







Word2vec
Word2vec是谷歌团队在2013年开源推出的一个专门用于获取词向量的工具包,其核心算法是对NNLM运算量最大的那部分进行了效率上的改进,让我们来一探究竟。
word2vec有两种模型–CBOW和Skip-gram,这两个模型目的都是通过训练语言模型任务,得到词向量。CBOW的语言模型任务是给定上下文预测当前词,Skip-gram的语言模型任务是根据当前词预测其上下文。
Word2vec还提供了两种框架–Hierarchical Softmax和Negative-Sampling,所以word2vec有四种实现方式,下面将对其原理进行介绍。
CBOW
CBOW的核心思想就是利用给定上下文,预测当前词,其结构表示为

基于神经网络的语言模型的目标函数通常是对数似然函数,这里CBOW的目标函数应该就是
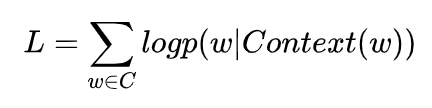
其中是单词的上下文,是词典。所以我们关注的重点应该就是的构造上,NNLM和Word2vec的本质区别也是在于该条件概率函数的构造方式不同。
Skip-gram
Skip-gram的核心思想就是利用给定的当前词
w
t
,
预
测
上
下
文
w
t
−
2
,
w
t
−
1
,
w
t
+
1
,
w
t
+
2
{w}_{t},预测上下文{w}_{t-2},{w}_{t-1},{w}_{t+1},{w}_{t+2}
wt,预测上下文wt−2,wt−1,wt+1,wt+2,其结构表示为

神经网络的语言模型的目标函数通常是对数似然函数,这里Skip-gram的目标函数就是
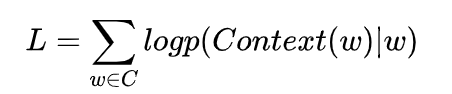
其中
C
o
n
t
e
x
t
(
w
)
Context(w)
Context(w)是单词
w
w
w的上下文,
C
C
C是词典。关注的重点应该就是
P
(
C
o
n
t
e
x
t
(
w
∣
w
)
)
P(Context(w|w))
P(Context(w∣w))的构造上。
代码
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import torch.utils.data as Data
dtype = torch.FloatTensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
"""文本预处理"""
sentences = ["jack like dog", "jack like cat", "jack like animal",
"dog cat animal", "banana apple cat dog like", "dog fish milk like",
"dog cat animal like", "jack like apple", "apple like", "jack like banana",
"apple banana jack movie book music like", "cat dog hate", "cat dog like"]
word_sequence = " ".join(sentences).split() # ['jack', 'like', 'dog', 'jack', 'like', 'cat', 'animal',...]
vocab = list(set(word_sequence)) # build words vocabulary
word2idx = {w: i for i, w in enumerate(vocab)} # {'jack':0, 'like':1,...}
"""模型相关参数"""
# Word2Vec Parameters
batch_size = 8
embedding_size = 2 # 2 dim vector represent one word
C = 2 # window size
voc_size = len(vocab)
"""数据预处理"""
# 1.
skip_grams = []
for idx in range(C, len(word_sequence) - C):
center = word2idx[word_sequence[idx]] # center word
context_idx = list(range(idx - C, idx)) + list(range(idx + 1, idx + C + 1)) # context word idx
context = [word2idx[word_sequence[i]] for i in context_idx]
for w in context:
skip_grams.append([center, w])
# 2.
def make_data(skip_grams):
input_data = []
output_data = []
for i in range(len(skip_grams)):
input_data.append(np.eye(voc_size)[skip_grams[i][0]])
output_data.append(skip_grams[i][1])
return input_data, output_data
# 3.
input_data, output_data = make_data(skip_grams)
input_data, output_data = torch.Tensor(input_data), torch.LongTensor(output_data)
dataset = Data.TensorDataset(input_data, output_data)
loader = Data.DataLoader(dataset, batch_size, True)
"""构建模型"""
# Model
class Word2Vec(nn.Module):
def __init__(self):
super(Word2Vec, self).__init__()
# W and V is not Traspose relationship
self.W = nn.Parameter(torch.randn(voc_size, embedding_size).type(dtype))
self.V = nn.Parameter(torch.randn(embedding_size, voc_size).type(dtype))
def forward(self, X):
# X : [batch_size, voc_size] one-hot
# torch.mm only for 2 dim matrix, but torch.matmul can use to any dim
hidden_layer = torch.matmul(X, self.W) # hidden_layer : [batch_size, embedding_size]
output_layer = torch.matmul(hidden_layer, self.V) # output_layer : [batch_size, voc_size]
return output_layer
model = Word2Vec().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
"""训练"""
# Training
for epoch in range(2000):
for i, (batch_x, batch_y) in enumerate(loader):
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
if (epoch + 1) % 1000 == 0:
print(epoch + 1, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
for i, label in enumerate(vocab):
W, WT = model.parameters()
x,y = float(W[i][0]), float(W[i][1])
plt.scatter(x, y)
plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()
欢迎关注公众号:

















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











