







文章目录
0. 代码数据下载
关注公众号:『AI学习星球』
添加微信小助手 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或CSDN滴滴我

1. 背景介绍
共享单车系统是一种租赁自行车的方法,注册会员、租车、还车都将通过城市中的站点网络自动完成。
使用共享单车,可以注册会员,存入一定金额用于使用结束后自动扣费结算;
也可以不注册会员,临时使用后通过其提供的支付方式结算费用。
人们通过下载APP使用这个系统进行扫码开锁取车,然后从取车地骑到自己的目的地后停放锁车归还,系统自动按实际使用时长计费。
2. 提出问题
- 共享单车的用户结构分布如何?
- 共享单车的用户数与哪些因素有关?
- 通过数据分析,提取出可以帮助增加用户数的信息,或提出建议。
3. 理解数据
数据介绍
数据源中有三个csv文件,分别为:sampleSubmission.csv、test.csv、train.csv。
考虑此分析仅做描述性分析,因此只选择train.csv文件的数据集。train.csv文件是跨越2011-2012年两年的每小时租赁数据,包含天气信息和日期信息,每月只有1-19号的数据,全部数据为10886行12列,各列的字段含义如下:
| 字段名称 | 含义 | 例子 |
|---|---|---|
| Datetime | 时间 | 年:2011-2012,月:1-12,日:1-19(号) |
| Season | 季节 | 1:春天,2:夏天,3:秋天,4:冬天 |
| Holiday | 假期 | 1:是,0:否 |
| Workingday | 工作日 | 1:是,0:否 |
| Weather | 天气 | 1:晴朗、少云,2:多云、薄雾,3:小雨、小雪,4:大雨、大雪 |
| Temp | 摄氏度 | |
| Atemp | 体感温度 | |
| Humidity | 湿度 | |
| Windspeed | 风度 | |
| Casual | 未注册用户 | |
| Registered | 已注册用户 | |
| Count | 总用户数 | 总用户数=未注册用户+已注册用户 |
4. 数据清洗
4.1 导入数据
a. 导入数据处理包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 中文乱码处理
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
b. 导入数据集
bike_data=pd.read_csv('train.csv')
print("数据集:",bike_data)
4.2 洞察数据
a. 查看数据前5列,观察数据结构
bike_data.head()

b. 查看数据集信息、检查缺失值
bike_data.info()
c. 查看数据描述性信息,检查异常值
bike_data.describe()
4.3 数据清洗
- 通过观察数据信息,发现数据完整无缺失;count的数值差异大是因为凌晨时间段用户数量过少,而早晚上班高峰期用户数量大导致。
