










作者:小灰灰 来源:投稿
编辑:学姐
上期传送门👉单张图像三维人脸重建必备入门face3d—3DMM
三维人脸的必备入门就要看Yao Feng写的https://github.com/YadiraF/face3d 这个代码主要介绍了3D人脸的一些功能,处理网格数据,生成3D人脸,从单张二维人脸图片重建三维图像,face3D是个非常轻量化的,而且都是用numpy写的。
下载代码:
git clone https://github.com/YadiraF/face3d
cd face3d
编译c++文件
cd face3d/mesh/cython
python setup.py build_ext -i
准备BFM文件:
https://github.com/YadiraF/face3d/blob/master/examples/Data/BFM/readme.md
接下来就可以运行下面8个例子。
运行python 1_pipeline.py
运行出结果

接下来对 1 pipeline的详细解读。
这个算法主要介绍了一些常用的技术,投影,旋转,平移,变换等,pipeline输入是一个三维人脸,投影到二维图片,对原始的三维人脸做一些光照,旋转,平移等一些操作,然后投影到二维图像中,并进行着色。1_pipeline做的就是这样的操作。上面的图片就是渲染出来的操作,输入就只有正脸,没有什么光照,就只有顶点和纹理的信息。这部分将会理解三维变换到二维是怎么做的。
导入三维模型
我们首先导入三维模型,看看三维模型里面存储的数据。

上面的代码就是导入三维模型,读取顶点信息vertices,顶点上的颜色信息colors,三角面片信息triangles。

根据debug结果可看到,vertices=-57269.51394714276 35239.70262979373 81402.35405980109(shape=(53215,3))表示它的三维顶点x,y,z的值,colors=0.6821081325185221 0.48736642660892804 0.39795203018737824(shape=53215,3) 表示顶点x,y,z的点所表示的颜色信息,r,g,b的值,triangles=0 130 1(shape=105840,3)表示顶点序列0,130,1三个顶点序列连接起来构成的三角面片。

上图默认序列是从0开始,按顺序向下数到0到53214总共53215个顶点。
可以看到,导入的模型库的可视化为:

modify vertices
s = 180/(np.max(vertices[:,1]) - np.min(vertices[:,1]))
是将x,y,z中的y的最大值减去最低值,求得比例系数,可得

输入的三维模型是一个正脸的模型,接下来我们对原始的正脸进行旋转,

这个是对人脸进行pitch, yaw, rol角度的设置,具体详情可看
https://www.cnblogs.com/xiaoxiaoqingyi/p/6932008.html
改变pitch, yaw, rol的不同角度可得。

angle2matrix
接下来看,旋转矩阵angle2matrix([0, 30, 0])进到函数可看到:
旋转的角度x,y,z假设绕x轴旋转,pitch代表抬头,点头,yaw摇头,z表示歪头。
x, y, z = np.deg2rad(angles[0]), np.deg2rad(angles[1]), np.deg2rad(angles[2])
表示将角度信息转换为弧度信息。
接下来绕x,y,z旋转矩阵可表示:
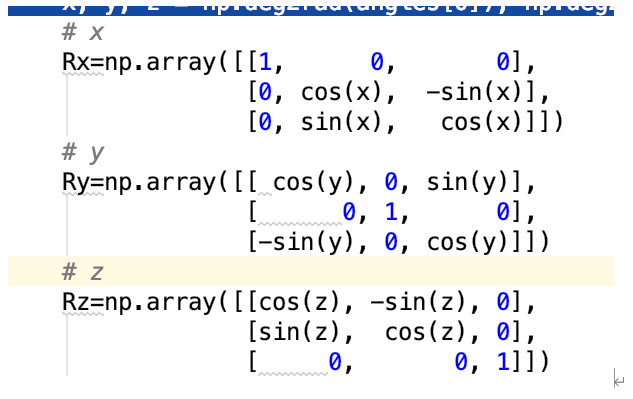
「可最终得到的旋转矩阵为:」
R=Rz.dot(Ry.dot(Rx))

