






1. Introduction
提出LayoutLM来联合建模扫描文档图像中文本和布局信息之间的交互。此外,在fine-tune阶段利用图像特征将单词的视觉信息整合到LayoutLM中。

2.1 The LayoutLM Model
在模型输入层面,LayoutLM在Bert采用的文本与位置特征的基础上,新增了两个输入embedding:
(1)2D position embedding (x0,y0,x1,y1)也就是文档版面特征,用来捕获文档中token之间的关系,以表单理解为例,给定表单中的一个键(例如,“Passport ID:”),其对应的值更可能位于其右侧或下方,而不是左侧或上方。在语言表示中嵌入二维位置特征将更好地将布局信息与语义表示对齐。
为了表示扫描文档图像中元素的空间位置,考虑文档页作为左上角原点的坐标系。在此设置中,可以通过(x0,y0,x1,y1)精确定义边界框,其中(x0,y0)对应于边界框中左上角的位置,(x1,y1)表示右下角的位置。
添加了四个位置嵌入层两张嵌入表(其中表示相同维度的嵌入层共享相同的embedding table)。在embedding table X中查找x0和x1的位置嵌入,在table Y中查找y0和y1。
(2)image Embedding,采用的是Faster-RCNN的ROI特征,捕获一些外观特征,对于文档级视觉特征,整个图像可以表示文档布局,这是文档图像分类的一个基本特征。对于单词级的视觉特征,粗体、下划线和斜体等样式也是序列标记任务的重要提示。
通过OCR结果中每个单词的边界框,我们将图像分割成几个部分,它们与单词一一对应,由Faster R-CNN生成image的部分ROI区域特征作为token的image embeddings;对于[CLS] token,还是使用Faster R-CNN,扫描整个文档图像作为ROI,生成embedding,以利于需要[CLS]令牌表示的下游任务。