- 为了方便可视化数据,把datetime拆分成:日期、年、月、天、小时、星期共6列,把日期数据的文本类型转换成数据类型。
bike_data['date'] = bike_data['datetime'].apply(lambda x:x.split()[0])
bike_data['year'] = bike_data['datetime'].apply(lambda x:x.split()[0].split('-')[0]).astype('int64')
bike_data['month'] = bike_data['datetime'].apply(lambda x:x.split()[0].split('-')[1]).astype('int64')
bike_data['day'] = bike_data['datetime'].apply(lambda x:x.split()[0].split('-')[2]).astype('int64')
bike_data['hour'] = bike_data['datetime'].apply(lambda x:x.split()[1].split(':')[0]).astype('int64')
bike_data['weekday'] = bike_data['datetime'].apply(lambda x:pd.to_datetime(x).weekday())
bike_data.head()
a. 分类数据特征提取:季节
seasonDf=pd.DataFrame()
# 使用get-dummies进行one-hot编码,列名前缀是season
seasonDf=pd.get_dummies(bike_data.season,prefix='season')
seasonDf.head()
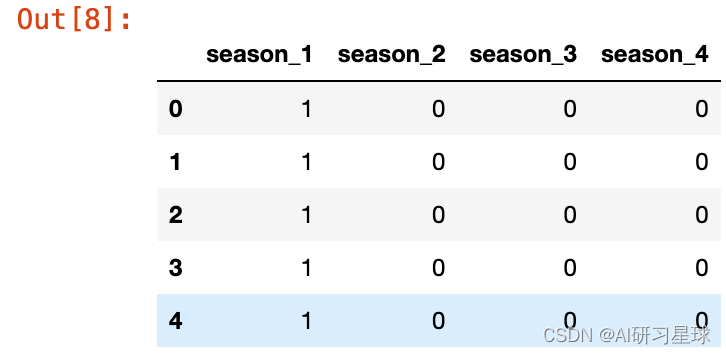
bike_data = pd.concat([bike_data,seasonDf],axis=1)
b. 分类数据特征提取:天气
weatherDf=pd.DataFrame()
# 使用get-dummies进行one-hot编码,weather
seasonDf=pd.get_dummies(bike_data.season,prefix='weather')
seasonDf.head()
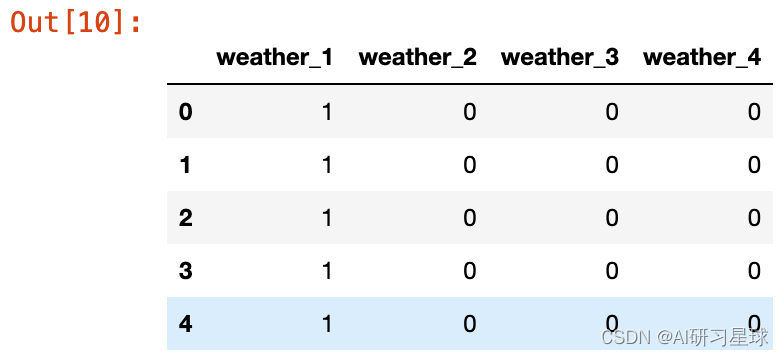
bike_data=pd.concat([bike_data,weatherDf],axis=1)
关注公众号:『AI学习星球』
添加微信小助手 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或CSDN滴滴我
5. 数据可视化分析
5.1 数据整体分析
a. 查看用户结构情况
fig=plt.subplots(figsize=(20,20))
ax1=plt.subplot(3,3,1)
