







 本文分析了DCGAN训练中Dloss趋近于0而Gloss上升的原因,涉及训练不稳定、超参数设置、网络结构、数据质量等因素,并提供了调整方法。同时,针对生成的模糊图像,给出了增加训练次数、调整学习率、网络结构改进等提升图像质量的建议。
本文分析了DCGAN训练中Dloss趋近于0而Gloss上升的原因,涉及训练不稳定、超参数设置、网络结构、数据质量等因素,并提供了调整方法。同时,针对生成的模糊图像,给出了增加训练次数、调整学习率、网络结构改进等提升图像质量的建议。
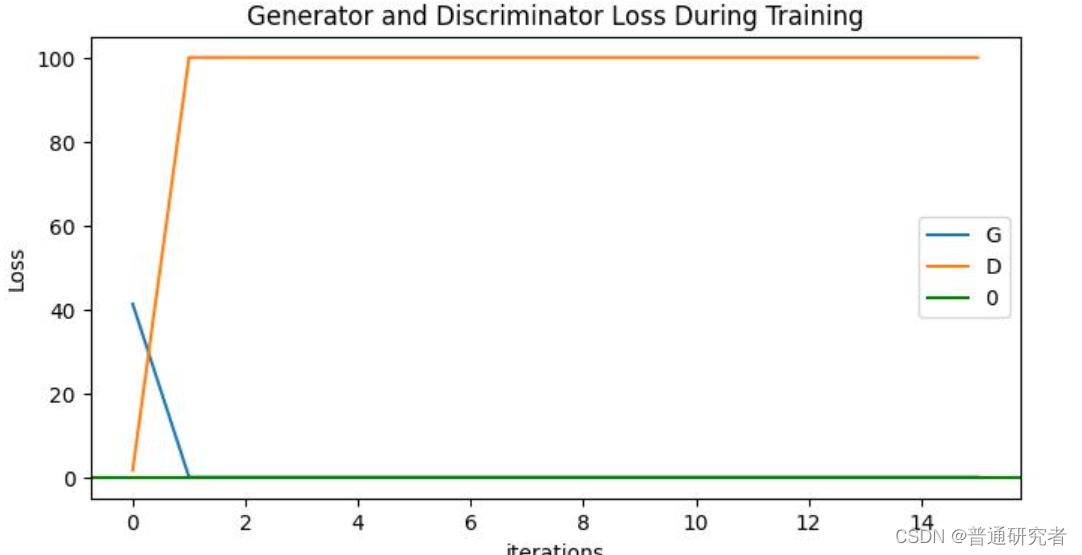
我最近在**使用DCGAN训练个人的数据集**时,出现了D loss 下降趋于0,但是G loss 却不停上升。我总结了一下几点原因:
生成器损失为1或者大于1通常表明生成器的训练可能存在问题,这可能是由于训练不稳定、超参数设置不当或网络结构问题引起的。以下是一些常见的原因和解决方法:
-
训练不稳定: GANs(生成对抗网络)的训练是复杂且容易不稳定的。生成器和判别器之间的博弈可能导致训练发散。你可以尝试减小学习率或使用其他稳定 GAN 训练技巧,如渐进性增长、标签平滑、正则化等。
-
超参数设置: 学习率、批量大小、激活函数等超参数的选择可能会影响训练的稳定性。逐步调整这些超参数,观察它们对训练的影响,并选择效果较好的值。
-
网络结构问题: 生成器和判别器的网络结构可能需要调整。尝试增加或减少网络层数、神经元数量,或者更换激活函数,以找到更稳定的训练。
-
训练数据问题: 如果训练数据不足或者数据质量不高,生成器可能难以学到真实数据的分布。确保你的数据集质量良好,考虑使用数据增强等技术。
-
权重初始化: 确保网络权重的初始化是合适的,避免使用过大或过小的初始权重。常见的初始化方法包括 Xavier/Glorot 初始化。
要更详细地调查生成器损失为1的问题,可以观察生成器生成的样本,检查判别器的输出是否合理,以及尝试不同的调整方法来提高训练的稳定性。
此外,网络训练了1000次,但是产生的fake image 很模糊,我查阅了资料总结一下几点原因:
如果生成的图像在训练1000次后仍然模糊,这可能是由于多种原因导致的。以下是一些建议,可能有助于改善生成图像的质量:

-
增加训练次数: 在某些情况下,GANs 需要更多的训练时间才能产生高质量的图像。尝试增加训练迭代次数,观察生成图像的变化。
-
调整学习率: 适当的学习率对 GAN 训练非常重要。如果学习率太大,可能导致训练不稳定;如果学习率太小,可能训练进展缓慢。尝试调整学习率并观察效果。
-
使用更复杂的网络结构: 生成器和判别器的网络结构可能不够复杂,无法捕捉数据的复杂分布。考虑增加网络的层数和/或神经元数量。
-
使用正则化技术: GANs 可能会过拟合训练数据,导致生成的图像缺乏多样性。尝试使用 dropout、批量归一化等正则化技术来减轻过拟合。
-
改进判别器: 优化判别器的能力,使其能够更好地区分真实和生成的图像。这有助于生成器更好地学习生成逼真的图像。
-
数据增强: 考虑在训练数据上应用数据增强技术,如随机旋转、平移、缩放等,以增加数据的多样性。
-
调整噪声向量: GAN 的生成器输入通常是一个随机噪声向量。尝试调整噪声向量的大小和分布,观察生成图像的效果。
-
评估损失函数: 观察生成器和判别器的损失函数,确保它们在训练过程中适当地降低。如果损失函数仍然很高,可能需要重新审查网络架构和超参数设置。
记住,GAN 的训练可能需要一些调试和优化。尝试不同的方法,并根据生成图像的质量进行评估和调整。


















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











