








Paper:https://arxiv.org/pdf/1706.02216
- GCN虽然能提取图中顶点的embedding,但是存在一些问题:
- GCN的基本思想: 把一个节点在图中的高纬度邻接信息降维到一个低维的向量表示。
- GCN的优点: 可以捕捉graph的全局信息,从而很好地表示node的特征。
- GCN的缺点: Transductive learning的方式,需要把所有节点都参与训练才能得到node embedding,无法快速得到新node的embedding。
2017 NIPS | Inductive Representation Learning on Large Graphs
摘要
大图中节点的低维嵌入已被证明在各种预测任务中非常有用,从内容推荐到蛋白质功能识别。然而,大多数现有的方法要求图中的所有节点都在嵌入训练期间出现。前面的这些方法具有固有的转导性,不能自然地推广到看不见的节点。因此,作者提出了GraphSAGE,这是一个通用的归纳框架,它利用节点特征信息(例如,文本属性)来高效地为以前不可见的数据生成节点嵌入。学习了一个函数,通过从节点的局部邻域采样和聚合特征来生成嵌入,而不是为每个节点训练单独的嵌入。该算法在三个归纳节点分类基准上优于强基线:基于citation和Reddit post数据对进化信息图中的不可见节点进行分类,并表明我们的算法可以推广到使用蛋白质-蛋白质相互作用的多图数据集的完全不可见图。
模型
因此本文的核心就是graphSage算法,sage分为两个步骤:sample(采样)和Aggregate(聚合)。采样是为了方便批处理以及降低复杂度,为了方便批处理,在给定一批要更新的节点后,要先取出
K
K
K阶邻居节点集合,为了降低复杂度,可以只采样固定数量的邻居节点而非所有。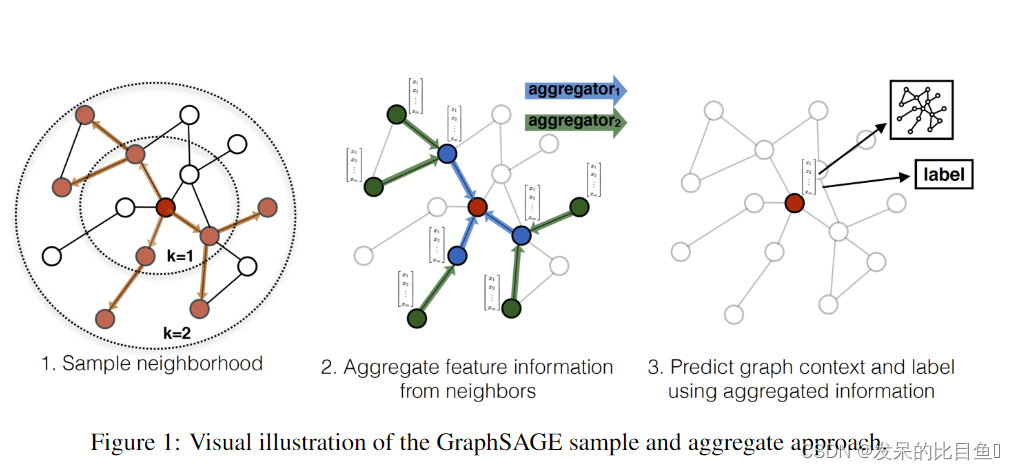
算法流程


其中, K K K是GraphSAGE的层数,当前节点 v v v在 k k k层的embedding由两部分组成,一部分是通过聚合节点 v v v在 k − 1 k-1 k−1层相连的邻居节点的embedding, 得到节点 v v v在 k k k层的邻居聚合特征;另一部分,是节点 v v v在第 k − 1 k-1 k−1层的embedding。考虑到算法的计算复杂度,一般会采取固定大小的邻居,而不是使用完整的邻域集。
参数学习
主要是通过随机梯度下降法来学习权重W和聚合函数的参数,目标是“相邻近的节点具有相似的表示形式,同时强制要求不同节点的表示形式要有区分度”
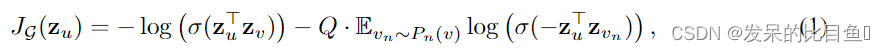
聚合函数
- Mean Aggregator
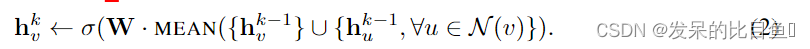
- Pooling Aggregator
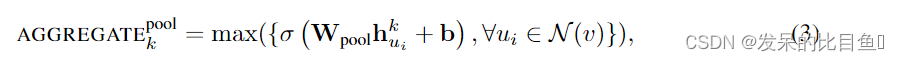
- LSTM Aggregator
LSTM具有较大的表达能力,但是LSTM本身不是对称的(即,它们不是排列不变的),因为它们以顺序的方式处理输入。
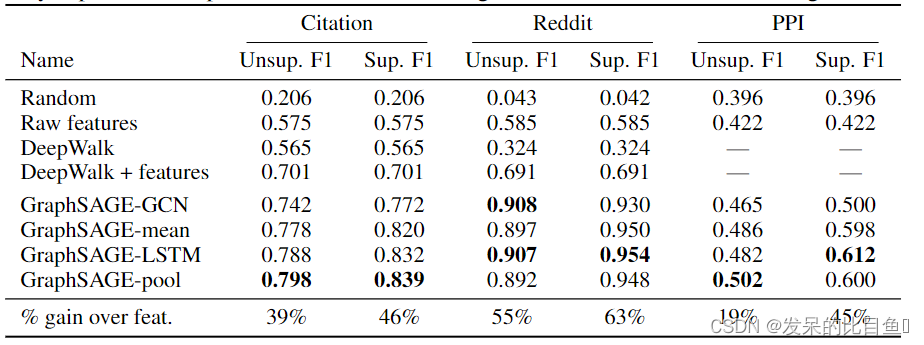
实验
实验中,GraphSAGE被应用在了三个数据集上(Citation, Reddit, PPI),并检验了不同A函数的效果。实验结果证明这个方法是有效的,且基于LSTM和Pooling的A函数表现得优于平均函数。
参考
https://zhuanlan.zhihu.com/p/430566850
https://zhuanlan.zhihu.com/p/386271125
















 1156
1156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