df_number=bike_data[['casual','registered']].sum()
plt.pie(df_number,labels=['非注册用户','注册用户'],shadow=True,autopct='%1.1f%%')
plt.title('用户结构图')
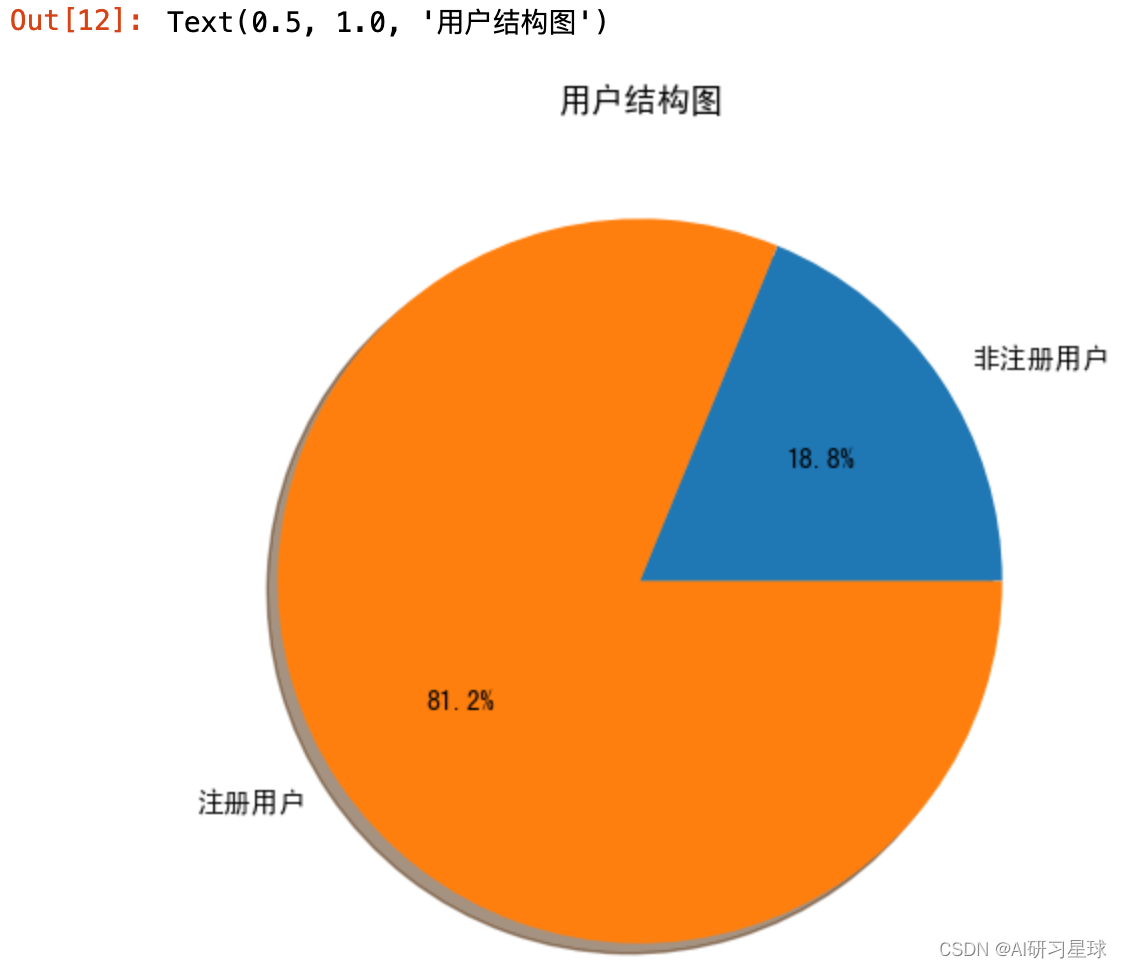
发现在用车客户的总用户数中已注册客户比例较高
b. 查看用户总数在这两年内的变化趋势
# 使用折线图查看总体租凭情况(count)随时间的走势
# 按月汇总用户数平均数
df_count2=bike_data.groupby(['year','month'],as_index=False).agg({'date':'min','count':'mean'})
# 设置画框尺寸
fig=plt.figure(figsize=(25,10))
ax=plt.subplot(1,1,1)
plt.plot(df_count2['date'],df_count2['count'],marker='o',linewidth=1.3,label='Monthly average')
ax.set_title('两年内月均人数变化趋势',fontsize=20)
ax.set_xlabel('日期',fontsize=20,weight='light')
ax.set_ylabel('人数',rotation=360,fontsize=20,weight='light')
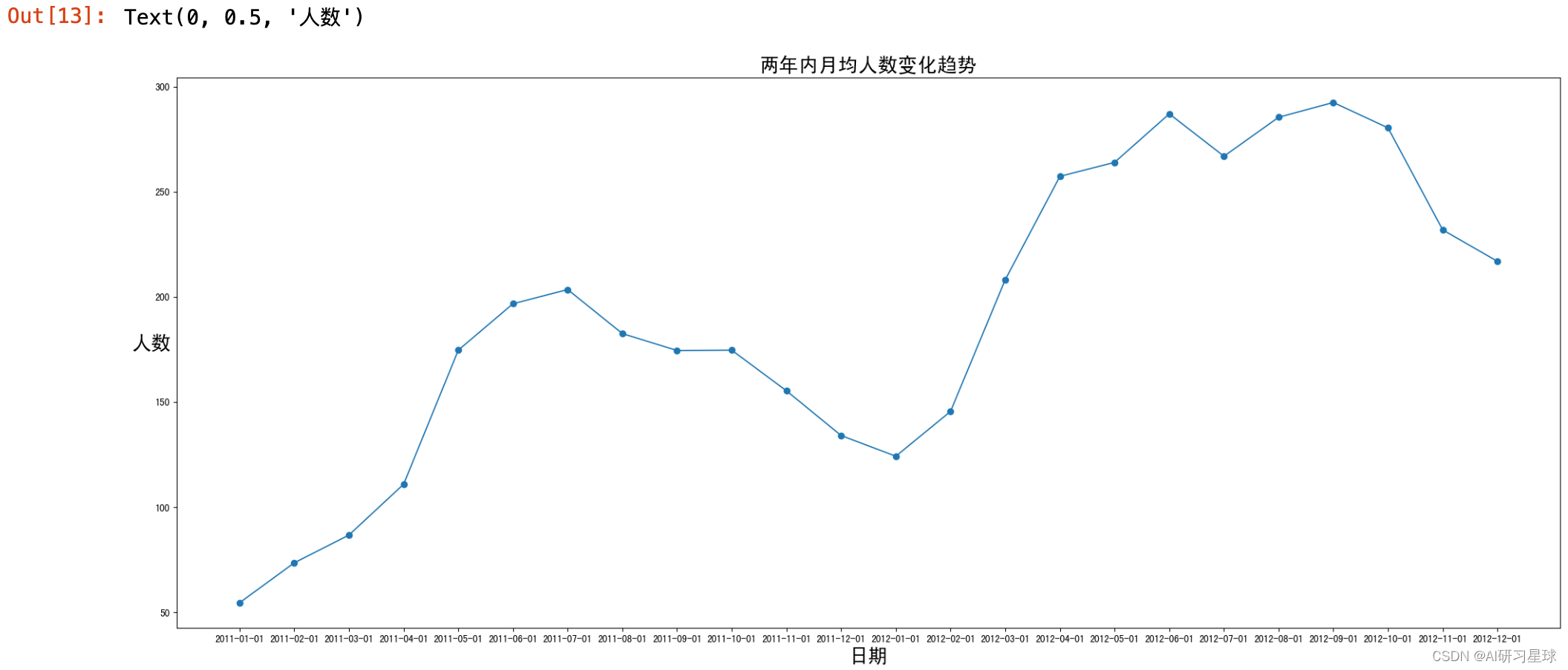
由图可知,总用户数量在这两年内保持持续增长的趋势。
5.2 用户数量与时间维度(季节、工作日、假期、月份、时刻等)因素的分析
a. 查看用户数量在不同月份、季节的情况
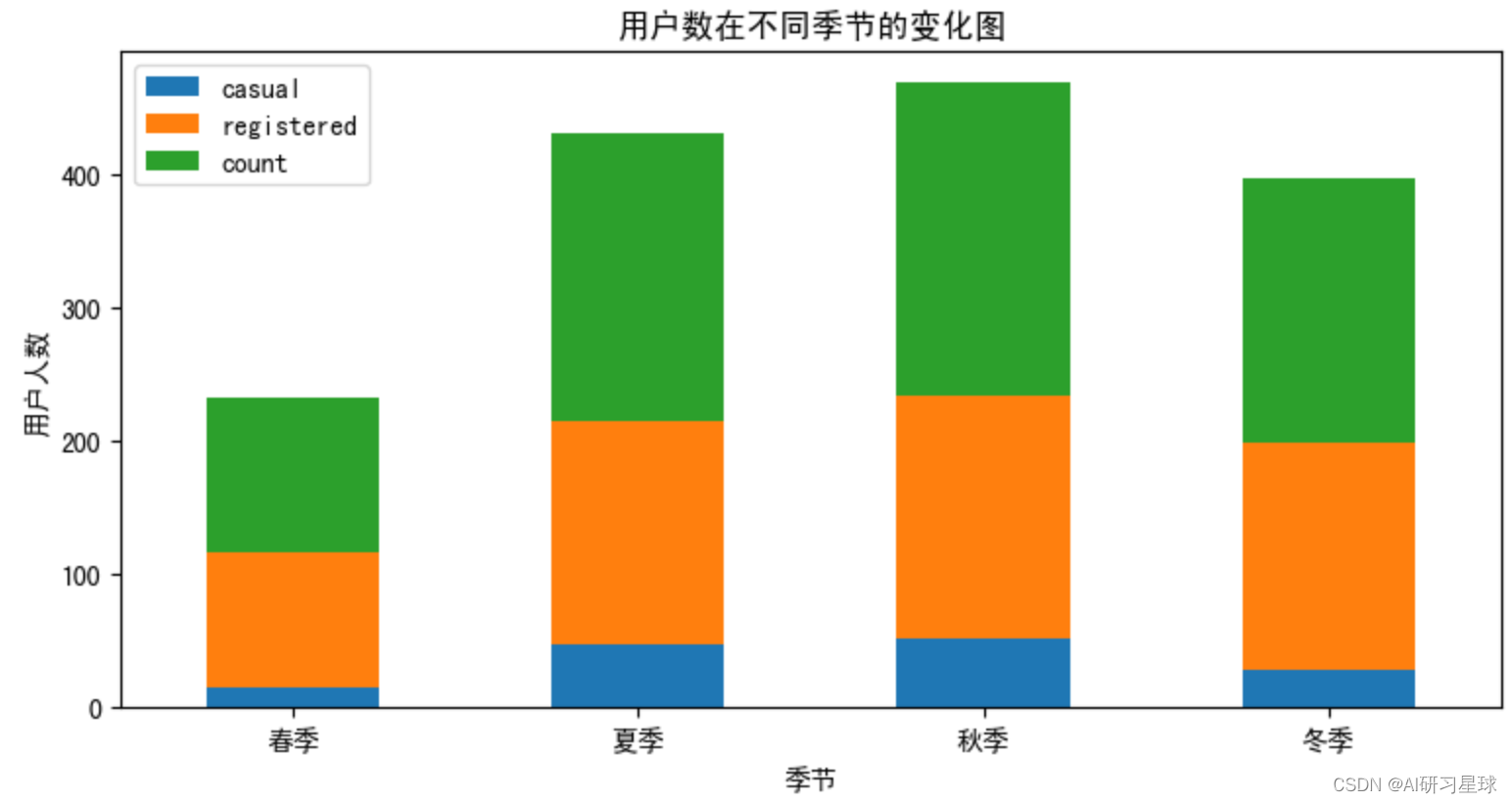
# 查看用户数在不同季节的变化
fig=plt.subplots(figsize=(20,20))
ax1=plt.subplot(4,2,1)
df_season=bike_data.groupby([bike_data['season']]).agg({'casual':'mean','registered':'mean','count':'mean'})
df_season.plot.bar(title='用户数在不同季节的变化图',stacked=True,ax=ax1)
ax1.set_xticklabels(['春季','夏季','秋季','冬季'],rotation='horizontal')
plt.xlabel('季节')
plt.ylabel('用户人数')
plt.show()
# 查看用户数在不同月份的变化
fig=plt.figure(figsize=(20,20))
ax2=ax1=fig.add_subplot(4,2,1)
df_month=bike_data.groupby([bike_data['month']]).agg({'casual':'mean','registered':'mean','count':'mean'})
