










 文章提出了SEWResNet,一种解决脉冲神经网络(SNN)中深度学习问题的新方法。传统的SpikingResNet在实现身份映射和处理梯度消失/爆炸问题上存在困难,而SEWResNet通过元素级操作克服了这些挑战。在ImageNet、DVSGesture和CIFAR10-DVS数据集上的实验表明,SEWResNet在准确性和时间步长上均优于现有技术,且能通过增加网络深度提升性能。
文章提出了SEWResNet,一种解决脉冲神经网络(SNN)中深度学习问题的新方法。传统的SpikingResNet在实现身份映射和处理梯度消失/爆炸问题上存在困难,而SEWResNet通过元素级操作克服了这些挑战。在ImageNet、DVSGesture和CIFAR10-DVS数据集上的实验表明,SEWResNet在准确性和时间步长上均优于现有技术,且能通过增加网络深度提升性能。
来源:投稿 作者:小灰灰
编辑:学姐

论文标题:Deep Residual Learning in Spiking Neural Networks
论文链接: https://arxiv.org/pdf/2102.04159v3.pdf
代码链接:https: //github.com/fangwei123456/Spike-Element-Wise-ResNet.
摘要
由于discrete binary activation 和complex spatial- temporal dynamics ,脉冲神经网络(SNN)在基于梯度的方法中存在优化困难。考虑到ResNet在深度学习方面的巨大成功,用残差学习训练深度SNN是很自然的。之前的Spiking ResNet模拟了ANN中的标准残差块,并简单地用脉冲神经元替换ReLU激活层,这会导致退化问题,并且很难实现残差学习。在本文中,我们提出了基于脉冲网络的ResNet来实现深度SNN中的残差学习。我们证明了SEW-ResNet可以很容易地实现identity mapping 并克服Spiking ResNet的消失/爆炸梯度问题。我们在ImageNet、DVS Gesture和CIFAR10-DVS数据集上评估了SEW ResNet,并表明SEW ResNet在准确性和时间步长方面都优于最先进的直接训练SNN。此外,SEW ResNet可以通过简单地添加更多层来实现更高的性能,为深层SNN的训练提供了一种简单的方法。据我们所知,这是第一次可以直接训练100层以上的深层SNN。
介绍
人工神经网络(ANN)在许多任务中取得了巨大成功,包括图像分类、目标检测、机器翻译和游戏。ANN成功的关键因素之一是深度学习,它使用多层来学习具有多个抽象级别的数据表示。已经证明,较深的网络在计算成本和泛化能力方面优于较浅的网络。深度网络所代表的功能可能需要具有一个隐藏层的浅层网络具有指数数量的隐藏单元。此外,网络的深度与网络在实际任务中的表现密切相关。然而,最近的证据表明,随着网络深度的增加,精度会饱和,然后迅速下降。为了解决这一退化问题,提出了残差学习,并在实现领先性能的“非常深”网络中广泛利用残差结构。
SNN因其高生物合理性、事件驱动特性和低功耗而被视为ANN的潜在竞争对手。最近,深度学习方法被引入到SNN中,深度SNN在一些简单的分类数据集中取得了与ANN相近的性能,但在复杂的任务中,如对ImageNet数据集进行分类,其性能仍然不如ANN。为了获得更高性能的SNN,探索更深层的网络结构(如ResNet)是很自然的。Spiking ResNet作为ResNet的版本,是通过模拟ANN中的残差块并用脉冲神经元替换ReLU激活层而提出的。从ANN转换而来的Spiking ResNet在几乎所有数据集上都达到了一流的精度,而直接训练的SpikingResNet尚未被验证可以解决退化问题。
本文的贡献点:
在本文中,我们证明了Spiking ResNet不适用于所有神经元模型来实现identity mapping. 。即使满足identity mapping.条件,Spiking ResNet也会遇到梯度消失/爆炸的问题。因此,我们建议使用Spike Element Wise(SEW)ResNet来实现SNN中的残差学习。我们证明了SEW-ResNet可以很容易地实现身份映射,同时克服了消失/爆炸梯度问题。我们在ImageNet数据集和神经形态DVS手势数据集、CIFAR10-DVS数据集上评估了Spiking ResNet和SEW ResNet。实验结果与我们的分析相一致,表明深度较深的Spiking ResNet存在降级问题——深度较浅的网络的训练损失比深度较低的网络高,而SEW ResNet可以通过简单地增加网络深度来获得更高的性能。此外,我们还表明,SEW ResNet在精度和时间步长方面都优于最先进的直接训练SNN。据我们所知,这是第一次探索直接训练的超过100层的深层SNN。
方法
Spiking Neuron Model
脉冲神经元是SNN的基本计算单元。我们使用一个统一的模型来描述各种脉冲神经元的动力学。可以用充电,放电,重置的顺序来进行理解。
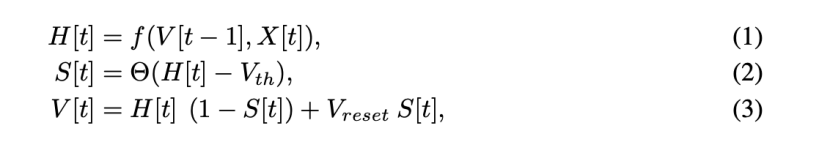
我们取前一个时刻的电压V[t-1],和输入电流X[t],来决定放电前的一个膜电位H[t],

