




- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
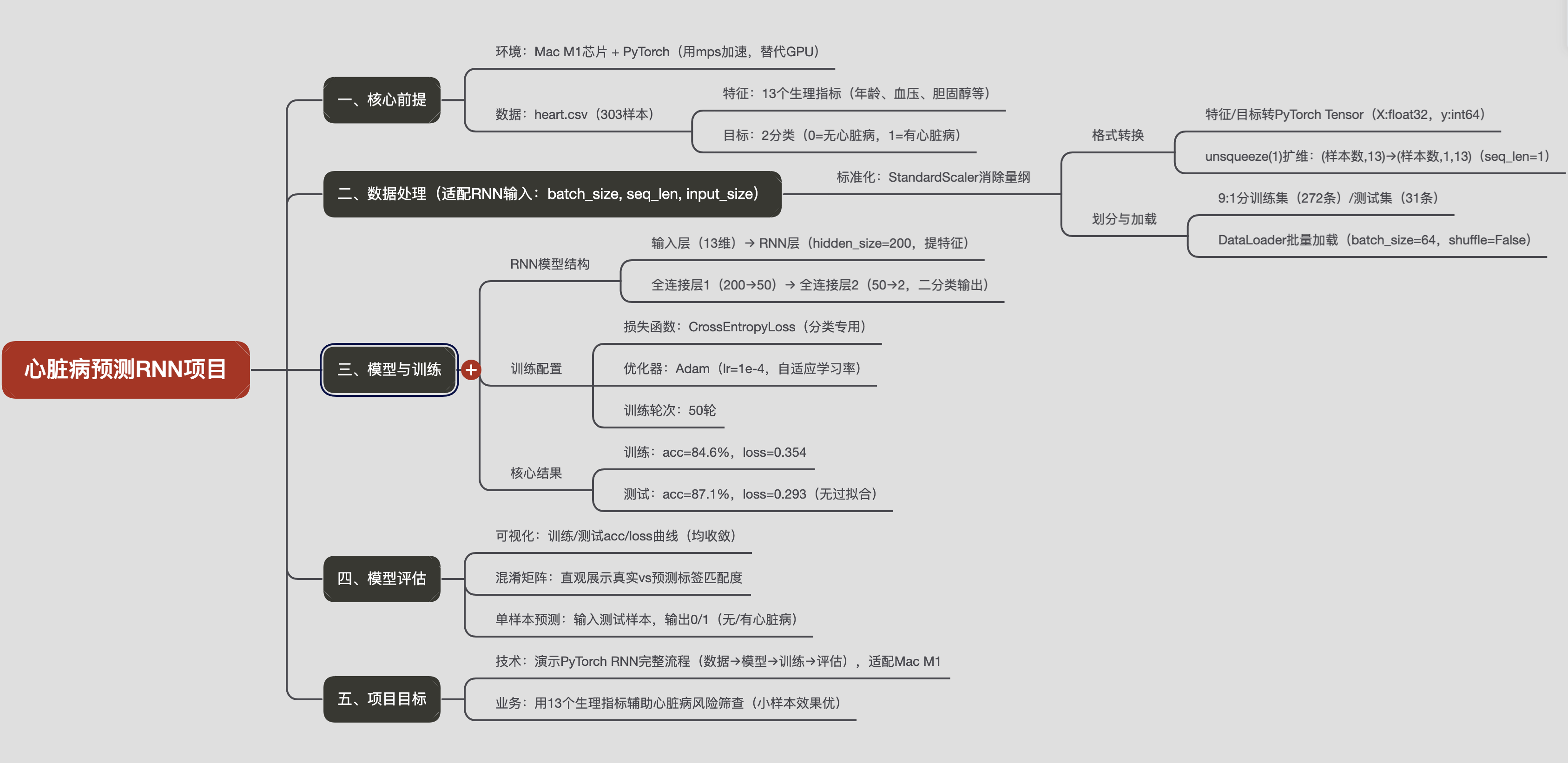
该项目是 基于 PyTorch 构建 RNN 模型的心脏病风险二分类预测完整项目流程,以heart.csv数据集为核心,从环境准备、数据处理到模型训练、评估形成闭环,适配 Mac M1 芯片环境,目标是通过 13 个生理特征(如年龄、血压、胆固醇等)预测是否患心脏病(目标变量 0 = 无心脏病,1 = 有心脏病)
RNN基础知识可看我之前文章:深度学习系列 | RNN循环神经网络-CSDN博客
一、前期准备工作
1.设置硬件设备
我的电脑是mac-m1芯片, pytorch不知道怎么安装的可以参考我之前博客mac配置Pytorch环境-CSDN博客
import torch
#设置GPU训练
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
devicedevice(type='mps')2.导入数据
import pandas as pd
df = pd.read_csv("data/heart.csv")
df| age | sex | cp | trestbps | chol | fbs | restecg | thalach | exang | oldpeak | slope | ca | thal | target | |
| 0 | 63 | 1 | 3 | 145 | 233 | 1 | 0 | 150 | 0 | 2.3 | 0 | 0 | 1 | 1 |
| 1 | 37 | 1 | 2 | 130 | 250 | 0 | 1 | 187 | 0 | 3.5 | 0 | 0 | 2 | 1 |
| 2 | 41 | 0 | 1 | 130 | 204 | 0 | 0 | 172 | 0 | 1.4 | 2 | 0 | 2 | 1 |
| 3 | 56 | 1 | 1 | 120 | 236 | 0 | 1 | 178 | 0 | 0.8 | 2 | 0 | 2 | 1 |
| 4 | 57 | 0 | 0 | 120 | 354 | 0 | 1 | 163 | 1 | 0.6 | 2 | 0 | 2 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 298 | 57 | 0 | 0 | 140 | 241 | 0 | 1 | 123 | 1 | 0.2 | 1 | 0 | 3 | 0 |
| 299 | 45 | 1 | 3 | 110 | 264 | 0 | 1 | 132 | 0 | 1.2 | 1 | 0 | 3 | 0 |
| 300 | 68 | 1 | 0 | 144 | 193 | 1 | 1 | 141 | 0 | 3.4 | 1 | 2 | 3 | 0 |
| 301 | 57 | 1 | 0 | 130 | 131 | 0 | 1 | 115 | 1 | 1.2 | 1 | 1 | 3 | 0 |
| 302 | 57 | 0 | 1 | 130 | 236 | 0 | 0 | 174 | 0 | 0.0 | 1 | 1 | 2 | 0 |
303 rows × 14 columns
二、构建数据集
1.标准化
从数据框df中提取特征和目标变量,然后对特征数据进行标准化处理,为后续的机器学习模型训练做准备
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
X = df.iloc[: , :-1]
y = df.iloc[: , -1]
sc = StandardScaler()
X = sc.fit_transform(X)
print(X)[[ 0.9521966 0.68100522 1.97312292 ... -2.27457861 -0.71442887
-2.14887271]
[-1.91531289 0.68100522 1.00257707 ... -2.27457861 -0.71442887
-0.51292188]
[-1.47415758 -1.46841752 0.03203122 ... 0.97635214 -0.71442887
-0.51292188]
...
[ 1.50364073 0.68100522 -0.93851463 ... -0.64911323 1.24459328
1.12302895]