平移t = [0, 0, 0] 那么s,r,t都有了,接下来对顶点做操作
similarity_transform

是根据s,r,t进行操作,先对顶点进行旋转矩阵相乘,在乘缩放因子,在加偏移,可得到
transformed_vertices(shape=53215,3)
「可视化为:」
左图为无颜色,右图为有颜色。

modify colors/texture(add light)
这个是颜色的信息,在已经有r,g,b的颜色信息上进行处理,为什么要进行处理,因为要进行颜色的渲染,需要使用到光照模型,将某些地方进行打光,首先要确定打光的位置点。
light_positions = np.array([[-128, -128, 300]])
这行代码是确定光照的位置放在-128, -128, 300点上。为什么要设置二维数组,是因为有可能有多个光点。
light_intensities = np.array([[1, 1, 1]])
是r,g,b三个光照的强度,也就是发的什么光,例如我们将[[1, 1, 1]] 变换成[[1, 0, 1]],可得下图:

add_light
传参为:transformed_vertices, triangles, colors, light_positions, light_intensities)
这个函数是对原始的颜色进行处理,我们需要用到转换后的顶点transformed_vertices,三角剖分triangles,原始的颜色colors,light_positions光的位置,light_intensities对光的强度。
第一步:我们求三维人脸顶点所对应的法向量normal,
normals = get_normal(vertices, triangles) # [nver, 3]
我们将三角形的第一列,第二列,第三列取出来,得到点的信息,得到向量,将图片中的向量进行X乘。得到垂直于三角平面的法向量。
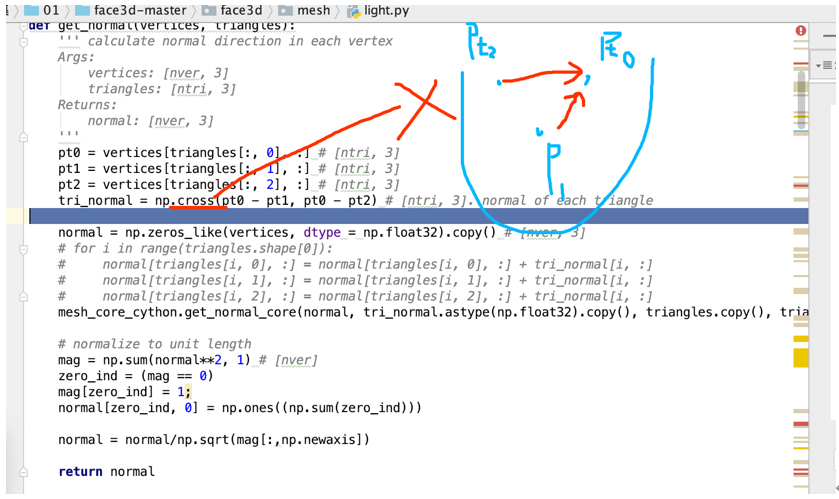
但是我们要求点的法向量。将周围的三角形的法向量加起来求平均值就是点的法向量。
normal = np.zeros_like(vertices, dtype = np.float32).copy() # [nver, 3]
mesh_core_cython.get_normal_core(normal, tri_normal.astype(np.float32).c
opy(), triangles.copy(), triangles.shape[0])
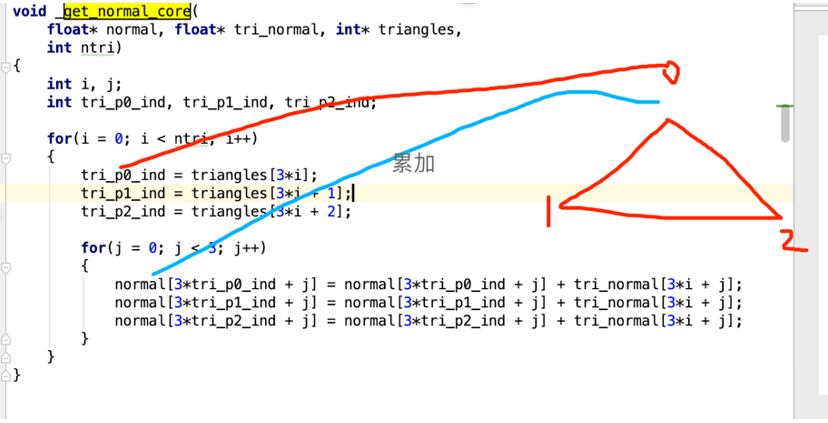
「这段函数就是求取每个点的法向量。」
得到的法向量进行归一化。
normal = normal/np.sqrt(mag[:,np.newaxis])
将模长为0时,强制设置成1,
mag[zero_ind] = 1;
得到每一点的法向量
normals = get_normal(vertices, triangles) # [nver, 3]
「第二步我们将得到的法向量,根据光照模型,添加光照。」
就是对r,g,b点根据法向量求取夹角。
direction_to_lights = vertices[np.newaxis, :, :] - light_positions[:, np.newaxis, :] # [nlight, nver, 3]
nlight表示的是有几种光源,never表示一个光源到53215到的向量。
direction_to_lights_n =np.sqrt(np.sum(direction_to_lights**2, axis = 2)) # [nlight, nver]
将向量进行归一化,
direction_to_lights = direction_to_lights/direction_to_lights_n[:, :, np.newaxis]
除以模长,此时得到的就是真正的光照到点的向量。
我们有了每一个点的法向量normals ,光线入射的向量direction_to_lights,那么就可以求得每一个点的夹角。夹角越大,光线更弱,
normals_dot_lights = normals[np.newaxis, :, :]*direction_to_lights # [nlight, nver, 3]
normals_dot_lights = np.sum(normals_dot_lights, axis = 2) # [nlight, nver]
去做点积,然后求和就可以求得cos值。