X[t]是时间步t处的输入电流,H[t]和V[t]分别表示神经元动力学后和时间步长t处峰值触发后的膜电位,Vth是触发阈值,θ(x)是Heaviside阶跃函数,定义为
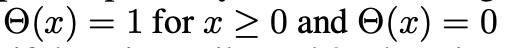
for x < 0 ,S[t]是时间步t的输出峰值,如果有峰值,则等于1,否则等于0。 表示复位电位。式(1)中的函数f(·)描述了神经元动力学,并针对不同的脉冲神经元模型采取了不同的形式。例如,Integrate and Fire(IF)模型和Leaky Integrate&Fire(LIF)模型的函数f(·)可以分别用公式(4)和公式(5)来描述。
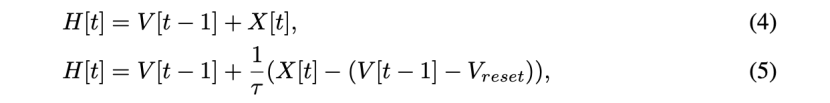
式中,τ表示膜时间常数。式(2)和式(3)描述了脉冲产生和重置过程,这对于所有类型的脉冲神经元模型都是相同的。本文用代理梯度法定义了
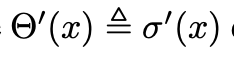
误差反向传,σ(x)表示代理函数。
Drawbacks of Spiking ResNet

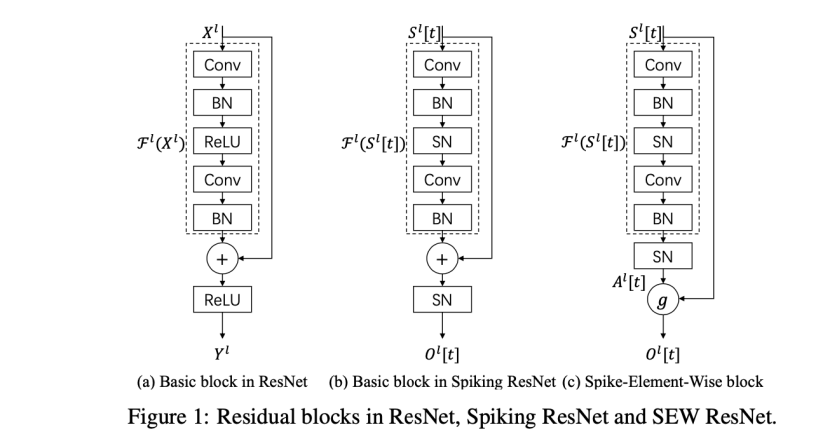
Spiking ResNet不适用于所有实现identity mapping 的神经元模型:
ResNet中的关键概念之一是identity mapping 。如果添加的层实现了identity mapping ,则更深层次的模型的训练误差不应大于较浅层次的模型。然而,它无法在可行的时间内对添加的层进行训练以实现identity mapping ,从而导致较深的模型的性能比较浅的模型差(退化问题)。为了解决这个问题,通过添加一个shortcut 连接(如图1(a)所示),提出了残差学习。如果我们使用Fl 表示ResNet和Spiking ResNet中第1个残差块的残差映射,例如两个卷积层的堆栈,那么图1(a)和图1(b)中的残差块可以表示为
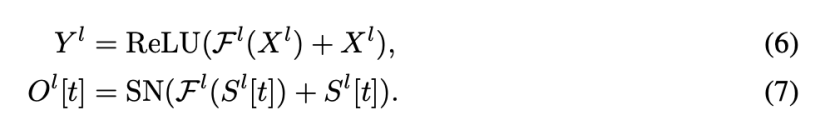
方程(6)的残差块使得在人工神经网络中实现identity mapping 变得容易。
要看到这一点,
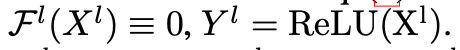
在大多数情况下,是先前ReLU层的激活,因此 这是identity mapping。
与ResNet不同,Spiking ResNet中的残差块限制了脉冲模型神经元实现identity mapping。S作为输入的脉冲,是非0即1的;当残差F为0时,公式(7)变为O[t]=SN(S[t]),而SN(S[t])往往不等于S[t],这就不能实现恒等映射。
Spike-Element-Wise ResNet
提出了Spike Element Wise(SEW)残差块来实现SNN中的残差学习,它可以方便地实现身份映射,同时克服消失/爆炸梯度问题。如图1(c)所示,SEW残余块体可以表示为:
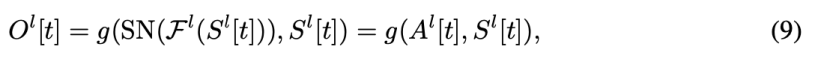