# df_month.plot.bar(title='用户数在不同季节的变化图',stacked=True,ax=ax1)
df_month.plot(ax=ax2,)
plt.title('用户数在不同月份的变化图')
plt.xlabel('时间(月)')
plt.ylabel('用户人数')
plt.show()
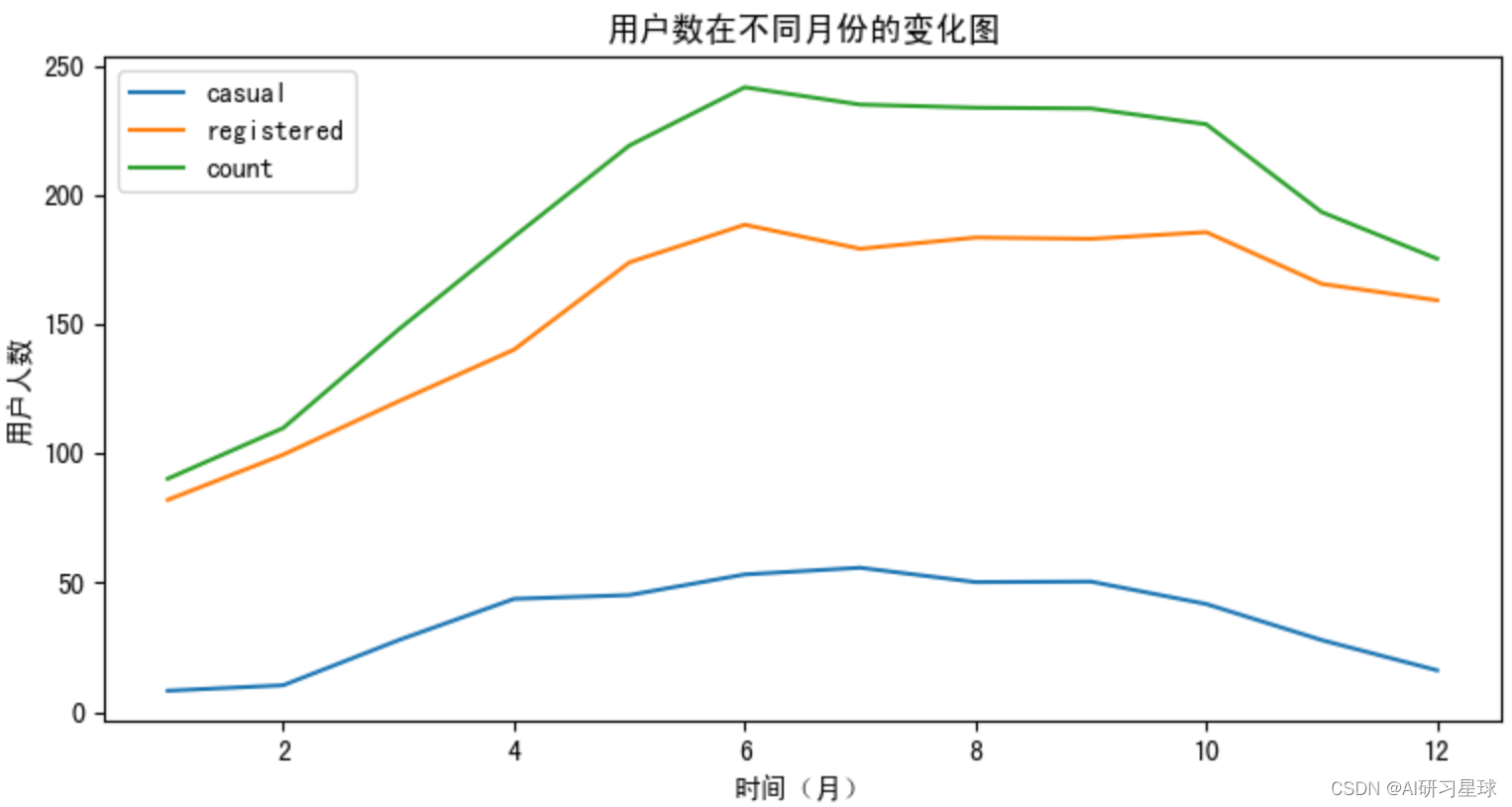
由图可知,用户数高峰期在秋季和夏季,其次是冬季,而最少在春季,是因为受春节期间影响。
b. 查看用户数分别在工作日和假期的分布情况
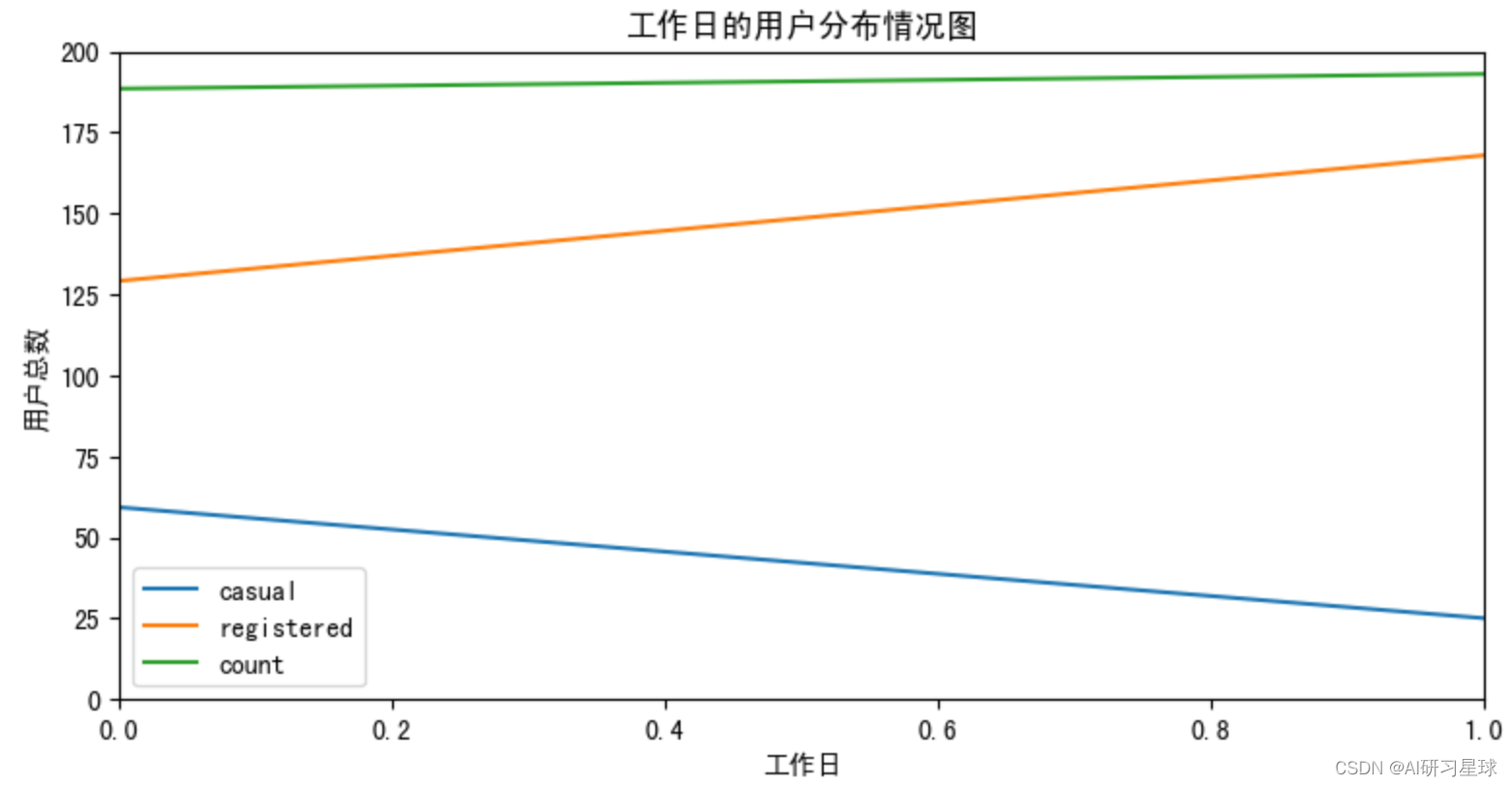
# 查看用户数在工作日的分布情况
# Workingday:工作日(非节假日或周末,(1:是,0:否))
fig=plt.subplots(figsize=(20,20))
ax6=plt.subplot(4,2,1)
df_workingday=bike_data.groupby([bike_data['workingday']]).agg({'casual':'mean','registered':'mean','count':'mean'})
df_workingday.plot(title='工作日的用户分布情况图',ax=ax6)
plt.axis([0,1,0,200])
plt.ylabel('用户总数')
plt.xlabel('工作日')
plt.show()
# 查看用户数在假期的分布情况
# Holiday:假期(1:是,0:否)
fig = plt.subplots(figsize=(20,20))
ax7=plt.subplot(4,2,1)
df_holiday=df=bike_data.groupby([bike_data['holiday']]).agg({'casual':'mean','registered':'mean','count':'mean'})
df_workingday.plot.bar(title='假期的用户分别情况图',ax=ax7,stacked=True)
plt.ylabel('用户总数')
plt.xlabel('假期')
plt.show()
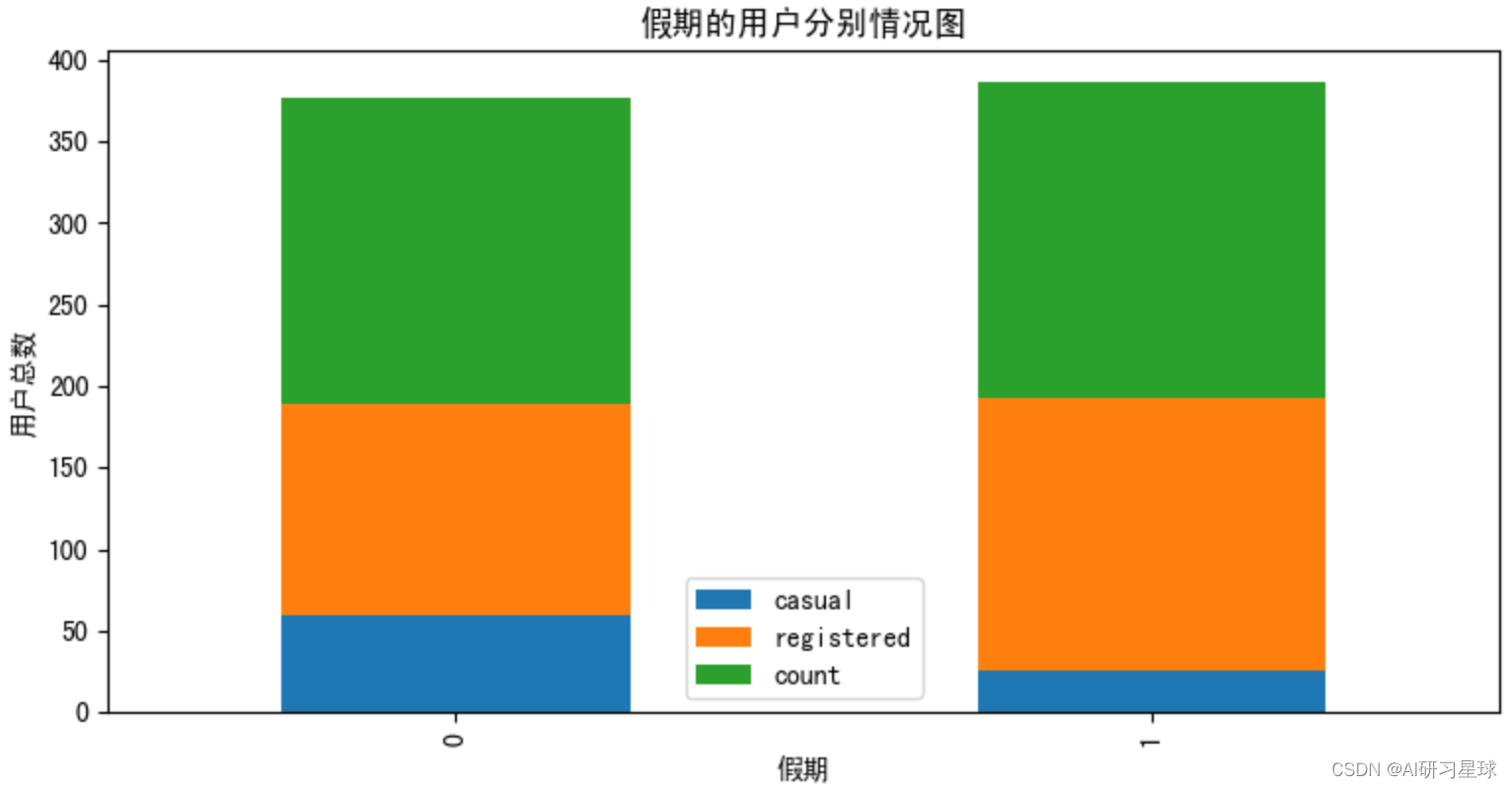
由图可见,用户总数在工作日和假期区别不大,而注册用户在工作日增多假期减少,非注册用户在假期增多工作日减少。
c. 查看用户数分别在工作日和假期的时刻分布情况
bike_data_workingday = bike_data[bike_data['workingday']==1]
bike_data_workingday.head()
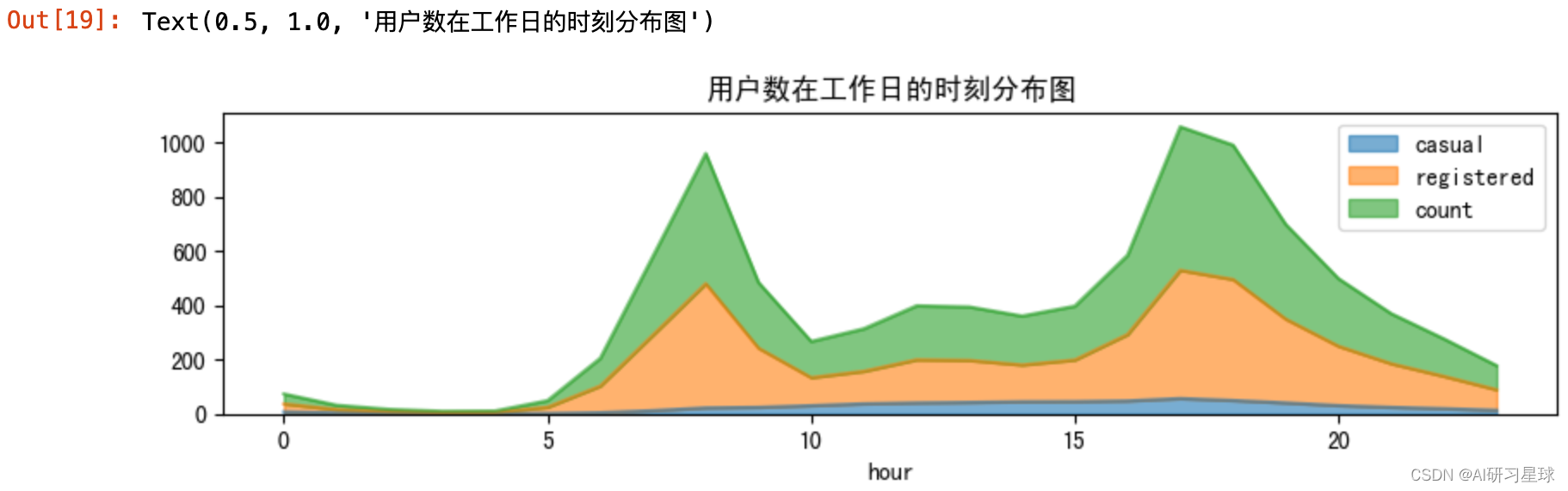
# 查看用户数在工作日的时刻分布图
fig = plt.figure(figsize=(10,5))
ax13 = fig.add_subplot(2,1,1)
