









谷歌最新发布了Mixture-of-Depths(MoD)。这是一种通过动态分配计算资源来提高计算效率的新型transformer模型。在等效计算量和训练时间上,MoD每次前向传递所需的FLOPs比传统模型少,后训练采样过程中步进速度更快,提高了50%。
这种策略让Transformer省去不必要的计算,大大降低成本,解决了传统Transformer在前向传播中为每个Token花费相同计算量,导致某些token被过度处理或处理不足,最后影响效率的问题。
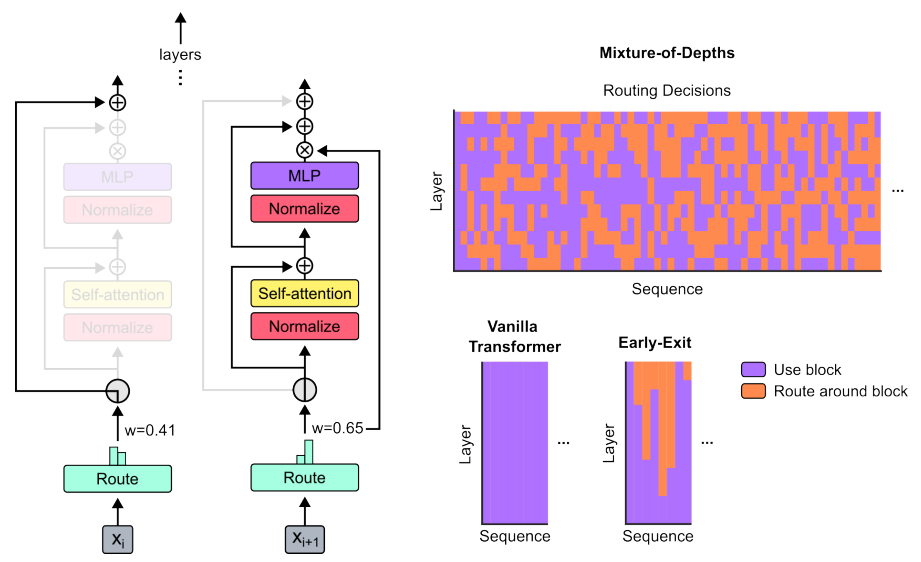
右上图中的橙色部分,表示没有使用全部计算资源
目前,提升Transformer的运行效率不仅是研究热点,也是AI领域的关键技术挑战之一。MoD的提出成功解决了计算资源分配和硬件限制等关键挑战,并实现了硬件效率的提升、性能的提高以及训练速度的加快。
除MoD之外,研究者们还提出了很多值得学习的Transformer提速优化方案,这次我整理了29个,这些方案主要涉及卷积Attention、Transformer处理长文本等方向,创新点我已经简单提炼了,附上开源代码方便各位复现。
论文和开源代码需要的同学看文末
MoD
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
方法:论文提出了Mixture-of-Depths (MoD)的新型transformer模型,该模型通过动态分配计算资源来提高计算效率。与传统的transformer模型相比,MoD模型可以根据每个令牌的需求动态决定是否进行计算,从而节省计算资源。MoD模型使用了一种学习路由机制,通过路由决策将令牌分配到计算路径中。

创新点:
-
Mixture-of-Depths(MoD)Transformer模型:引入了一种新的Transformer模型,通过动态分配计算资源,实现了在序列的不同位置和不同层之间优化计算资源的分配。与传统的Transformer模型相比,MoD模型可以在保持性能不变的情况下,以更少的计算资源进行前馈传递,并且在训练过程中可以比传统模型快50%以上。
-
条件计算的学习路由机制:提出了一种基于学习的路由机制,用于确定在每个层中哪些令牌应该参与计算。通过学习路由决策,模型可以根据令牌的特征和任务需求,智能地决定是否将其路由到计算路径中。这种学习路由机制可以有效地减少计算资源的使用,并提高模型的性能。