然后将颜色值r,g,b跟cos相乘,再跟关照强度进行相乘。
diffuse_output = colors[np.newaxis, :, :]*normals_dot_lights[:, :, np.newaxis]*light_intensities[:, np.newaxis, :]
我们将几束光进行求和。
diffuse_output = np.sum(diffuse_output, axis = 0) # [nver, 3]
得到光线到点的颜色值。
接下来对小于0的取1,主要用来得到暗的。
lit_colors = diffuse_output # only diffuse part here.
lit_colors = np.minimum(np.maximum(lit_colors, 0), 1)
最终我们得到光照的颜色值。可视化如图:

左边是原始图像,右边是添加光照之后的图像。

modify vertices(projection. change position of camera)
我们将顶点,颜色都进行变换了,那么接下来就是将三维模型渲染到二维图片。那么一般将现实世界进行拍照的时候,我们就要拿相机,进行拍照,所以首先的知道相机的位置。
camera_vertices = mesh.transform.lookat_camera(transformed_vertices, eye = [0, 0, 200], at =np.array([0, 0, 0]), up = None)
lookat_camera是照相机在看,需要变换的点transformed_vertices,eye表示照相机的位置,at是看哪个点[0, 0, 200],up是我的照相机向上看的方向。
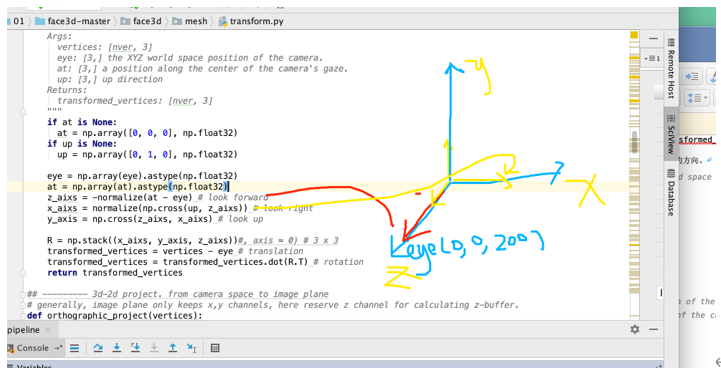
将拼接成一个矩阵,将矩阵减去一个eye,然后去乘一个旋转矩阵,返回的就是人脸的位置回归到照相机的位置,接着我们做了一个正交投影。
render(to 2d image)
这个主要是将坐标进行做一个变换。下面的代码就是做坐标的平移。
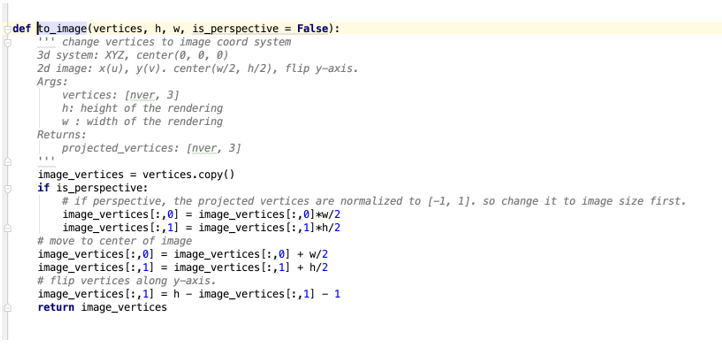
得到的值就是x,y的坐标

