Maximum marginal relevance) 可以帮助我们在保持相关性的同时,增加内容的丰富度。
核心思想是在已经选择了一个相关性高的文档之后,再选择一个与已选文档相关性较低但是信息丰富的文档。这样可以在保持相关性的同时,增加内容的多样性,避免过于单一的结果。















 456
456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