df_workingday = bike_data_workingday.groupby([bike_data_workingday['hour']]).agg({'casual':'mean','registered':'mean','count':'mean'})
df_workingday.plot(ax=ax13,kind='area',alpha=0.6)
plt.title('用户数在工作日的时刻分布图')
# 查看用户数在假期的时刻分布情况
# Holiday:假期(1:是,0:否)
bike_data_holiday=bike_data[bike_data['holiday']==1]
fig = plt.figure(figsize=(10,5))
ax14 = fig.add_subplot(2,1,2)
df_holiday=bike_data_holiday.groupby([bike_data_holiday['hour']]).agg({'casual':'mean','registered':'mean','count':'mean'})
df_workingday.plot(ax=ax14,kind='area',alpha=0.6)
plt.title('用户数在假期的时刻分布图')
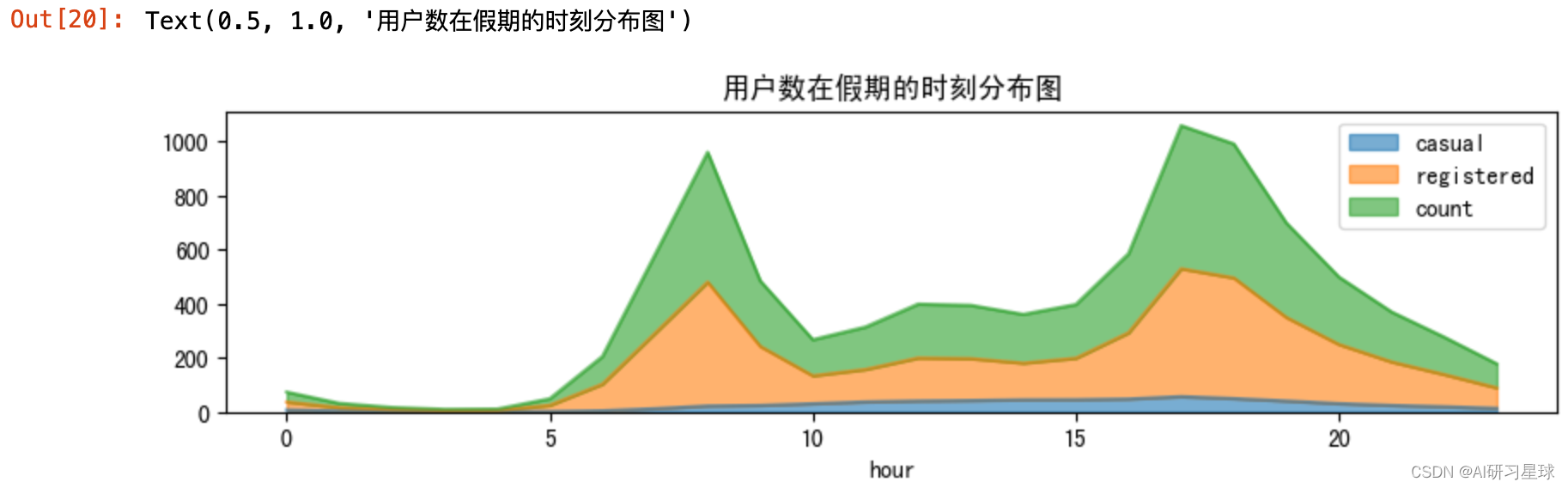
由图可知,用户数在工作日分布图中出现两个波峰,对应为上下班时间,为通勤高峰期。而在假期,用户数在白天时间段8-18(点)持续上升保持较高数量,夜间持续下降保持较低数量,符合人们白天外出游玩需要用车,夜间休息的生活规律。
5.3 查看用户数量与天气维度(天气、摄氏度、体感温度、湿度、风速)因素的分析
a. 查看用户数在不同天气状态下的情况
# 查看用户数在不同天气状态下的情况
fig = plt.subplots(figsize=(20,20))
ax1=plt.subplot(4,2,1)
df_season=bike_data.groupby([bike_data['weather']]).agg({'casual':'mean','registered':'mean','count':'mean'})
df_season.plot.bar(title='总用户数在不同天气状态的变化图',stacked=True,ax=ax1)
ax1.set_xticklabels(['晴朗少云','多云薄雾','小雨或小雪','大雨或大雪'],rotation='horizontal')
plt.xlabel('天气')
plt.ylabel('用户数量')
plt.show()

由图可见,在晴朗少云的天气用车人数最多,而少雨或小雪天气用车人数则最少。
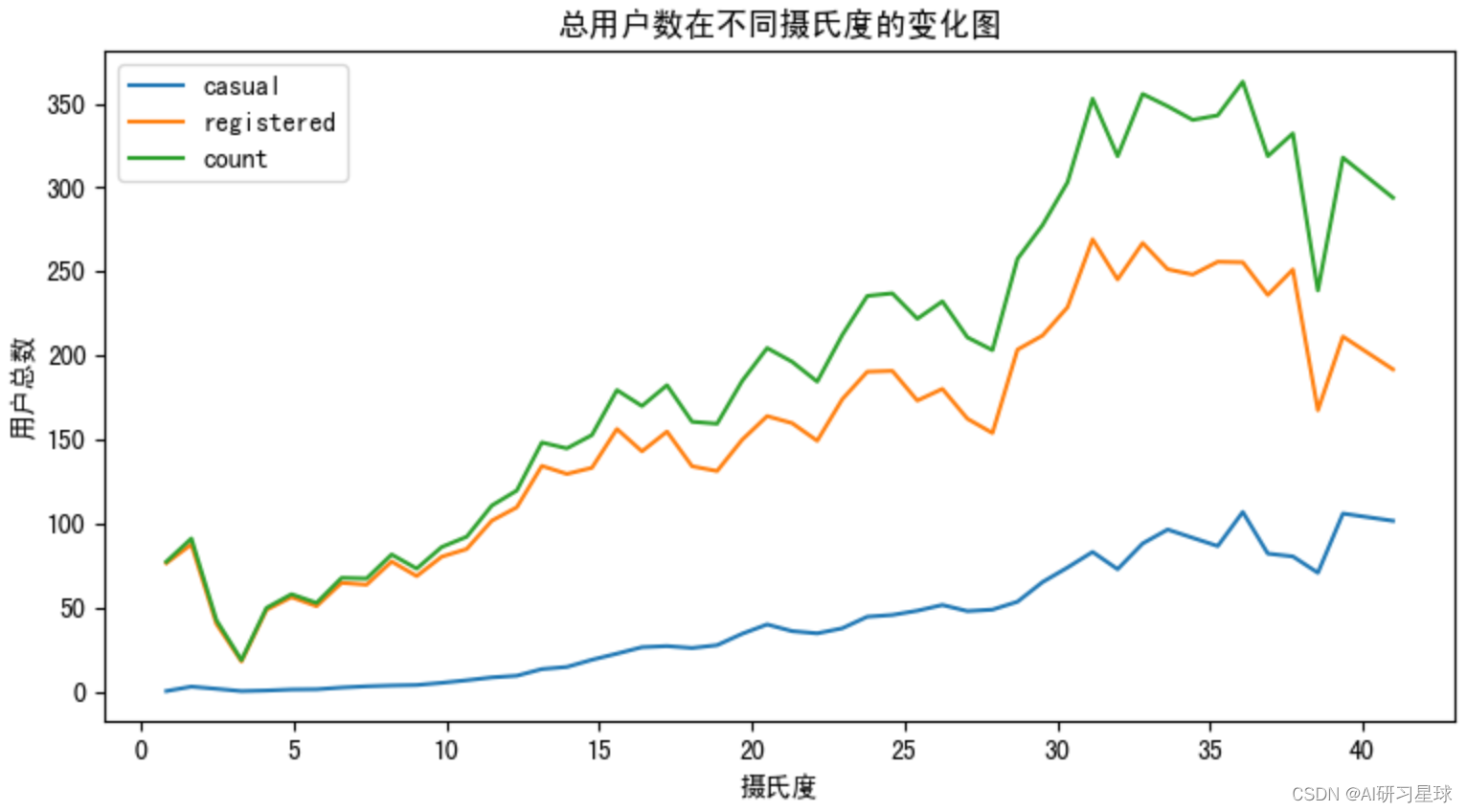
b. 查看用户数在不同摄氏度和体感温度的变化情况
# 查看摄氏度与用户总数的图形关系
fig = plt.subplots(figsize=(20,10))
ax1 = plt.subplot(2,2,1)
