






 文章讨论了即使有了深度学习模型f_θ预测游戏走法和胜率,MCTS在推理过程中的重要性,因为模型预测的是平均价值,而MCTS能探索深层状态的最优解。同时提到,虽然对弈双方目标相反,但仍能共享同一套神经网络,这是因为使用了极大极小值算法来最大化自己的收益和最小化对手的收益。
文章讨论了即使有了深度学习模型f_θ预测游戏走法和胜率,MCTS在推理过程中的重要性,因为模型预测的是平均价值,而MCTS能探索深层状态的最优解。同时提到,虽然对弈双方目标相反,但仍能共享同一套神经网络,这是因为使用了极大极小值算法来最大化自己的收益和最小化对手的收益。
-
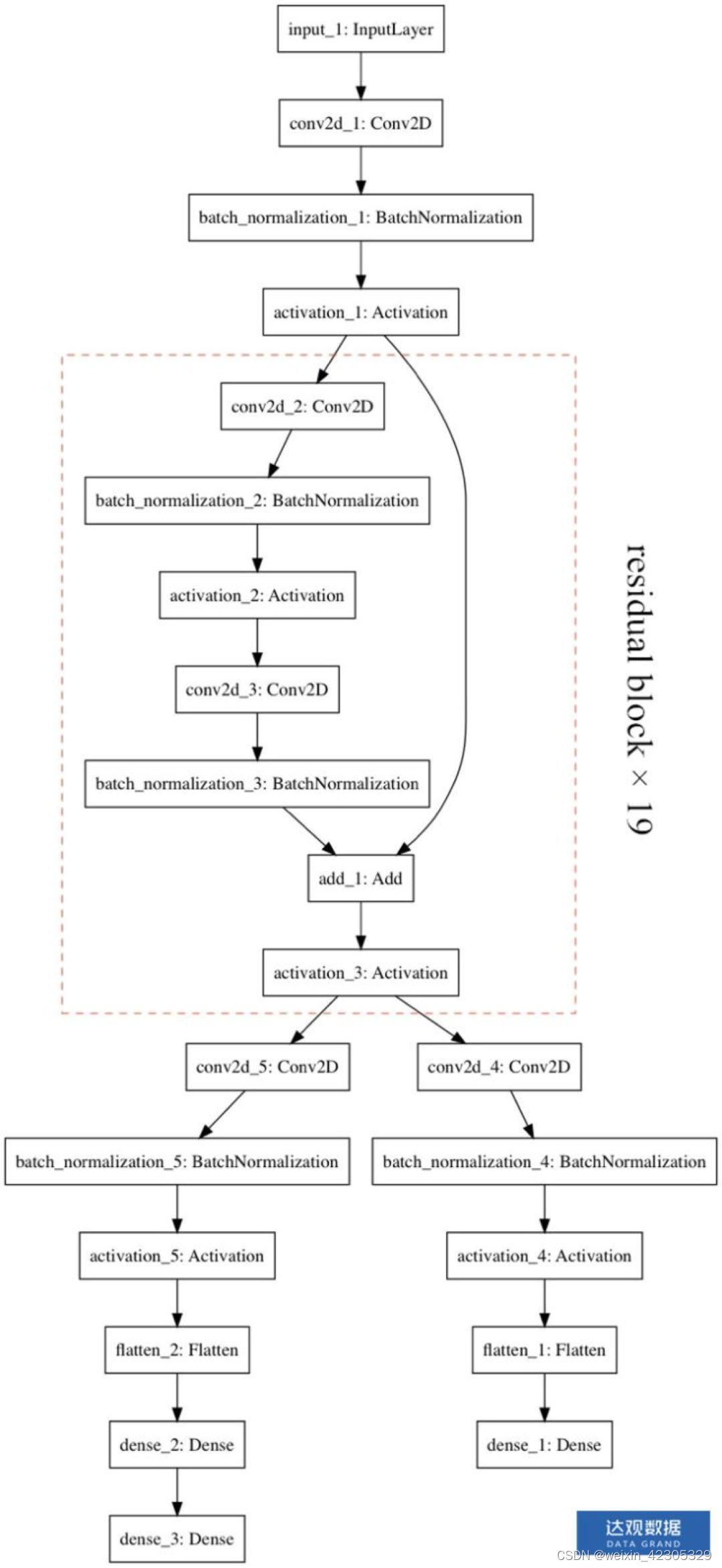
网络结构图:
只有一个网络f_θ,它的参数是θ。它的输入是当前局面和之前历史局面的原始表示s,它的输出是模型预测的可能走法的概率和这个局面的Value(可以认为当前局面的胜率)
-
为什么推理过程中依然需要MCTS?
(P, V)=f_θ(s)

在模型训练好之后,f_θ也就稳定了,给出的P也就是定值,之前的我会问,那就不需要MCTS了,输入当前的状态就会告诉你选择哪个动作会对局面更有利?
注意,概率!概率!
输出应该是有好多动作的概率以及当前的V;
有利的动作产生的下一刻状态可能有较高的V,但这个V是均值(暂时这么理解),也就是说,较高的V的下一层中可能有较低的V, 较低的V的下一层中也可能有更高的V 。所以,采用MCTS进行更深层的探索,有可能找到潜在的更优解。 -
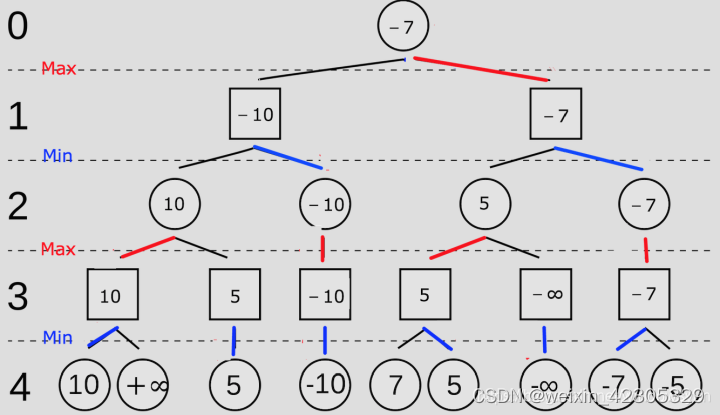
目标相反的博弈双方为何可以共用同一套神经网络
极大极小值算法:对于我方是max,对于敌方是min
AlphaGo zero 的部分原理理解

于 2023-10-23 21:01:13 首次发布

















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









