







 本文介绍了如何使用DNABERT和其改进版DNABERT-2将DNA序列视为连续文本,通过Transformer模型进行训练,特别关注了k-mer和BPEtoken切分方法,以及如何提取和处理特征向量,如平均池化和最大池化技术。
本文介绍了如何使用DNABERT和其改进版DNABERT-2将DNA序列视为连续文本,通过Transformer模型进行训练,特别关注了k-mer和BPEtoken切分方法,以及如何提取和处理特征向量,如平均池化和最大池化技术。
参考:
https://www.youtube.com/watch?v=mk-Se29QPBA&t=1388s
写明这些训练模型可以最终训练好可以进行DNA特征向量的提取,应用与后续

1、DNABERT
https://github.com/jerryji1993/DNABERT
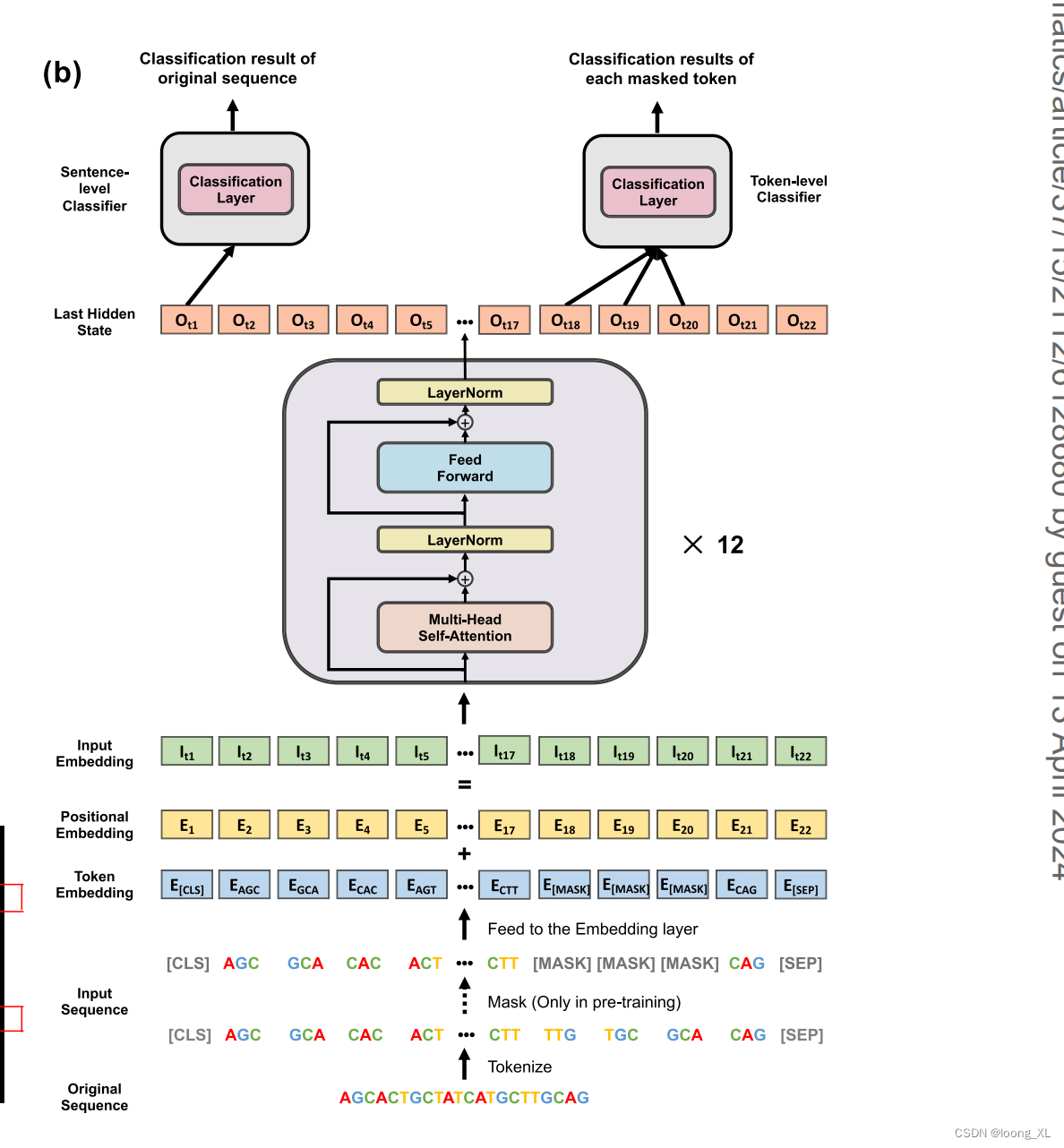
主要思路就是把DNA序列当成连续文本数据,直接用成熟的自然语言训练模型transformer进行生物DNA序列数据的训练
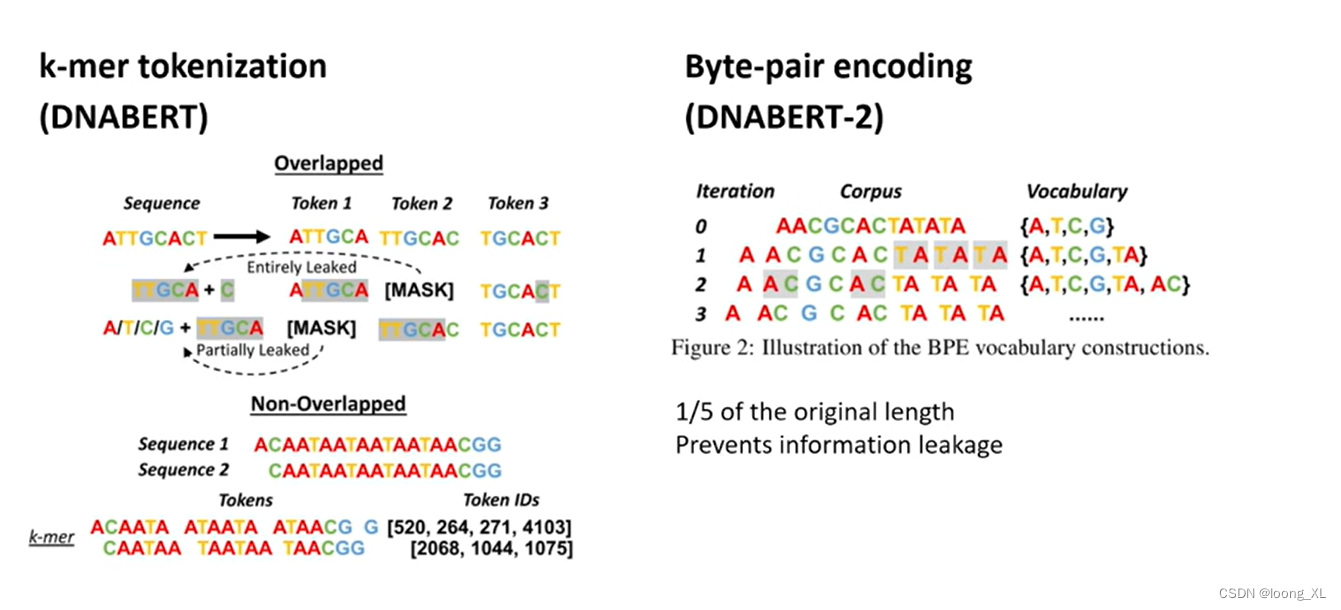
不同点主要就是ATCG序列切分token,DNA序创造了k-mer切分方法
3k-mer切分下图:

2、DNABERT-2
https://github.com/MAGICS-LAB/DNABERT_2
DNABERT-2主要是切词token方法的改进,用了transformer主流用的BPE token切分算法(参考学习:https://blog.csdn.net/xiao_ling_yun/article/details/129517312)
向量特征提前:
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("zhihan1996/DNABERT-2-117M", trust_remote_code=True)
model = AutoModel.from_pretrained("zhihan1996/DNABERT-2-117M", trust_remote_code=True)
dna = "ACGTAGCATCGGATCTATCTATCGACACTTGGTTATCGATCTACGAGCATCTCGTTAGC"
inputs = tokenizer(dna, return_tensors = 'pt')["input_ids"]
hidden_states = model(inputs)[0] # [1, sequence_length, 768]
# embedding with mean pooling
embedding_mean = torch.mean(hidden_states[0], dim=0)
print(embedding_mean.shape) # expect to be 768
# embedding with max pooling
embedding_max = torch.max(hidden_states[0], dim=0)[0]
print(embedding_max.shape) # expect to be 768



















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