df = bike_data.groupby([bike_data['temp']]).agg({'casual':'mean','registered':'mean','count':'mean'})
df.plot(ax=ax1,title='总用户数在不同摄氏度的变化图')
plt.xlabel('摄氏度')
plt.ylabel('用户总数')
plt.show()
# 查看体感温度与用户总数的图形关系
fig = plt.figure(figsize=(20,10))
ax10 = fig.add_subplot(2,2,2)
df = bike_data.groupby([bike_data['atemp']]).agg({'casual':'mean','registered':'mean','count':'mean'})
df.plot(ax=ax10,title='总用户数在不同体感温度的变化图')
plt.xlabel('体感温度')
plt.ylabel('用户总数')
plt.show()
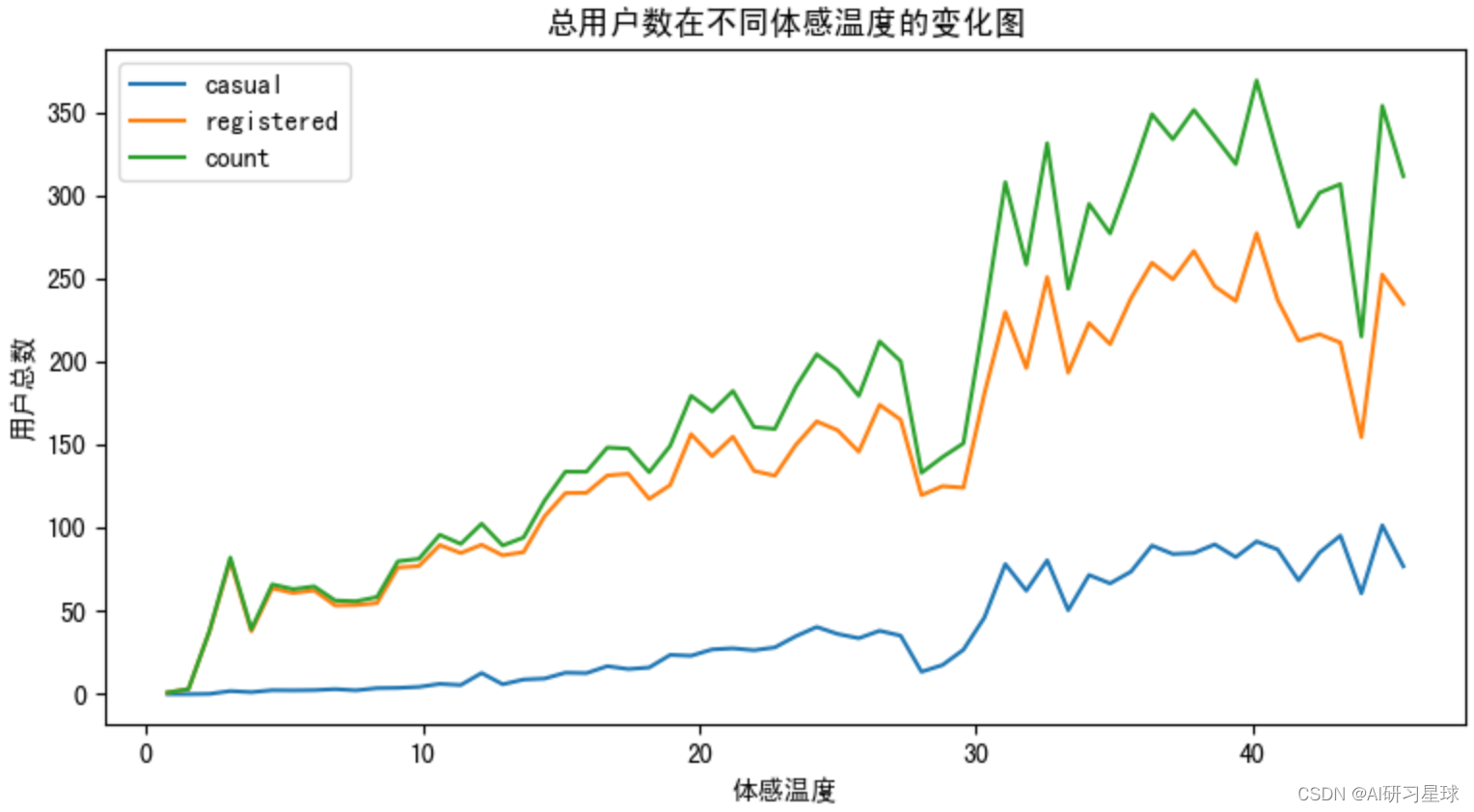
由图可见,用户数量随着温度升高而逐渐增加,在30-40摄氏度之间达到高峰。
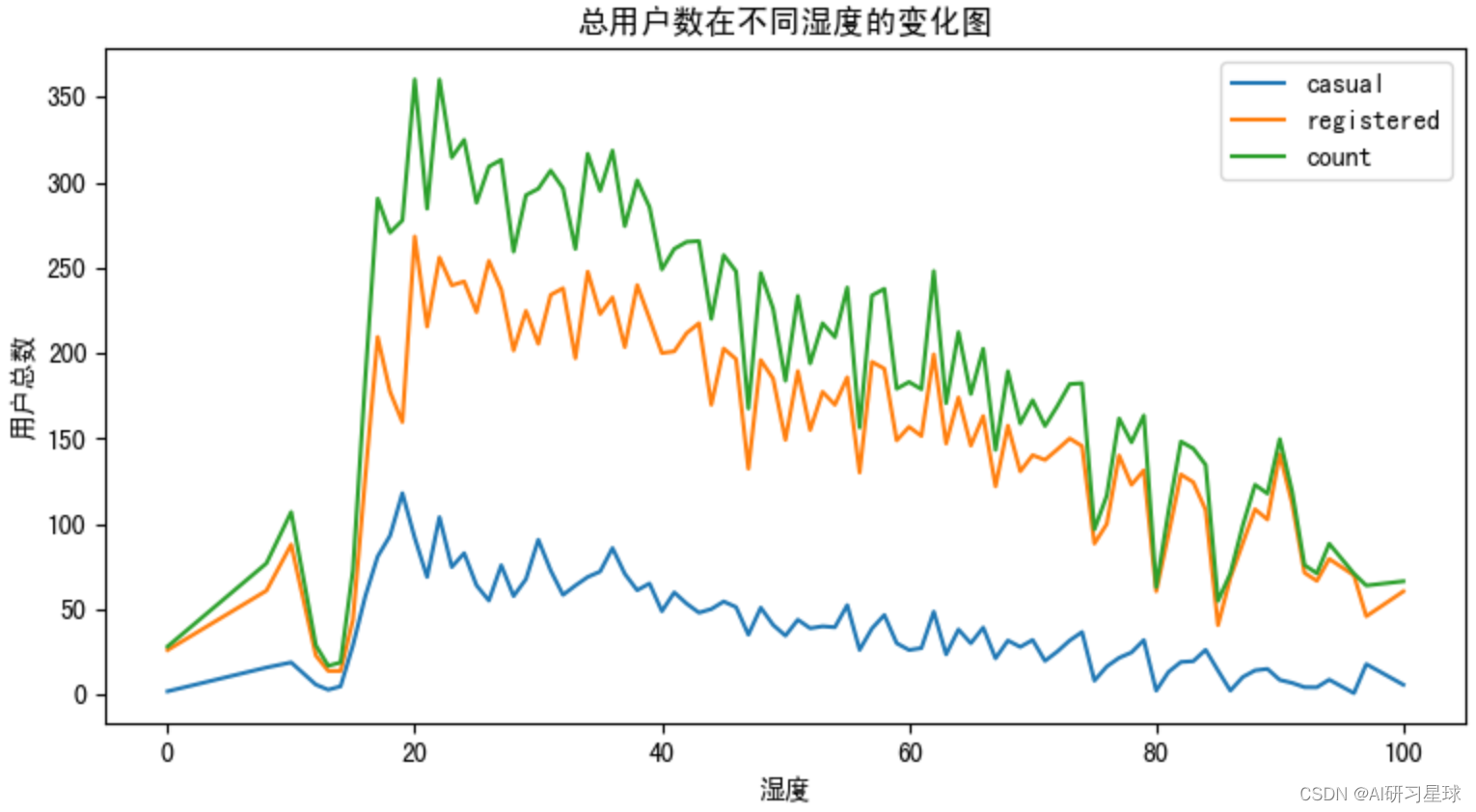
c. 查看用户数在湿度和风速的变化情况
# 查看湿度与用户总数的图形关系
fig = plt.figure(figsize=(20,10))
ax3 = fig.add_subplot(2,2,3)
df = bike_data.groupby([bike_data['humidity']]).agg({'casual':'mean','registered':'mean','count':'mean'})
df.plot(ax=ax3,title='总用户数在不同湿度的变化图')
plt.xlabel('湿度')
plt.ylabel('用户总数')
plt.show()
# 查看湿度与用户总数的图形关系
fig = plt.figure(figsize=(20,10))
ax4 = fig.add_subplot(2,2,3)
df = bike_data.groupby([bike_data['windspeed']]).agg({'casual':'mean','registered':'mean','count':'mean'})
df.plot(ax=ax4,title='总用户数在不同风度的变化图')
plt.xlabel('风度')
plt.ylabel('用户总数')
plt.show()
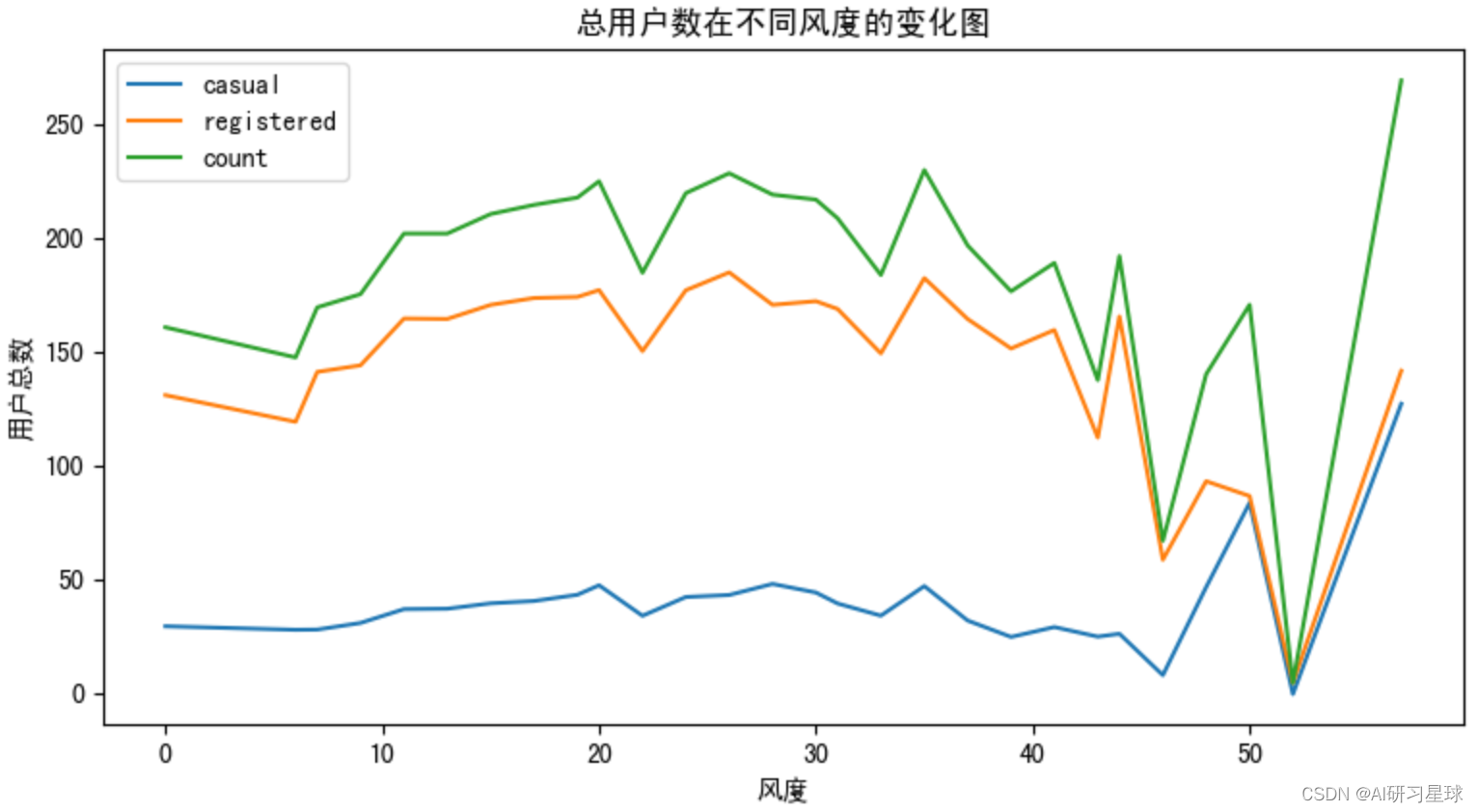
由图可见,用户数量在湿度的20-25之间时达到高峰,而后随着湿度增加,用户数量逐渐减少;而用户数在风速0-45之间基本保持平稳,在风速达45之后大起大落,受大风天气影响较明显。
关注公众号:『AI学习星球』