可以看到我们得到的是53215,3个点,但是我们想要变换成图片,大小应该是256*256的尺寸,怎样将53215个点放在图像上,就得渲染图像。
rendering = mesh.render.render_colors(image_vertices, triangles, lit_colors, h, w)
我们渲染图片需要点image_vertices,triangles, lit_colors, h, w
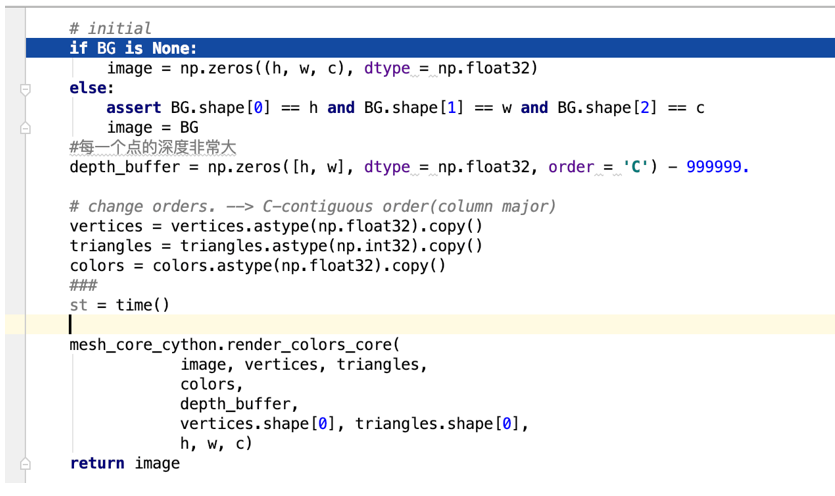
render_colors_core
主要是渲染图片,传入图片,点,三角面片。我们将三角形的三个点,得到三角形的内部的,进行三角剖分,得到每个三角形的索引.tri_p0_ind,tri_p1_ind,tri_p2_ind.
根据三角形的索引取得三个点的坐标,p0.x,p1.x,p2.x 算的横轴坐标的最大值最小值,x_min,x_max,y_min,y_max。用来求取三角形内部的像素值是多少。遍历矩阵里面三角形,求取的像素值。
p.x = x; p.y = y;默认为当前的点的像素值。通过isPointInTri c++函数来实现。
p0_color = colors[ctri_p0_ind + k];
p1_color = colors[ctri_p1_ind + k];
p2_color = colors[c*tri_p2_ind + k];
「通过三角面片的三个点求得colors值。」
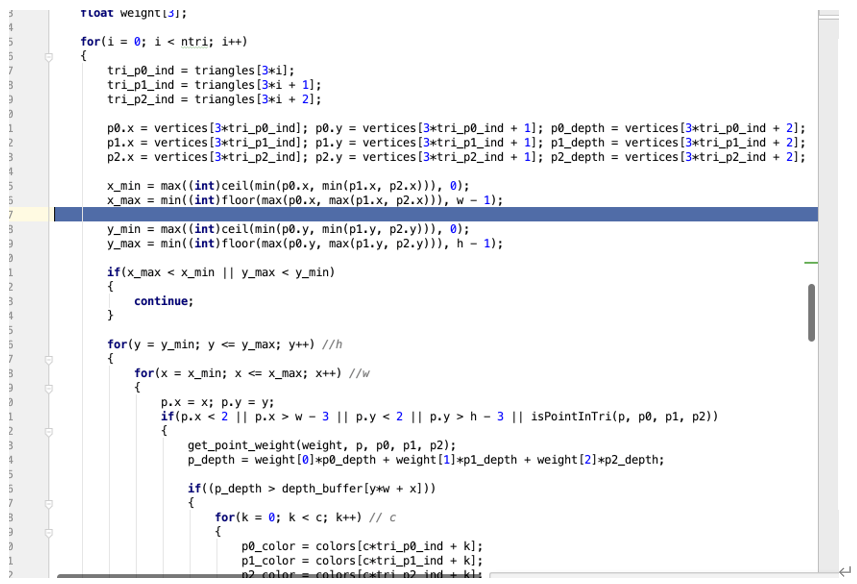
「最终求得图像的点的像素」
p_color = weight[0]*p0_color + weight[1]*p1_color + weight[2]*p2_color;
image[y*w*c + x*c + k] = p_color;
就可以求得。
最终取得的图片如下图

总结
整个流程就是将一个三维的人脸经过一系列的处理,旋转,平移,光照的流程。详细课程就请来深度之眼的三维重建paper专题来学习。
三维人脸重建经典论文解读👇👇👇点击卡片学起来















 6137
6137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