[ 0.29046364 0.68100522 -0.93851463 ... -0.64911323 0.26508221
1.12302895]
[ 0.29046364 -1.46841752 0.03203122 ... -0.64911323 0.26508221
-0.51292188]]2.划分数据集
Tensor可以说是PyTorch里最重要的概念,PyTorch把对数据的存储和操作都封装在Tensor里。PyTorch里的模型训练的输入输出数据,模型的参数,都是用Tensor来表示的。Tensor在操作方面和NumPy的ndarray是非常类似的。不同的是Tensor还实现了像GPU计算加速,自动求导等PyTorch的核心功能unsqueeze是 PyTorch 中的一个函数,用于在指定位置插入一个大小为 1 的维度;X_train原本是形状为(batch_size, feature_size)的二维张量,执行X_train = X_train.unsqueeze(1)后,其形状会变为(batch_size, 1, feature_size)
import numpy as np
#将数据转换为PyTorch中的张量(Tensor)格式
X= torch.tensor(np.array(X), dtype = torch.float32)
y= torch.tensor(np.array(y), dtype = torch.int64)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state= 1)
#维度扩增使其符合RNN模型可接受shape
#该函数用于在指定位置插入一个大小为 1 的维度
X_train = X_train.unsqueeze(1)
X_test = X_test.unsqueeze(1)
X_train.shape, y_train.shape(torch.Size([272, 1, 13]), torch.Size([272]))3.构建数据加载器
TensorDataset:是 PyTorch 中用于将多个张量组合成一个数据集的类DataLoader:是 PyTorch 中用于加载数据的类,它可以将数据集(如TensorDataset创建的数据集)封装成一个可迭代对象,方便在训练模型时按批次获取数据dataset参数是必需的,用于指定要加载的数据集;batch_size参数用于设置每个批次的数据量,代码中设置为 64,即每个批次包含 64 个样本;shuffle参数是一个布尔值,用于指定是否在每个 epoch 开始时打乱数据,False表示不打乱数据
from torch.utils.data import TensorDataset, DataLoader
# TensorDataset 将多个张量包装成一个数据集
# X_train(训练特征数据)和y_train(训练标签数据)包装成一个数据集对象
train_dl = DataLoader(TensorDataset(X_train, y_train),
batch_size=64,
shuffle = False)
test_dl = DataLoader(TensorDataset(X_test, y_test),
batch_size=64,
shuffle = False)
print(train_dl)<torch.utils.data.dataloader.DataLoader object at 0x30ddec200>三、模型训练
1.构建模型
super(model_rnn, self).__init__():初始化父类nn.Module,确保模型能正确管理参数(如权重、偏置)。nn.RNN(循环神经网络层):input_size=13:每个时间步的输入特征维度为 13(例如,13 个传感器的实时数据)。hidden_size=200:RNN 的隐藏状态维度为 200,决定了模型对序列信息的学习能力(维度越大,能力越强,但计算成本越高)。num_layers=1:RNN 的层数为 1(多层 RNN 可通过堆叠提升特征提取能力,如num_layers=2表示两层 RNN)。batch_first=True:指定输入数据的格式为(batch_size, seq_len, input_size),即第一维是批量大小,第二维是序列长度,第三维是特征维度(符合常规数据组织习惯)
- 全连接层(
nn.Linear):- 用于将 RNN 的输出映射到最终任务的输出维度。这里通过两层线性变换:
fc0:将 RNN 输出的 200 维特征压缩到 50 维。fc1:将 50 维特征映射到 2 维(通常对应二分类任务的两个类别概率)
- 用于将 RNN 的输出映射到最终任务的输出维度。这里通过两层线性变换:
forward方法:是模型的核心,定义了输入数据x如何通过各层计算得到输出
from torch import nn # 导入PyTorch的神经网络模块(核心工具)
'''
1. 序列数据通过 RNN 层提取时序特征;
2. 取最后一个时间步的特征作为序列总结;
3. 通过全连接层将特征映射到分类结果
'''
class model_rnn(nn.Module): # 继承nn.Module(PyTorch所有神经网络的基类)
def __init__(self): # 初始化方法,定义模型的层
super(model_rnn, self).__init__()
self.rnn0=nn.RNN(input_size = 13, # 输入特征维度:每个时间步的输入是13维向量
hidden_size=200, # 隐藏层大小:RNN的隐藏状态是200维向量
num_layers = 1, # RNN层数:1层(简单RNN,可堆叠多层提升能力)
batch_first=True) # 输入数据格式:(batch_size, seq_len, input_size)
#全连接层(线性层)
self.fc0 = nn.Linear(200, 50) # 从200维映射到50维
self.fc1 = nn.Linear(50, 2) # 从50维映射到2维
def forward(self, x): # 定义数据如何通过模型(前向传播逻辑)
out, _ = self.rnn0(x) # 输入x传入RNN层,得到输出out和隐藏状态(用_忽略隐藏状态)
out = out[:, -1, :] # 取每个序列的最后一个时间步的输出(用于序列分类)
out = self.fc0(out) # 传入第一个全连接层,从200维→50维
out = self.fc1(out) # 传入第二个全连接层,从50维→2维(最终输出)
return out
model = model_rnn().to(device) # 创建模型实例,并移动到指定设备(CPU或GPU)
modelmodel_rnn(
(rnn0): RNN(13, 200, batch_first=True)
(fc0): Linear(in_features=200, out_features=50, bias=True)
(fc1): Linear(in_features=50, out_features=2, bias=True)
)#模型输出数据集格式
'''
首先,torch.rand(30, 1, 13)会生成一个形状为(30, 1, 13)的张量,其中30是批量大小,1是序列长度,13是每个时间步的输入特征维度。.to(device)会将该张量移动到指定的设备(CPU 或 GPU)上。
然后,将该张量输入到model_rnn模型中。由于model_rnn类中batch_first=True。根据nn.RNN的输出特性,其输出形状为(batch_size, sequence_length, hidden_size)。所以经过self.rnn0层后,输出形状为(30, 1, 200),其中200是hidden_size。
接着,取每个序列的最后一个时间步的输出out[:, -1, :],此时形状变为(30, 200)。
最后,经过第一个全连接层self.fc0后,形状变为(30, 50),再经过第二个全连接层self.fc1后,形状变为(30, 2)。因此,最终模型输出的形状为torch.Size([30, 2])
'''
model(torch.rand(30,1,13).to(device)).shapetorch.Size([30, 2])2.定义训练函数
'''
按批次遍历训练数据,通过 “前向传播计算损失→反向传播求梯度→优化器更新参数” 的流程训练模型,同时统计整个训练集的平均准确率和平均损失
dataloader:数据加载器,用于按批次读取训练数据
model: 需要训练的模型(比如前面定义的model_rnn)
loss_fn: 损失函数(比如交叉熵损失nn.CrossEntropyLoss()),用于衡量模型预测值与真实标签的差距
optimizer:优化器(比如 Adam、SGD),用于根据损失的梯度更新模型参数
'''
def train(dataloader, model, loss_fn, optimizer):