2.2 Pre-training LayoutLM
Task-1. Masked Visual-Language Model (MVLM),掩码视觉语言模型损失 。在预训练过程中,随机屏蔽了一些输入tokens,但保留了相应的2-D position embedding,然后训练模型预测给定上下文的屏蔽token。
通过这种方式,LayoutLM模型不仅能理解语言语境,还能利用相应的二维位置信息,从而弥合视觉和语言模式之间的差距
Task-2. Multi-label Document Classification (MDC) loss,由于IIT-CDIP测试集合包含每个文档图像的多个标签,所以要MDC loss进行多任务学习。
由于MDC loss需要每个文档图像的标签,而对于较大的数据集,一些图像可能不存在这些标签,在pre-train期间,它是可选的,但可能不会用于较大规模的pre-train。
2.3 Fine-tuning LayoutLM
预训练的LayoutLM模型在三个文档图像理解任务上进行了微调,包括表单理解任务、收据理解任务以及文档图像分类任务。对于表单和收据理解任务,LayoutLM预测每个标记的{B,I,E,S,O}标记,并使用序列标签检测数据集中的每种类型的实体。对于文档图像分类任务,LayoutLM使用[CLS]标记的表示来预测类。
3.1 Pre-training Dataset
在训练数据层面,LayoutM在IIT-CDIP Test Collection 1.02数据集上进行预训练,该数据集包含信件,备忘录,电子邮件,表格,票据等各种各样的文档类型。此外,每个文档都有相应的文本和元数据存储在XML文件中。文本是对文档图像应用OCR生成的识别内容和在文档中相应的位置,通过开源OCR引擎Tesseract6。元数据描述文档的属性,例如唯一标识和文档标签
3.2 Fine-tuning Dataset
RVL-CDIP数据集,给后面接一个全连接,做softmax判断文档的类别就行。有16类类型。