SEW ResNet can overcome vanishing/exploding gradient.:
SEW块类似于ANN中的ReLU before addition(RBA)块[15],可公式化为:

实验
ImageNet Classification
因为ImageNet 2012的测试数据集没有公开,我们无法获取实际测试精度。我们使用验证集的准确度作为测试准确度,[14]等人在ImageNet数据集上评估了18/34/50/101/152层ResNets。为了进行比较,我们考虑具有相同网络架构的SNN,我们把basic residual block (图1(a))用spiking basic block (图一(b))和SEW ResNet (图一(c))代替。静态ImageNet数据集采用IF神经元模型。在ImageNet上的训练期间,我们发现,除非我们使用零初始化,否则Spiking ResNet-50/101/152无法收敛,该初始化在训练开始时将所有块设置为identity mapping 。因此,本文的Spiking ResNet-18/34/50/101/152的结果是零初始化的。
Spiking ResNet vs. SEW ResNet.:我们首先评估Spiking ResNet和SEW ResNet的性能。表2报告了ImageNet验证的测试精度
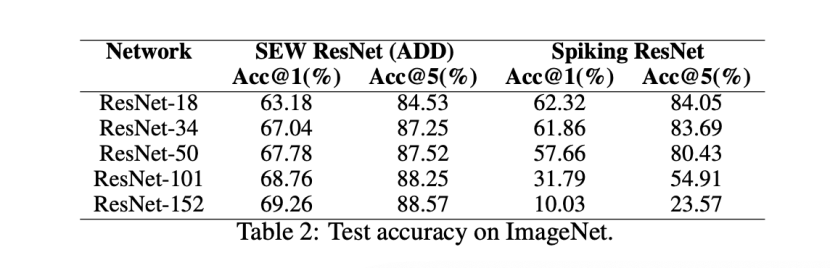
结果表明,较深的34层Spiking ResNet的测试精度低于较浅的18层SpikingResNet。随着层的增加,Spiking ResNet的测试精度降低。为了揭示原因,我们比较了训练过程中Spiking ResNet的训练损失、训练精度和测试精度,如图3所示。更重要的是,从图3可以看出,随着深度的增加,SEW ResNet的训练损失减少,训练/测试精度增加,这表明我们可以通过简单地增加网络深度来获得更高的性能。所有这些结果表明,SEW ResNet很好地解决了退化问题。
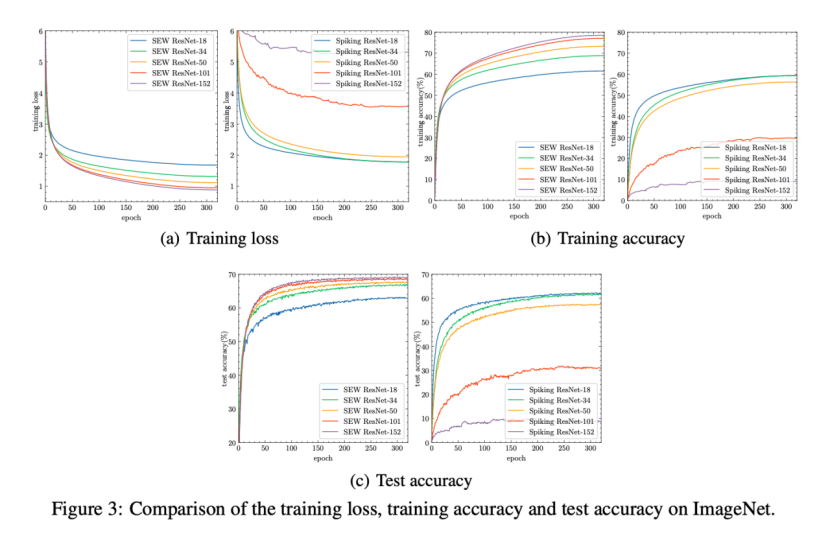
我们可以发现Spiking ResNet的退化问题——较深的网络比较浅的网络有更高的训练损失。相比之下,较深的34层SEW ResNet的测试精度高于较浅的18层SEW ResNet(如表2所示)。
Comparisons with State-of-the-art Methods. 在表3中,我们将SEW ResNet与之前在ImageNet上获得最佳结果的Spiking ResNets进行了比较。