size= len(dataloader.dataset) #训练集的大小
num_batches = len(dataloader) #总批次数(=总样本数÷batch_size,向上取整)
train_loss, train_acc = 0, 0 #初始化训练损失和正确率
for X, y in dataloader: #获取图片及其标签,X:输入特征,y:真实标签)
X, y = X.to(device), y.to(device) #将数据移动到指定设备(CPU/GPU,和模型保持一致)
#计算预测误差
pred = model(X) #模型对输入X的预测输出(前向传播)
loss = loss_fn(pred, y) # 计算预测值pred与真实标签y的损失(差距)
#反向传播
optimizer.zero_grad() #清空优化器中之前累积的梯度(必须!否则梯度会叠加)
loss.backward() #计算损失对模型所有参数的梯度(反向传播核心步骤)
optimizer.step() #根据梯度更新模型参数(优化器的核心作用)
#记录acc与losss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item() # 累加正确预测数
train_loss += loss.item() # 累加当前批次的损失值
train_acc /= size # 整体准确率 = 总正确数 ÷ 总样本数
train_loss/= num_batches # 平均损失 = 总损失 ÷ 总批次数
return train_acc, train_loss3.定义测试函数
'''
在测试集上评估模型的泛化能力
通过前向传播得到预测结果,计算并返回测试集的平均损失和准确率,
同时通过关闭梯度计算提高效率。它是模型训练过程中不可或缺的部分,用于判断模型是否 “学透”(而非仅记住训练数据)
'''
def test(dataloader, model, loss_fn):
size= len(dataloader.dataset) #训练集的大小
num_batches = len(dataloader) #总批次数(=总样本数÷batch_size,向上取整)
test_loss, test_acc = 0, 0 #初始化训练损失和正确率
#当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs,target = imgs.to(device), target.to(device)
#计算loss
target_pred = model(imgs) # 模型对输入imgs的预测输出(前向传播)
loss =loss_fn(target_pred, target) # 计算预测值与真实标签的损失
test_loss += loss.item() # 累加当前批次的损失值(转为Python标量)
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item() # 累加正确预测数
test_loss /= num_batches
test_acc /= size
return test_acc, test_loss4.正式训练
'''
协调训练(更新参数)和测试(评估性能)的流程;
切换模型的训练 / 评估模式,确保计算正确;
记录每轮关键指标,方便分析模型训练趋势;
打印实时训练状态,直观监控模型进展。
'''
loss_fn = nn.CrossEntropyLoss() # 定义交叉熵损失函数
learn_rate = 1e-4 # 学习率:控制参数更新的步长(1e-4 = 0.0001)
#Adam 优化器:一种自适应学习率的优化器,收敛速度快且稳定
#model.parameters():告诉优化器需要更新的是模型中的所有可学习参数(如 RNN 的权重W、偏置b,全连接层的权重等)
opt = torch.optim.Adam(model.parameters(), lr=learn_rate) #初始化Adam优化器
epochs = 50 # 总训练轮次:整个训练集会被模型“学习”50遍
# 初始化列表,用于存储每轮的训练/测试指标(方便后续可视化)
train_loss = [] # 存储每轮训练损失
train_acc = [] # 存储每轮训练准确率
test_loss = [] # 存储每轮测试损失
test_acc = [] # 存储每轮测试准确率