添加微信小助手 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或CSDN滴滴我
5.4 查看用户总数受哪些因素影响
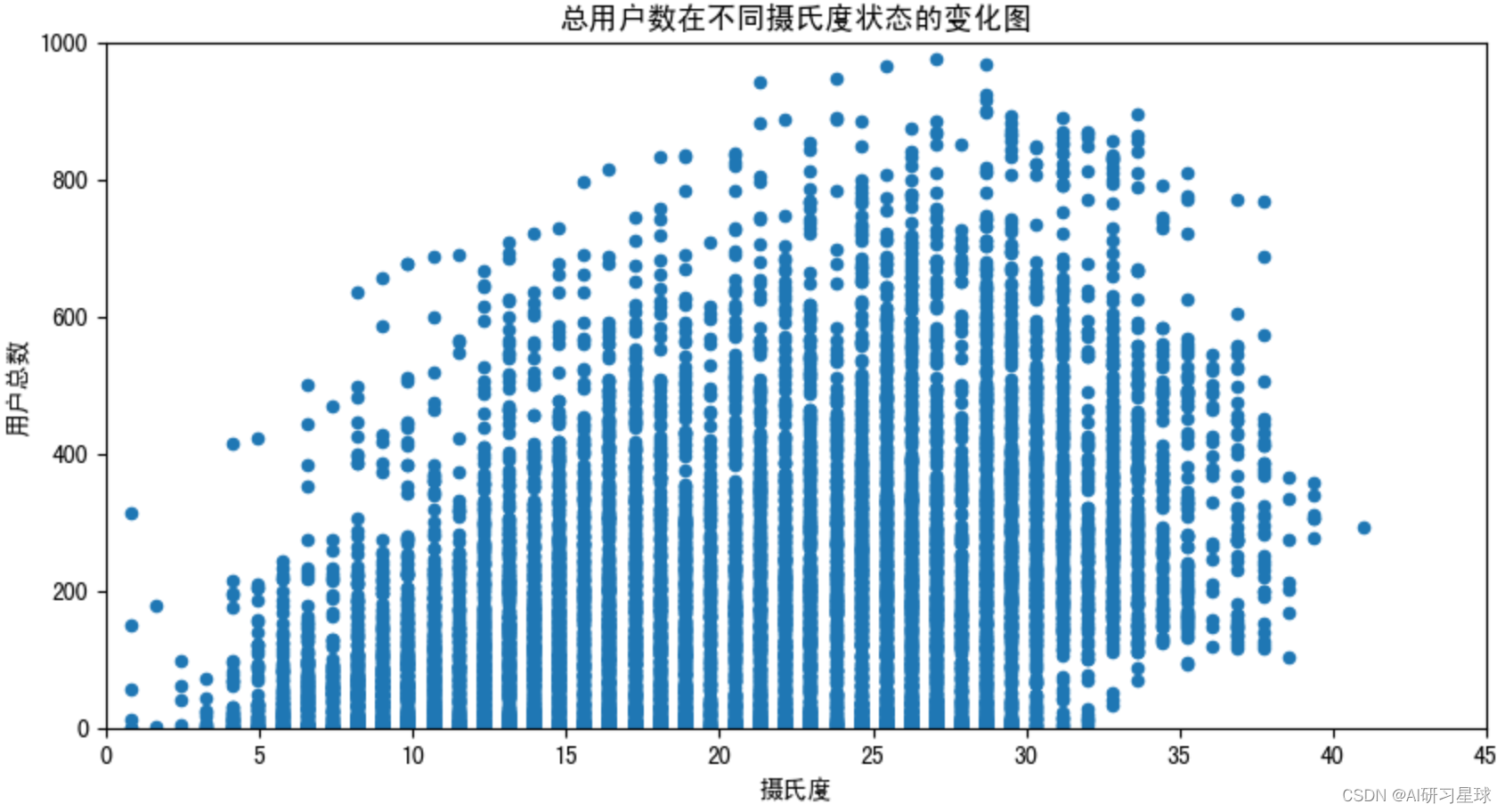
a. 查看用户总数与摄氏度、体感温度的相关性分布
# 查看摄氏度与用户总数的图形关系
fig = plt.figure(figsize=(10,5))
ax2 = fig.add_subplot(1,1,1)
df_temp = bike_data[['temp','count']]
df_temp.plot(x='temp',y='count',kind='scatter',ax=ax2)
plt.xlabel('摄氏度')
plt.ylabel('用户总数')
plt.title('总用户数在不同摄氏度状态的变化图')
plt.axis([0,45,0,1000])
plt.show()
# 查看体感温度与用户总数的图形关系
fig = plt.figure(figsize=(10,5))
ax3 = fig.add_subplot(1,1,1)
df_temp = bike_data[['atemp','count']]
df_temp.plot(x='atemp',y='count',kind='scatter',ax=ax3)
plt.xlabel('体感温度')
plt.ylabel('用户总数')
plt.title('总用户数在不同体感温度状态的变化图')
plt.axis([0,45,0,1000])
plt.show()
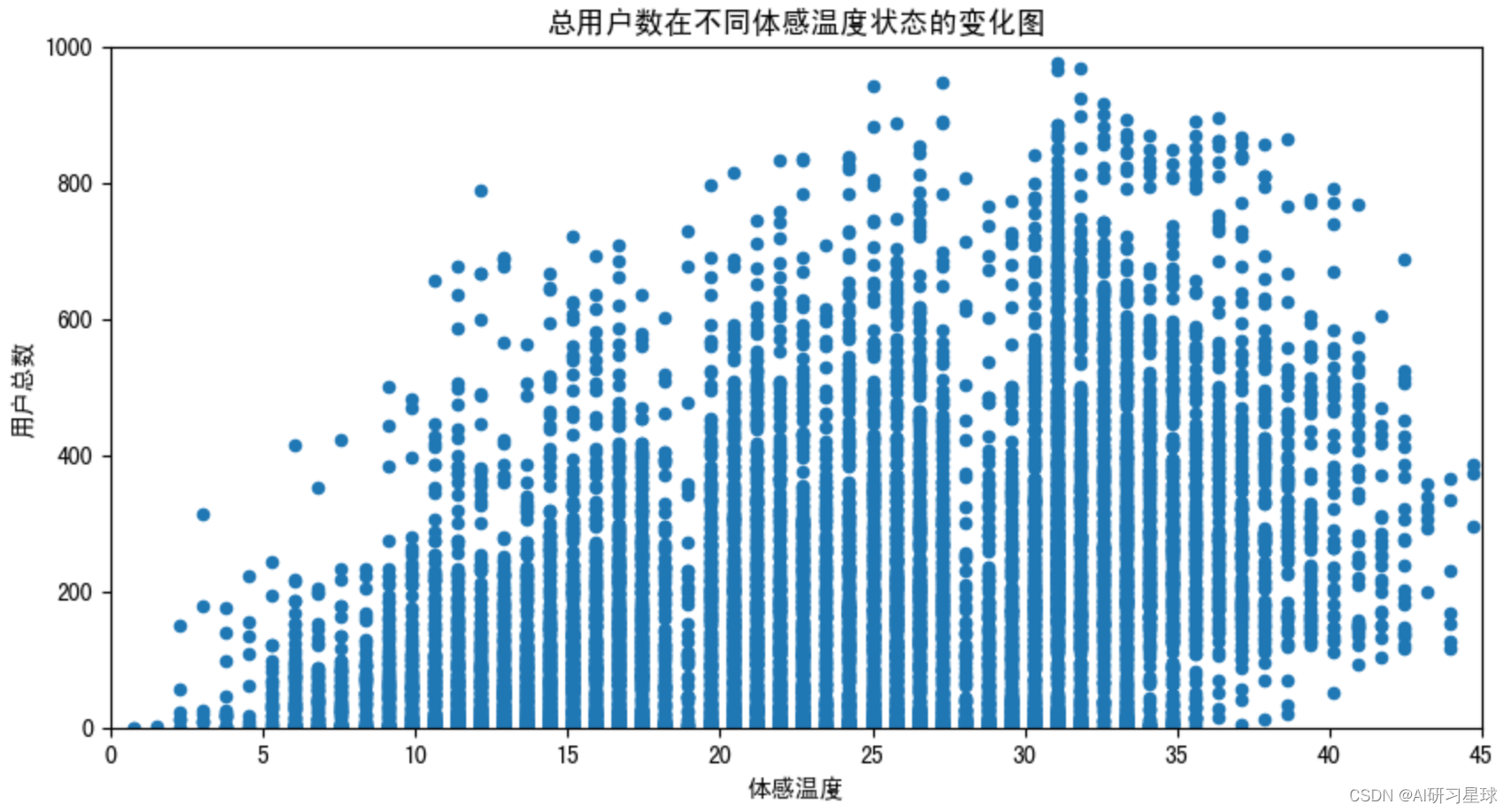
由图可见,用户总数与摄氏度和体感温度成线性相关。
b. 查看用户总数与湿度、风度的相关性分布
# 查看湿度与用户总数的图形关系
fig = plt.figure(figsize=(10,5))
ax2 = fig.add_subplot(1,1,1)
df_temp = bike_data[['humidity','count']]
df_temp.plot(x='humidity',y='count',kind='scatter',ax=ax2)
plt.xlabel('湿度')
plt.ylabel('用户总数')
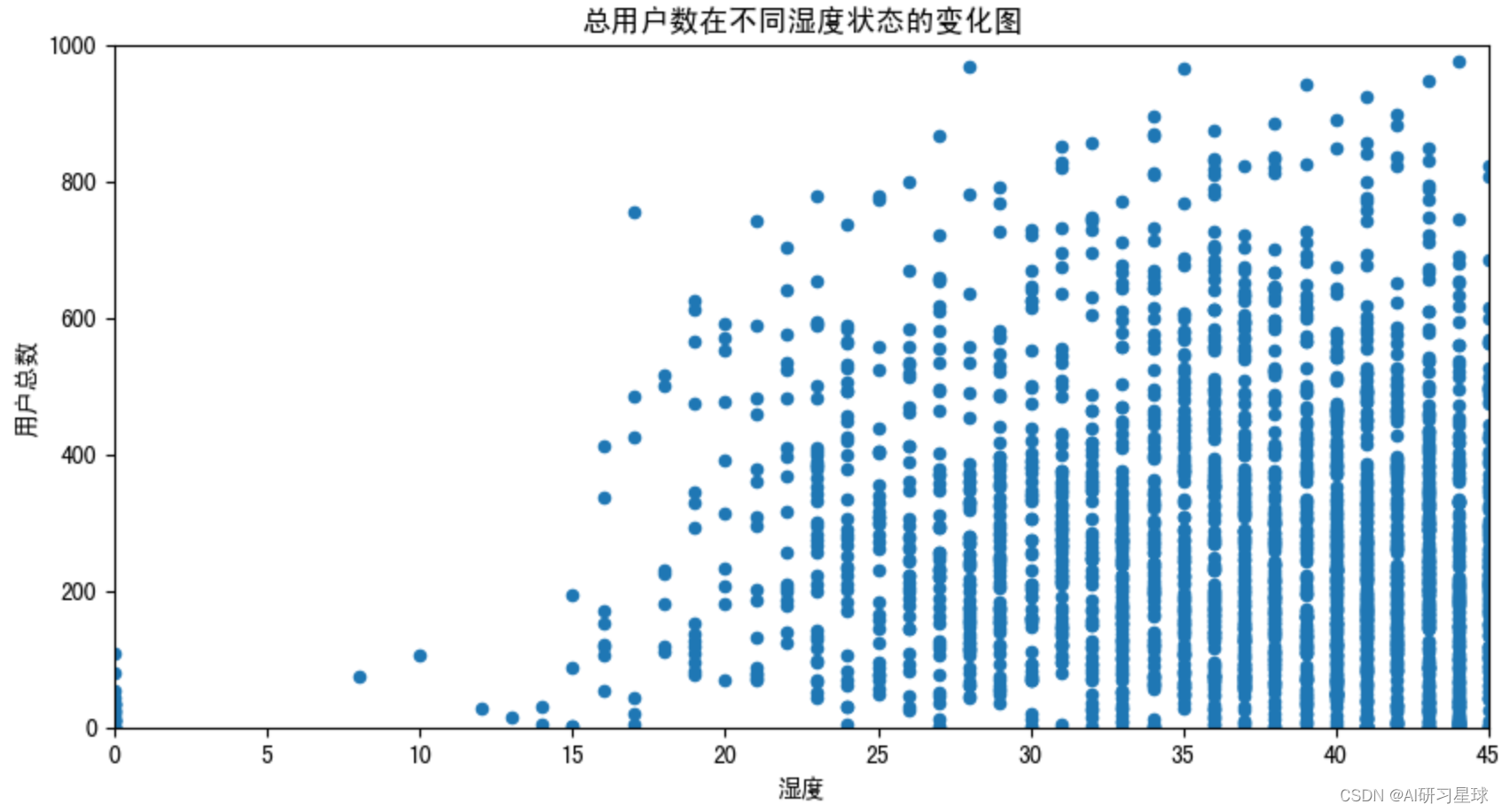
plt.title('总用户数在不同湿度状态的变化图')
plt.axis([0,45,0,1000])
plt.show()
# 查看风度与用户总数的图形关系
fig = plt.figure(figsize=(10,5))
ax3 = fig.add_subplot(1,1,1)
df_temp = bike_data[['windspeed','count']]
df_temp.plot(x='windspeed',y='count',kind='scatter',ax=ax3)
plt.xlabel('风度')
plt.ylabel('用户总数')
plt.title('总用户数在不同风度状态的变化图')