据我们所知,SEW ResNet-101和SEW ResNet-152是迄今为止唯一具有超过100层的SNN,并且没有其他具有相同结构的网络可供比较。当网络结构相同时,我们的SEW ResNet优于直接训练的Spiking ResNet的精度,同时时间步长T更少。SEW ResNet-34的精度略低于使用td BN(67.04%v.s.67.05%)的Spiking ResNet-34(大型),它使用的时间步长T(6 v.s.4)是我们SEW ResNet的1.5倍,参数数量(85.5M v.s.21.8M)是我们的4倍。最先进的ANN2SNN方法比我们的SEW ResNet具有更好的准确性,但它们分别使用的时间步长是我们的64倍和87.5倍。
Gradients Check on ResNet-152 Structure.
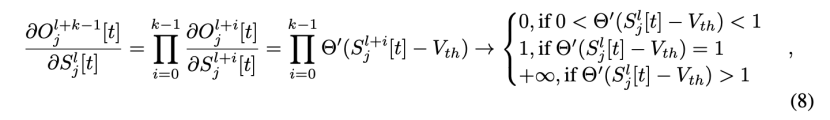
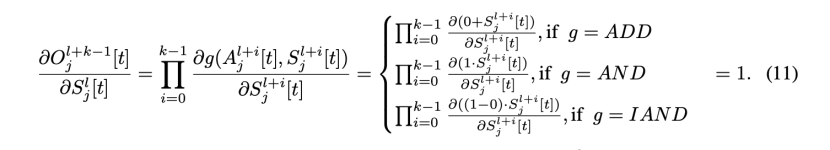
式(8)和式(11)分析了gradients of multiple blocks with identity mapping,为了验证SEW ResNet能够克服消失/爆炸梯度,我们检查了Spiking ResNet-152和SEW ResNet-152的梯度,它们是最深的标准ResNet结构。我们考虑相同的初始化参数,并且有/没有零初始化。
由于SNN的梯度受到发射率的显著影响,我们首先分析firing rate 。图5(a)显示了第l块输出的初始firing rate,下采样块用垂直虚线标记。两条相邻虚线之间的块表示identity mapping areas ,并且具有相同形状的输入和输出,使用零初始化时,Spiking ResNet、SEW AND ResNet,SEW IAND ResNet和SEW ADD ResNet具有相同的firing rates(绿色曲线),即零初始化曲线。如果不进行零初始化,silence 问题会发生在SEW AND网络(红色曲线)中,SEW IAND网络(紫色曲线)可以缓解silence 问题。图5(b)显示了的firing rate ,它表示第l块中最后一个SN的输出,可以发现,尽管SEW ADD ResNet中
的firing rate 在identity mapping 中线性增加,但每个块中的最后一个SN仍然保持稳定的firing rate。请注意,当g为ADD时,SEW块的输出不是二进制的,firing rate实际上是平均值, SEW IAND ResNet的SN保持适当的firing rate,并随深度略有衰减(紫色曲线),而SEW AND ResNet深层的SN则保持不变(橙色曲线)。这中现象可以这样解释。当我们使用
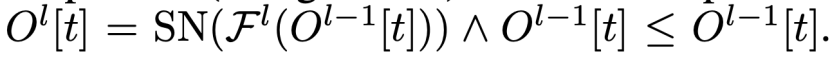
在没一个时间步t时,它很难保持 , g 为AND,SEW ResNet中经常会出现静止问题,使用IAND替代AND可以缓解这个问题,因为它很容易保持每个时间步
我们在所有实验中使用的替代梯度函数是