for epoch in range(epochs): # 循环50轮训练
# ------------ 训练阶段 ------------
model.train() # 将模型切换到“训练模式”(关键!启用 dropout/batchnorm 等训练特性)
# 调用train函数,返回当前轮的训练准确率和损失
epoch_train_acc,epoch_train_loss = train(train_dl, model, loss_fn, opt)
# ------------ 测试阶段 ------------
model.eval() # 将模型切换到“评估模式”(关键!关闭 dropout/batchnorm 等训练特性,保证测试稳定)
# 调用test函数,返回当前轮的测试准确率和损失
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
# ------------ 记录指标 ------------
train_acc.append(epoch_train_acc) # 保存当前轮训练准确率
train_loss.append(epoch_train_loss) # 保存当前轮训练损失
test_acc.append(epoch_test_acc) # 保存当前轮测试准确率
test_loss.append(epoch_test_loss) # 保存当前轮测试损失
# ------------ 获取并打印当前学习率 ------------
lr= opt.state_dict()['param_groups'][0]['lr'] # 从优化器中提取当前学习率
# 格式化输出当前轮的所有指标
'''
Epoch: 5, Train_acc:85.2, Train_loss:0.321, Test_acc:82.5, Test_loss:0.389, Lr:1.00E-04
含义:第 5 轮训练后,训练集准确率 85.2%,损失 0.321;测试集准确率 82.5%,损失 0.389;当前学习率为 0.0001。
'''
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(
epoch+1, # 轮次(从1开始)
epoch_train_acc*100, # 训练准确率(×100转为百分比)
epoch_train_loss, # 训练损失
epoch_test_acc*100, # 测试准确率(×100转为百分比)
epoch_test_loss, # 测试损失
lr # 学习率(科学计数法显示)
))
print("="*20, 'Done', "="*20)Epoch: 1, Train_acc:44.1%, Train_loss:0.698, Test_acc:54.8%, Test_loss:0.681, Lr:1.00E-04
Epoch: 2, Train_acc:50.0%, Train_loss:0.686, Test_acc:80.6%, Test_loss:0.666, Lr:1.00E-04
Epoch: 3, Train_acc:59.9%, Train_loss:0.675, Test_acc:80.6%, Test_loss:0.652, Lr:1.00E-04
Epoch: 4, Train_acc:69.9%, Train_loss:0.664, Test_acc:80.6%, Test_loss:0.638, Lr:1.00E-04
Epoch: 5, Train_acc:75.0%, Train_loss:0.654, Test_acc:83.9%, Test_loss:0.623, Lr:1.00E-04
Epoch: 6, Train_acc:77.6%, Train_loss:0.643, Test_acc:83.9%, Test_loss:0.609, Lr:1.00E-04
Epoch: 7, Train_acc:79.0%, Train_loss:0.633, Test_acc:83.9%, Test_loss:0.595, Lr:1.00E-04
Epoch: 8, Train_acc:82.4%, Train_loss:0.622, Test_acc:83.9%, Test_loss:0.581, Lr:1.00E-04
Epoch: 9, Train_acc:82.0%, Train_loss:0.611, Test_acc:83.9%, Test_loss:0.566, Lr:1.00E-04
......