FUNSD和SROIE的任务都是NER任务,做法对于每个向量之后接全连接和softmax来预测label
4. RESULT
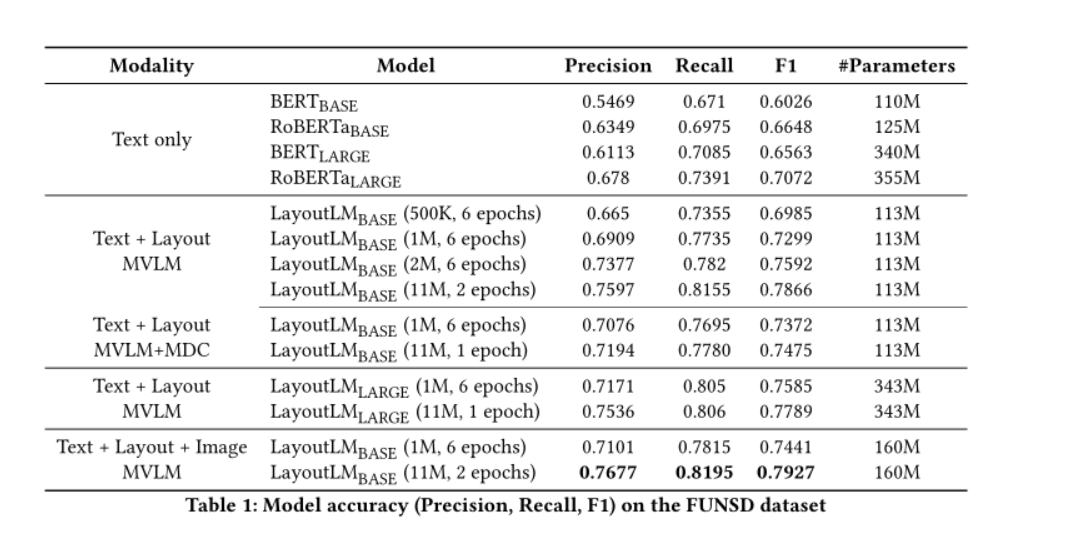
对于表格理解,在FUNSD数据集上验证的结果,LayoutLM在相似大小参数数量上F1达到0.7866远高于BERT 和 RoBERTa,此外再加入MDCloss,在1M的数据上会给F1带来提升,当同时使用文本、布局和图像信息时,LayoutLM模型达到了0.7927的最佳性能
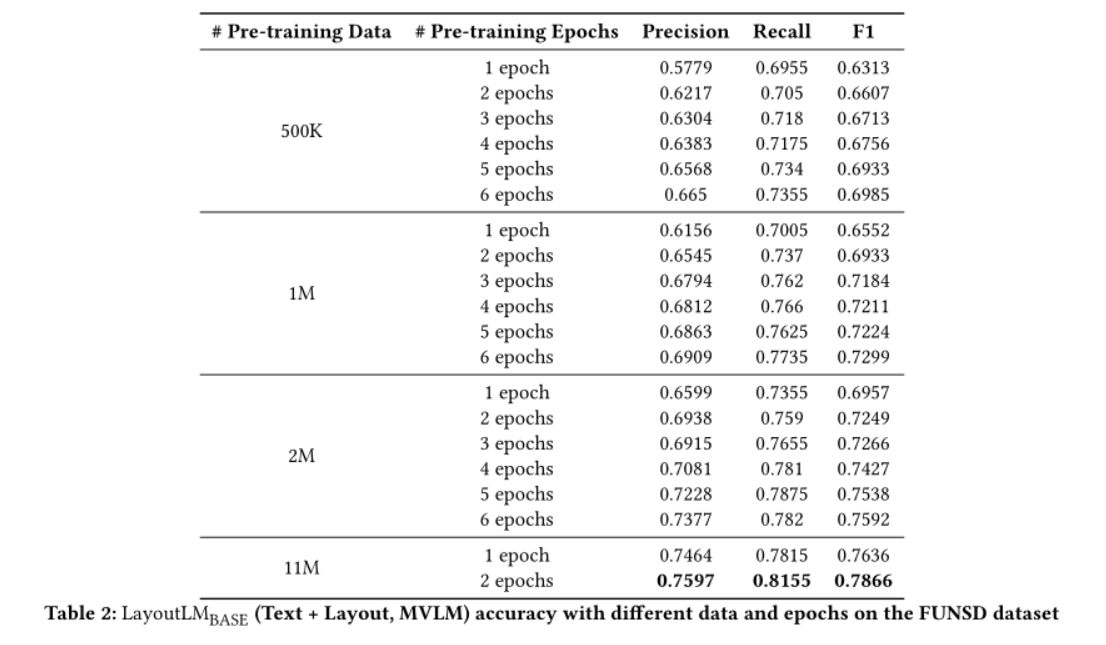
由于FUNSD数据集仅包含149张用于fine-tune的图像,结果证实,文本和布局的预训练(更大数量的预训练数据和更多的训练epoch)对于理解扫描文档是有效的,尤其是在资源设置较低的情况下。
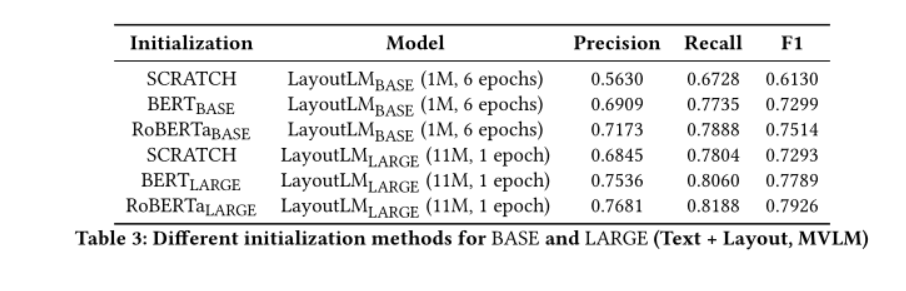
比较不同的初始化方法,pre-train将以RoBERTa-Large作为初始设置
使用SROIE数据集评估收据理解任务,同样优于Baseline
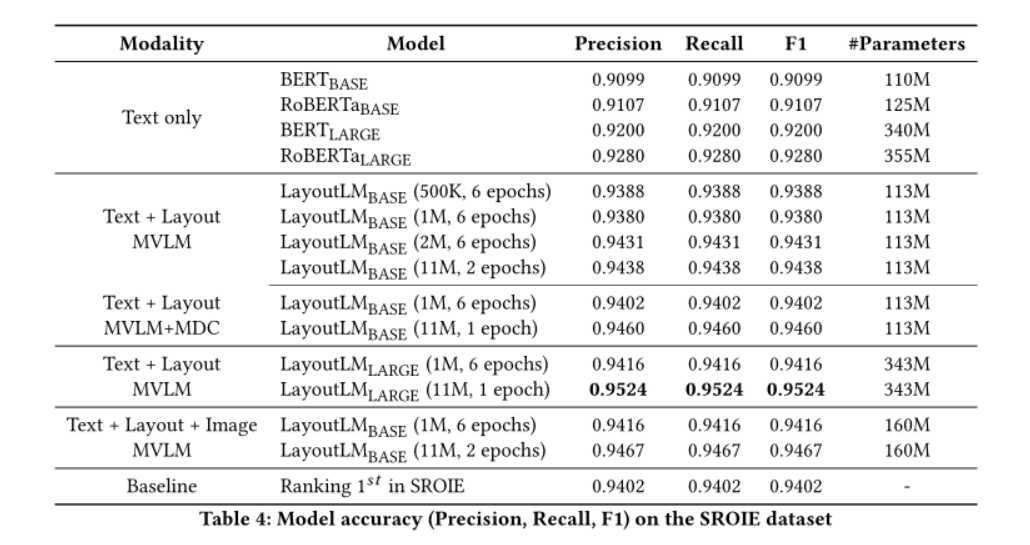
文档图像分类,基于Bert/RoBERT的文本模型效果不如基于图像的方法,和VGG差不多的结果。结果表明,即使没有Image信息,LayoutLM的功能仍然优于基于图像的方法的单一模型。在集成了Image embedding之后LayoutLM的准确率达到94.42%
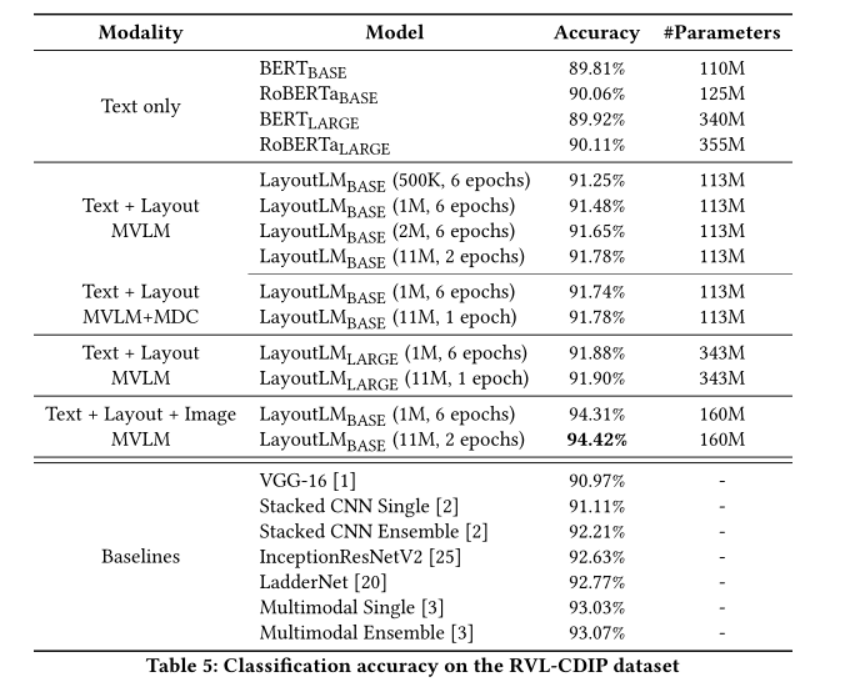
据观察,模型在“电子邮件”中表现最好类别,而在“表单”类别中表现最差















 1233
1233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









