







 本文提出了一种运动预测模型,借助矢量化地图表示和LaneGCN,有效捕捉车道拓扑及长距离依赖。模型通过融合参与者-车道交互,生成更准确的多模态轨迹预测,且在大规模Argoverse基准上超越现有技术。
本文提出了一种运动预测模型,借助矢量化地图表示和LaneGCN,有效捕捉车道拓扑及长距离依赖。模型通过融合参与者-车道交互,生成更准确的多模态轨迹预测,且在大规模Argoverse基准上超越现有技术。
引言
我们提出了一个运动预测模型,该模型利用了一种新的结构化地图表示以及演员-地图交互。我们通过对原始地图进行矢量化来构建地图,而不是将原始地图中的数据进行矢量化。为了捕捉车道图的复杂拓扑结构和长距离依赖关系,我们提出了LaneGCN,它用多个邻接矩阵和沿车道扩展扩展图卷积。为了捕捉参与者和地图之间的复杂交互,我们开发了一个融合网络,该网络由四种类型的交互组成:参与者到车道、车道到车道、车道到参与者和参与者到参与者。在LaneGCN和演员地图交互的支持下,我们的模型能够预测准确而真实的多模态轨迹。
我们的方法在大规模Argoverse运动预测基准上显著优于最先进的方法。
1. 介绍
自动驾驶有可能彻底改变交通。为了安全运行,自动驾驶车辆(SDV)必须准确预测其他交通参与者的未来运动。高清地图(HD maps)为运动预测提供了非常有用的几何和语义信息,因为参与者的行为在很大程度上取决于地图拓扑。例如,当附近没有左转车道时,车辆不太可能左转。有效地利用高清地图对于运动预测模型产生合理和准确的轨迹至关重要。
该引用第一次尝试将高清地图作为启发法[42]。该方法首先将参与者与车道关联,然后根据地图拓扑生成所有候选运动路径。这样,预测结果就受到地图的约束。然而,这种方法无法捕捉罕见的不合规行为,这些行为虽然不太可能发生,但可能对安全至关重要。
最近的工作[38,14,29,3,23,7,5,6]使用机器学习从地图中学习语义表示。为了使高清地图能够由神经网络处理,地图数据被光栅化,以创建类似图像的光栅输入。地图拓扑隐式编码为线条、遮罩或颜色,然后由二维卷积神经网络(CNN)处理。这些学习到的地图特征为运动预测提供了有用的背景信息。然而,这些方法有两个缺点。其次,地图具有复杂拓扑结构的图形结构,二维卷积可能很难捕获这些特征。例如,相关的车道可能会在车道方向上延伸很长的距离。为了捕捉这些信息,感受野必须非常大,不仅覆盖预期区域,还覆盖车道外的大片区域。此外,相同或相反方向上的车道对具有完全不同的语义和依赖性,尽管两个车道对中的车道在空间上彼此接近。
在本文中,我们做了三个主要贡献:
(1) 我们不使用光栅化,而是从矢量化的地图数据中构造车道图,从而避免了信息丢失。
然后,我们提出了车道图卷积网络(LaneGCN),它有效地捕捉了车道图的复杂拓扑结构和长程依赖关系。
(2) 基于LaneGCN,我们的运动预测模型捕获了所有可能的演员-地图交互。特别是,我们将参与者和车道都表示为图中的节点,并使用一维CNN和LaneGCN分别提取参与者和车道节点的特征,然后利用空间注意和另一个LaneGCN来模拟四种类型的交互:参与者到车道、车道到车道、车道到参与者和参与者到参与者。我们让读者参考图1来了解我们的方法。
(3) 我们在大型Argoverse运动预测基准[9]上进行了实验,并显示出与最先进的技术相比有显著的改进。
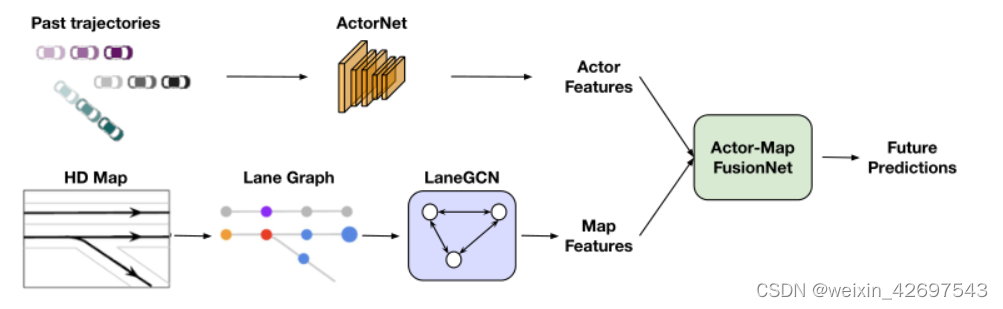
图1:我们从原始地图数据中构造了一个车道图,并使用LaneGCN提取地图特征。同时,ActorNet从观察到的过去轨迹中提取演员特征。然后,我们使用FusionNet对参与者自身和地图之间的交互进行建模,并预测未来的轨迹。
2. 相关工作
在本节中,我们将回顾有关地图表示、学习自治任务的地图表示以及图卷积网络的工作。
地图表示:[21]提出将车道边界参数化为一组多段线,并利用递归神经网络(RNN)从传感器数据中提取它们。[28]进一步将多段线表示扩展到更结构化的参数化。[22]提出将未知车道图参数化为有向无环图形模型(DAG),而不是对每条车道的几何结构进行建模,DAG更稳健,能够处理更复杂的拓扑结构,如分支。除了对几何图形进行建模外,[33,32]还在图形模型中对不同的车道类型进行编码,以便更好地利用它们的外观特征。[11] 使用无向图参数化道路布局,展示大规模城市道路拓扑的卓越性能。
自治学习地图表达: 基于栅格化的地图表示已被广泛使用。[14,12,10]将地图元素(道路、人行横道)栅格化为图层,并用不同颜色对车道方向进行编码。[3,8]在光栅化鸟瞰图像中对路线图、交通灯和限速进行编码。[23]在自上而下的空间网格中对静态实体、动态实体和语义地图信息的历史进行编码。HDNet[38]利用道路遮罩作为输入功能来提高目标检测性能。光栅化地图已与激光雷达点云融合,以执行联合感知和预测[29,4,27]以及端到端运动规划[40,35,41]。虽然光栅地图表示法很流行,但另一种方法是使用矢量化地图要素。[9] 使用沿中心线的距离和与中心线的偏移作为最近邻回归和LSTM[20]模型的输入。[34,1]使用1D CNN和LSTM对车道特征进行编码。相比之下,我们的模型从矢量化的地图数据中构建了一个车
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2186
2186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