plt.axis([0,45,0,1000])
plt.show()
而图可见,用户数与湿度成线性相关;而与风度相关性不明显。
c. 查看用户总数与时刻的相关性分布
# 查看hour与用户总数的图形关系
fig = plt.figure(figsize=(10,5))
ax2 = fig.add_subplot(1,1,1)
df_temp = bike_data[['hour','count']]
df_temp.plot(x='hour',y='count',kind='scatter',ax=ax2)
plt.xlabel('时刻')
plt.ylabel('用户总数')
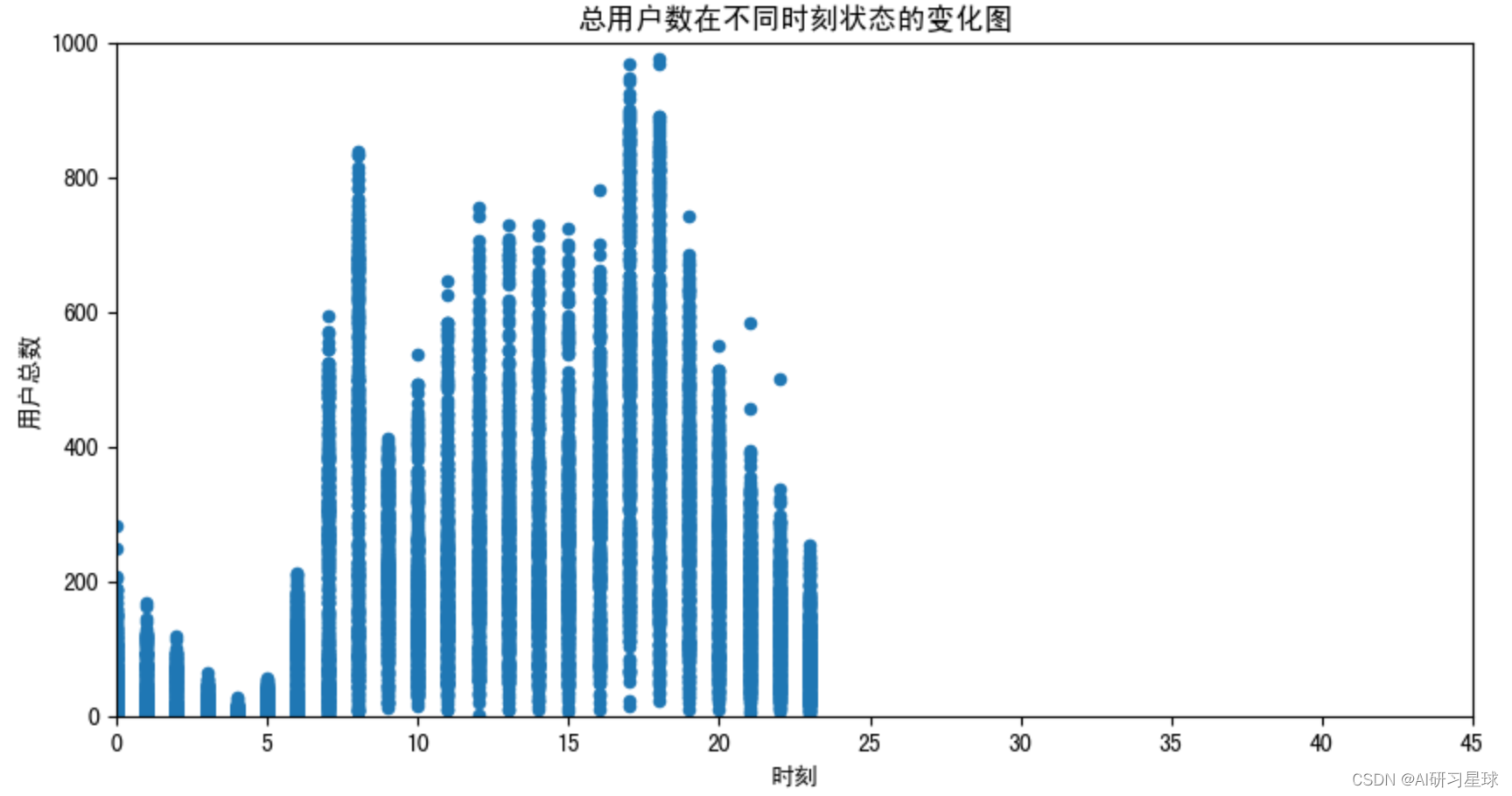
plt.title('总用户数在不同时刻状态的变化图')
plt.axis([0,45,0,1000])
plt.show()
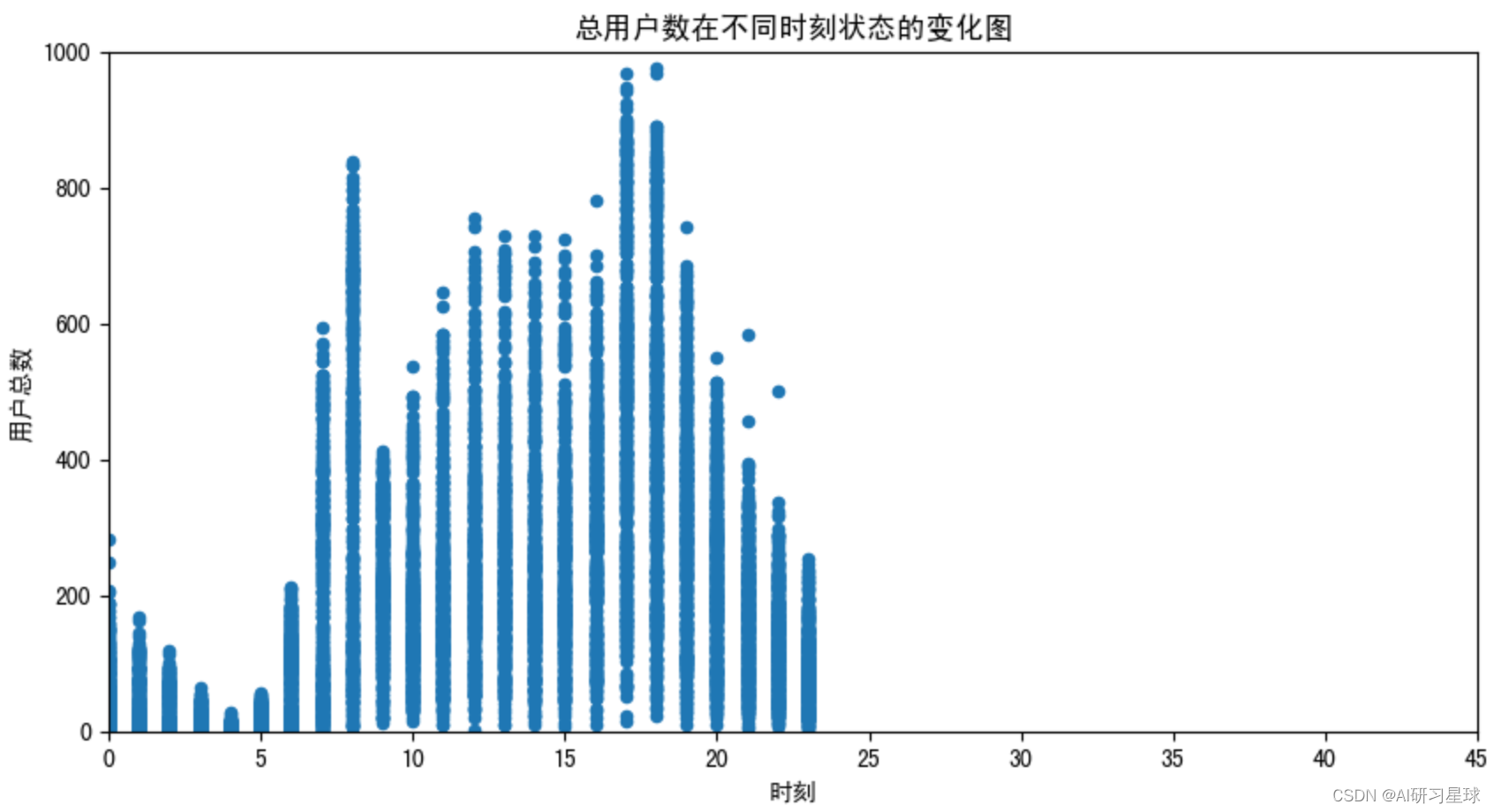
由图可见,用户总数与时刻成线性相关。
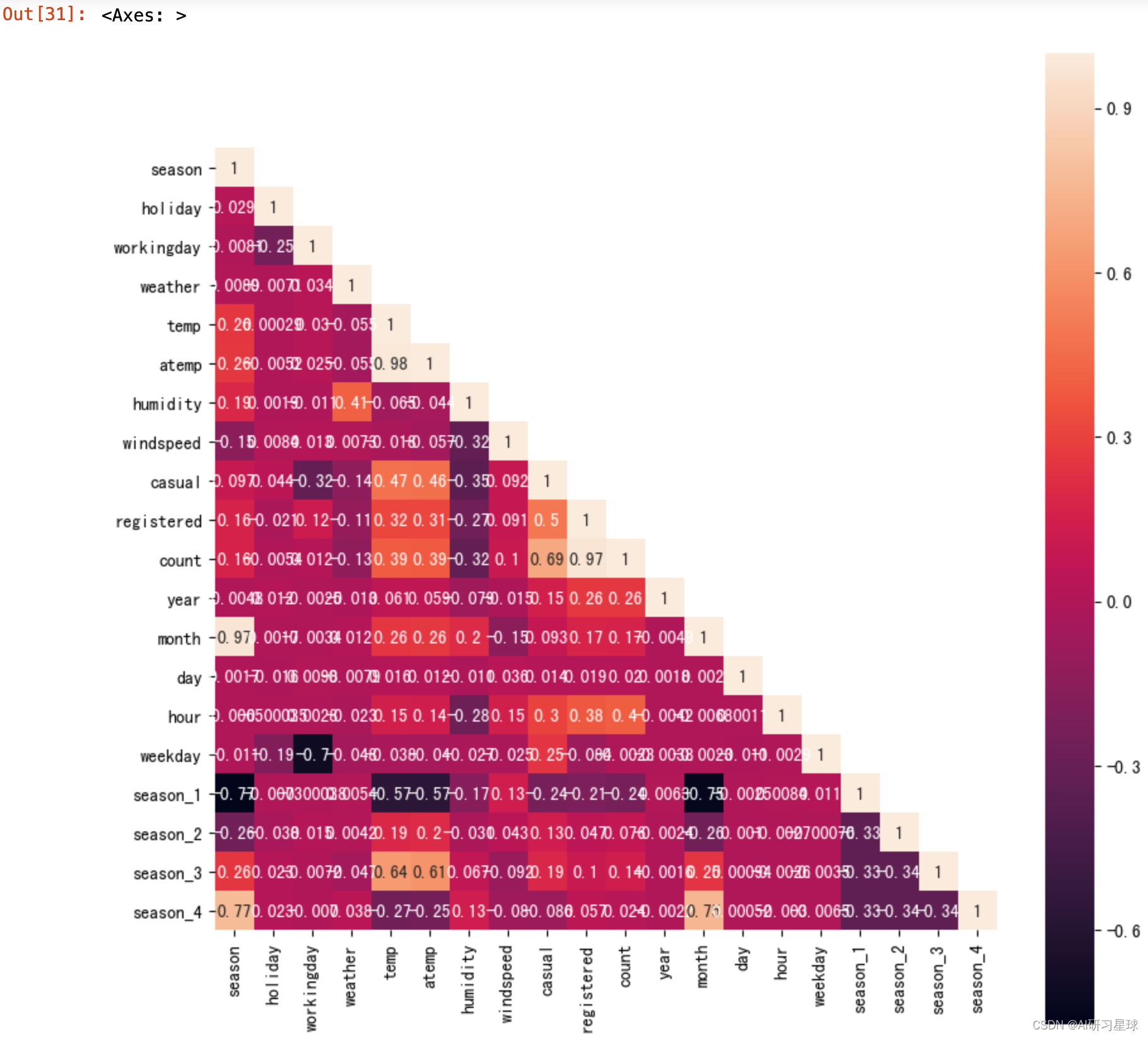
d. 查看用户总数与其他变量之间的相关性大小情况
import seaborn as sns
fig = plt.figure(figsize=(10,10))
ax2 = fig.add_subplot(1,1,1)
df = pd.concat([bike_data.iloc[:,1:]],axis=1)
corrdf = df.corr()
mask = np.array(corrdf)
mask[np.tril_indices_from(mask)] = False
sns.heatmap(corrdf,mask=mask,annot=True,square=True,ax=ax2)
6. 数据分析总结
- 共享单车由注册用户与非注册用户构成,而主要群体以注册用户为主。
- 共享单车的用户总数主要受摄氏度、体感温度、湿度、时刻影响比较明显。
- 根据数据分析提出几个建议
- 用户总数随时间在持续上升,可以增加共享单车的投放数量以满足业务需求;
- 用户总数在夏季、秋季、冬季较多,而在春季较少,可以选择在春季大批量回收车辆进行维修保养;
- 用户总数在工作日的上下班时段达到高峰期,因此在此时间段前进行车辆调度集中投放在地铁口、公交站台、小区出口等附近以供人们方便使用,提高用户量;而在假期,则在白天时刻集中投放在各小区出口、地铁口、景点等附近以供人们方便使用,用以提供用户量;
- 用户总数在温度达到20-25摄氏度之间达到高峰期,因为温度较舒服,人们喜欢骑单车出行,因此在这种天气时增大投放量。
关注公众号:『AI学习星球』
添加微信小助手 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或CSDN滴滴我
















 6381
6381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