Epoch:45, Train_acc:84.6%, Train_loss:0.360, Test_acc:87.1%, Test_loss:0.291, Lr:1.00E-04
Epoch:46, Train_acc:84.6%, Train_loss:0.358, Test_acc:87.1%, Test_loss:0.291, Lr:1.00E-04
Epoch:47, Train_acc:84.6%, Train_loss:0.357, Test_acc:87.1%, Test_loss:0.292, Lr:1.00E-04
Epoch:48, Train_acc:84.6%, Train_loss:0.356, Test_acc:87.1%, Test_loss:0.292, Lr:1.00E-04
Epoch:49, Train_acc:84.6%, Train_loss:0.355, Test_acc:87.1%, Test_loss:0.293, Lr:1.00E-04
Epoch:50, Train_acc:84.6%, Train_loss:0.354, Test_acc:87.1%, Test_loss:0.293, Lr:1.00E-04
==================== Done ====================四、模型评估
1.Loss与Accuracy
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use('TkAgg') # 解决中文显示问题
%matplotlib inline
from datetime import datetime
#隐藏告警
import warnings
warnings.filterwarnings("ignore")
current_time = datetime.now()
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.rcParams['figure.dpi'] = 200 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12,3))
plt.subplot(1,2,1)
plt.plot(epochs_range, train_acc, label='Train Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc= 'lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time)
plt.subplot(1,2,2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc= 'upper right')
