







2022-arxiv-P-Tuning v2 Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks

P-Tuning v2: 快速调优可以与跨规模和任务的普遍微调相媲美
提示微调,只用一个冻结的语言模型来微调连续的提示,大大减少了训练时每个任务的存储和内存使用。然而,在NLU的背景下,先前的工作显示,提示微调对于正常大小的预训练模型来说表现并不理想。而现有的提示微调方法不能处理困难的序列标注任务,表明缺乏普遍性。因此作者经实验发现,适当优化的提示微调可以在广泛的模型规模和NLU任务中普遍有效。它与微调的性能相匹配,而只有0.1%-3%的微调参数。该方法P-Tuning v2并不是一个新的方法,而是前缀微调(Li and Liang, 2021)的一个优化版本,为NLU优化和微调。给定P-Tuning v2的普遍性和简单性,是未来研究的一个强有力的基线。
P-Tuning v2结构
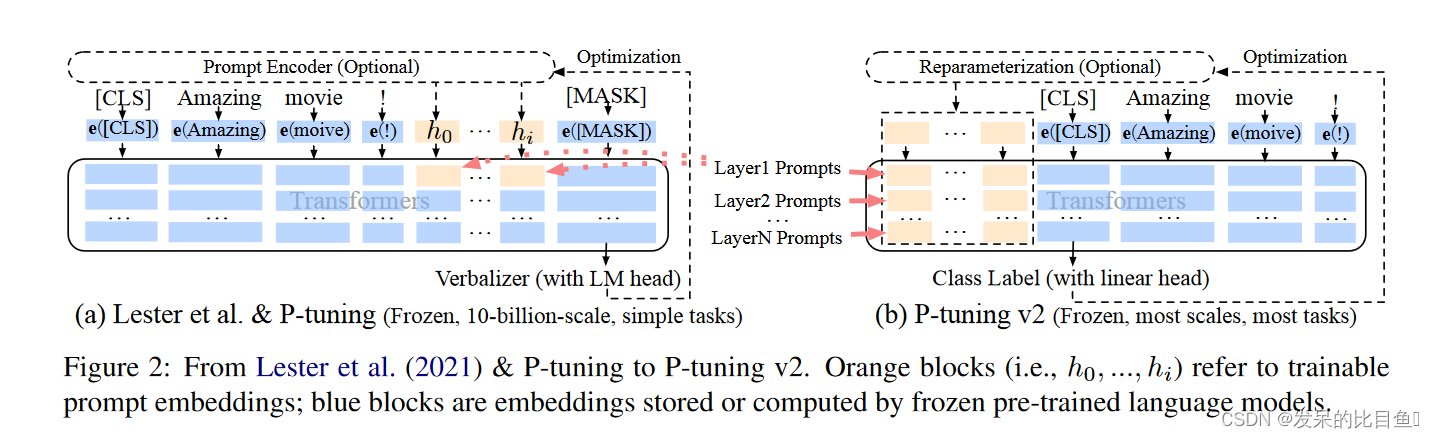
上图中,左侧为P-Tuning,右侧为P-Tuning v2。P-Tuning v2与P-Tuning的不同之处在于:将只在第一层插入continuous prompt修改为在许多层都插入continuous prompt,层与层之间的continuous prompt是相互独立的。
P-Tuning v2与Prefix-Tuning的改进之处在于,除了输入的embedding外,其它的Transformer层也加了前置的prompt。
做出这种改进的原因:
(1)先前的工作显示,Prompt tuning在normal-sized的预训练模型上效果一般。
(2)现有的Prompt tuning方法在较难的文本序列问题上效果不好。
P-Tuning v2将Prefix-tuning应用于在NLU任务,如下图所示:
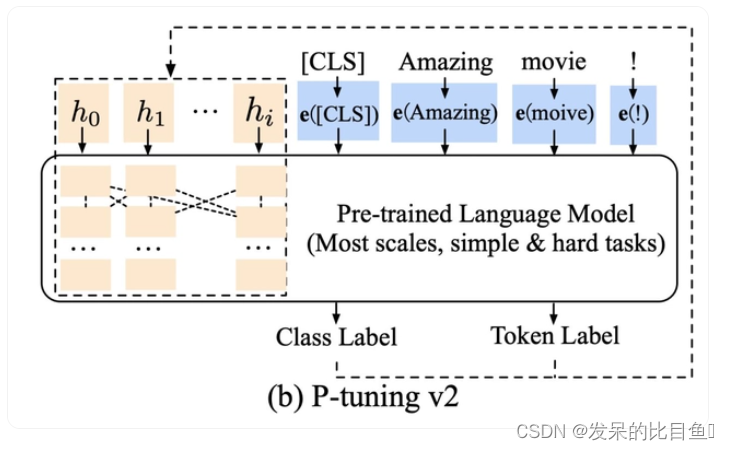
P-tuning v2在实际上就是Prefix-tuning,在Prefix部分,每一层transformer的embedding输入需要被tuned。而P-tuning v1只有transformer第一层的embedding输入需要被tuned。
假设Prefix部分由50个token组成,则P-tuning v2共有 50X12=600个参数需要tuned。
在Prefix部分,每一层transformer的输入不是从上一层输出,而是随机初始化的embedding(需要tuned)作为输入。
参考
https://baijiahao.baidu.com/s?id=1714301524615351467&wfr=spider&for=pc

















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











