








 超级会员免费看
超级会员免费看

 本文介绍了利用funasr进行VAD语音端点检测,通过检测音频帧判断语音的开始和结束,提高切割准确性。接着探讨了sherpa的VAD+STT识别,结合模型进行非流式ASR识别,提供了模型下载链接和运行示例。
本文介绍了利用funasr进行VAD语音端点检测,通过检测音频帧判断语音的开始和结束,提高切割准确性。接着探讨了sherpa的VAD+STT识别,结合模型进行非流式ASR识别,提供了模型下载链接和运行示例。
1、VAD 语音端点检测(funasr)
Voice Activity Detection 语音活性检测(VAD)也被称为语音端点检测,基本原理是判断一个区间内的音频(区间被称为一个“语音帧”),是有效语音,还是无效语音。通过连续的检测多帧,就能判断出语音的“开头”(从无效到有效)和“结尾”(从有效到无效),完成语音的切割。VAD的准确性和语音信噪比正相关,安静的环境准确性更高,也是为何需要麦阵降噪处理后的信号再做VAD。

参考:
https://modelscope.cn/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch/summary
https://zhuanlan.zhihu.com/p/111516373
输出的是时间戳毫秒,一段一段,例如: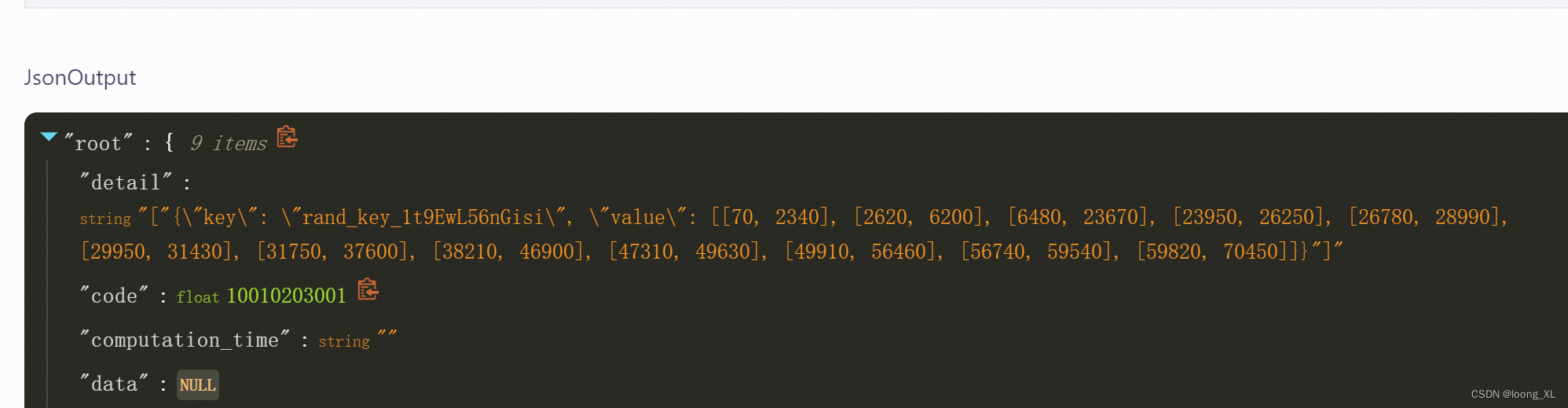
<

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 3264
3264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