plt.title('Training and Validation Loss')
plt.show()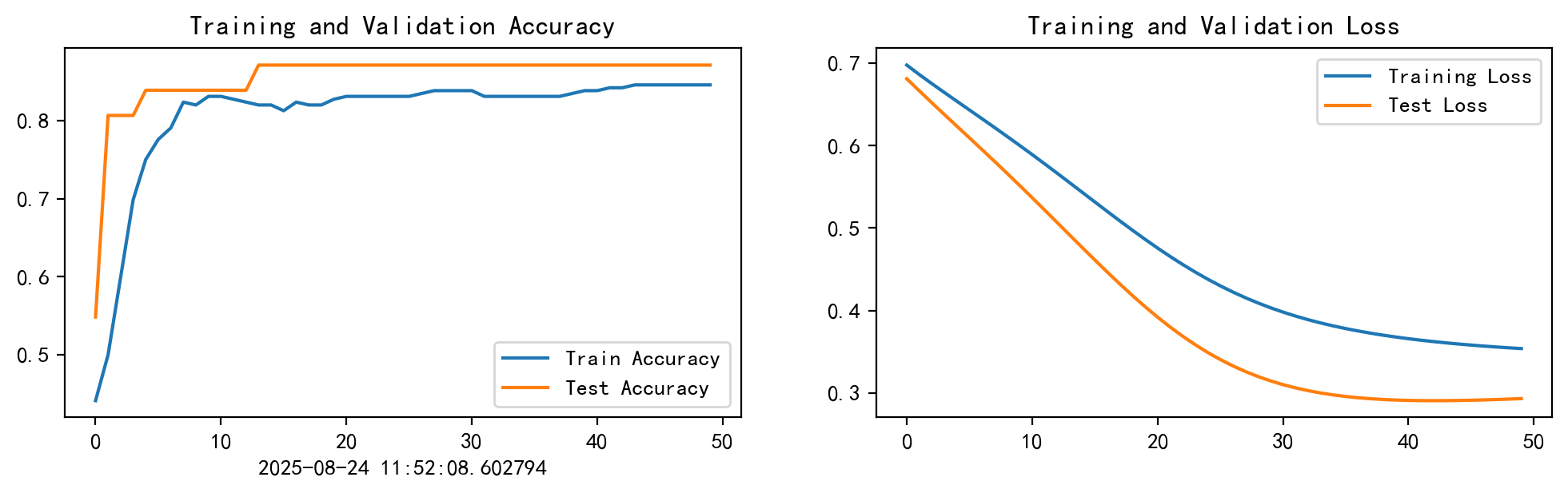
2.混淆矩阵
print("====输入数据Shape为====")
print("X_test.shape:", X_test.shape)
print("y_test.shape:", y_test.shape)
pred =model(X_test.to(device)).argmax(1).cpu().numpy()
print("\n====输出数据Shape为====")
print("pred.shape:", pred.shape)====输入数据Shape为====
X_test.shape: torch.Size([31, 1, 13])
y_test.shape: torch.Size([31])
====输出数据Shape为====
pred.shape: (31,)import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm=confusion_matrix(y_test, pred)
plt.figure(figsize=(6,5))
plt.suptitle('')
sns.heatmap(cm, annot=True, fmt="d", cmap = "Blues")
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.title("Confusion Matrix", fontsize=12)
plt.xlabel("Predicted Label", fontsize=10)
plt.ylabel("True Label", fontsize=10)
plt.tight_layout()
plt.show()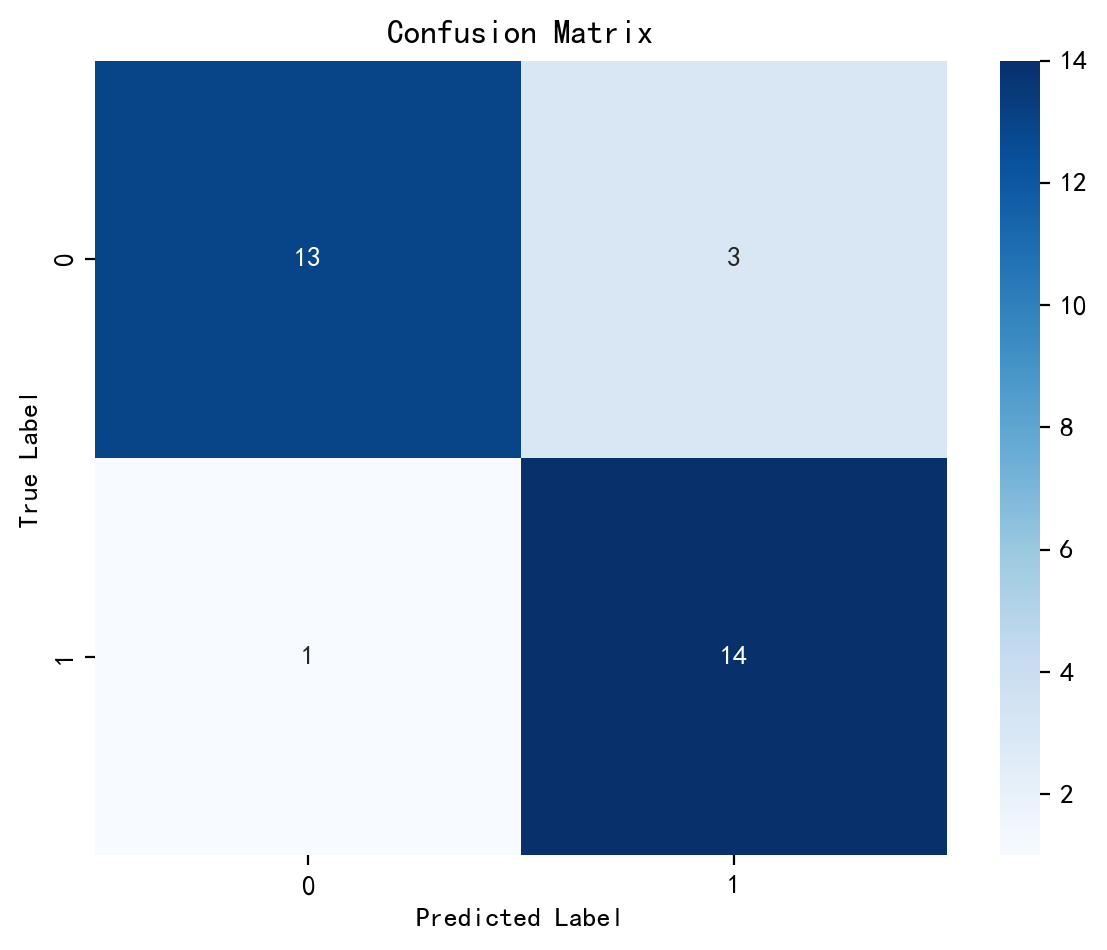
test_X = X_test[0].unsqueeze(1)
pred =model(test_X.to(device)).argmax(1).item()
print("模型预测结果为:",pred)
print("=="*20)
print("0:不会患心脏病")
print("1:可能患心脏病")模型预测结果为: 0
========================================
0:不会患心脏病
1:可能患心脏病通过该项目,大概知道了RNN的运行流程,后续继续做项目加油


















 1908
1908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