,因此,它的导数为
DVS Gesture Classification
用于对复杂ImageNet数据集进行分类的原始ResNet对于DVS手势数据集来说太大,因此,我们设计了一个名为7B-Net的小型网络,其结构为c32k3s1-BN-PLIF-{SEW Block-MPk2s2}*7-FC11. 这里,c32k3s1表示具有通道32、卷积核大小3、步长1的卷积层。MPk2s2是卷积核大小为2,步长为2的最大池化层。符号{}*7表示七个重复结构,PLIF表示具有可学习膜时间常数的Parametric Leaky-Integrate-and- Fire 脉冲神经元。
Spiking ResNet vs. SEW ResNet.
我们首先通过将基本块SEW块替换为(SEW ADD ResNet) and Spiking ResNet 。如图9和表4所示,虽然Spiking ResNet的训练损失(蓝色曲线)低于SEW ADD ResNet(橙色曲线),但测试精度低于SEW ADD ResNet,分别为90.97%和97.92%,这意味着Spiking ResNet比SEW ADD-ResNet更容易过拟合。


Evaluation of different element-wise functions and plain block.:
由于DVS手势数据集上SNN的训练成本比ImageNet上低得多,因此我们对DVS手势数据库进行了更多的消融实验。我们将SEW块替换为普通块(无short- cut connection )并测试性能。我们还评估了表1中的各种元素函数g。图9显示了DVS手势的训练损失和训练/测试精度。

早期时期的波动是由学习率高引起的。我们可以发现,训练损失为SEW IAND<Spiking ResNet<SEW ADD<Plain Net<SEW AND。由于过拟合问题,较低的损耗不能保证较高的测试精度。表4显示了所有网络的测试精度。SEW ADD ResNet的准确度最高.
Comparisons with State-of-the-art Methods:
表5将我们的网络与SOTA方法进行了比较。可以发现,我们的SEW ResNet在精度、参数数量和模拟时间步长方面优于SOTA。

CIFAR10-DVS Classification
我们还实验了关于CIFAR10-DVS数据集的SEW ResNet,该数据集是通过DVS摄像机在LCD监视器上记录CIFAR-10数据集的运动图像而获得的,由于CIFAR10-DVS比DVS手势更复杂,我们使用名为Wide-7B-Net的网络结构,它类似于7B-Net,但具有更多通道。Wide-7B-Net的结构为c64k3s1-BN-PLIF-{SEW Block (c64)-MPk2s2}*4-c128k3s1-BN-PLIF-{SEW Block (c128)-MPk2s2}*3-FC10. 在表6中,我们将SEW ResNet与之前的Spiking ResNet进行了比较。我们可以发现,与Spiking ResNet相比,我们的方法实现了更好的性能(70.2%对67.8%)和更少的时间步长(8对10)。我们还将我们的方法与CIFAR10-DVS上最先进的(SOTA)监督学习方法进行了比较。我们的Wide-7B-Net的精度略低于当前的SOTA方法[8](74.4%vs.s.74.8%),该方法使用1.25倍的模拟时间步长T(20 vs.s.16)和14.6倍的参数数量(17.4M vs.s.1.19M)。此外,当将T形状减少到T=4时,我们的Wide-7B-Net仍然可以获得64.8%的精度。

Conclusion
本文分析了以前的Spiking ResNet,发现它很难实现identity mapping ,并且存在消失/爆炸梯度的问题。为了解决这些问题,我们提出了SEW残差块,并证明了它可以实现残差学习。在ImageNet、DVS Gesture和CIFAR10-DVS数据集上的实验结果表明,我们的SEW残差块解决了退化问题,SEW ResNet可以通过简单地增加网络深度来实现更高的精度。我们的工作可能有助于了解“非常深层”的SNN。
关注下方【学姐带你玩AI】🚀🚀🚀
回复“机器学习”领取机器学习资料合集
码字不易,欢迎大家点赞评论收藏!

















 1892
1892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