HoT
Hourglass Tokenizer for Efficient Transformer-Based 3D Human Pose Estimation
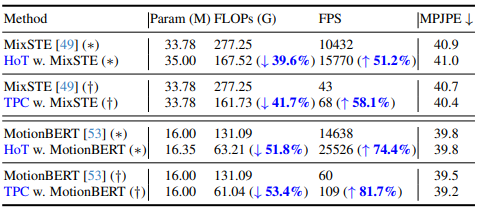
方法:论文提出了一种剪枝与恢复框架,用于从视频中高效进行基于Transformer的3D HPE。与现有的方法不同,该方法首先剪枝冗余帧的姿态标记,然后恢复完整的标记序列。通过这两个设计,可以在中间的Transformer模块中只保留少量的标记,从而提高模型的效率。
为了实现这一点,作者提出了TPC模块,利用聚类选择具有高语义多样性的代表性标记。此外,还提出了TRA模块,根据选择的标记恢复详细的时空信息,将剪枝操作引起的低时空分辨率扩展到完整的时空分辨率。
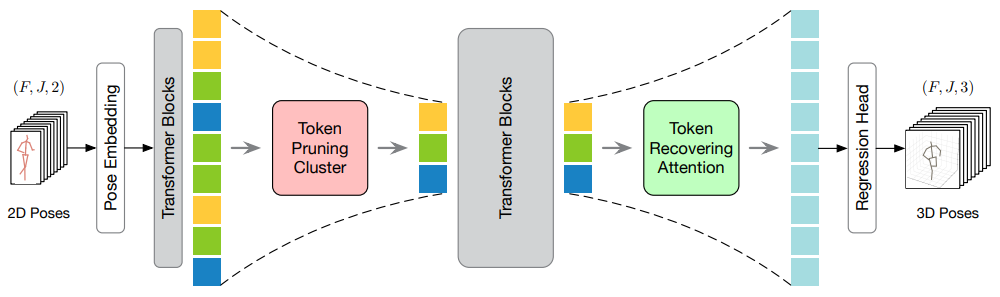
创新点:
-
提出了HoT框架,用于高效的基于Transformer的三维人体姿势估计。HoT揭示了保留完整的姿势序列是冗余的,只需选择少数几个代表性帧的姿势令牌即可实现高效和性能的平衡。
-
提出了TPC模块和TRA模块,用于高效加速VPTs。TPC模块用于选择具有高语义多样性的代表性令牌,以减少视频冗余;TRA模块用于恢复原始的时间分辨率,以实现快速推断。
SEA
SEA: SPARSE LINEAR ATTENTION WITH ESTIMATED ATTENTION MASK
方法:论文提出一种新的稀疏线性注意力方法(SEA),通过压缩注意力矩阵并使用知识蒸馏的方式,以线性复杂度估计预训练模型的注意力矩阵,从而减少注意力机制的空间和时间复杂度,同时保持类似于预训练模型的性能和可解释性。

创新点:
-
提出了一种新颖的测试时线性注意力机制(SEA),将预训练二次变换器的知识提炼成压缩的估计注意力矩阵,然后用于创建最终注意力操作的稀疏注意力掩码。SEA在测试时的复杂度为O(T),不需要蒸馏步骤。
-
通过可视化估计的稀疏注意力矩阵并与教师的注意力矩阵进行比较,展示了该方法的可解释性。作者的估计器可以估计自注意力和因果注意力。

Lightning Attention-2
Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
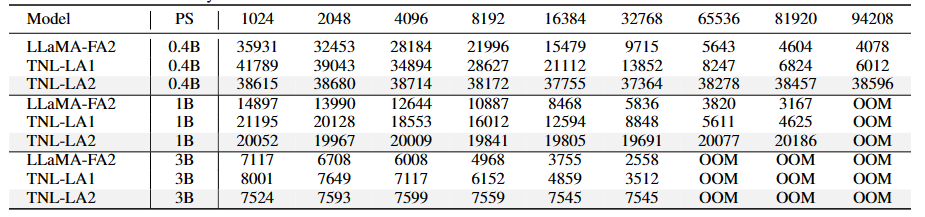
方法:论文提出Lightning Attention-2线性注意力机制,以实现线性注意力的理论计算优势。通过采用"分而治之"和平铺技术的概念,该方法成功解决了当前线性注意力算法的局限性,特别是与累积求和相关的挑战。通过将计算分为内部块和间隔块组件,该方法充分利用GPU硬件的潜力,确保效率。
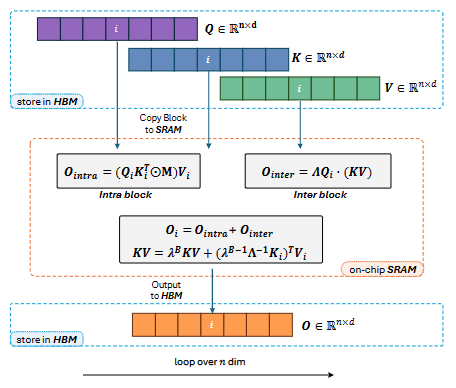
创新点:
-
Lightning Attention-2在计算速度上具有显著优势,这归功于其创新的内部-外部分离策略。
-
Lightning Attention-2相比其他机制具有更小的内存占用,而不会影响性能。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“提速29”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









