







Boosting Tree

xgboost原理? - 和鲸社区Kesci的回答 - 知乎
https://www.zhihu.com/question/58883125/answer/554373500
可以看出,boosting tree 的基本思想是拟合残差。
设
f
(
x
)
f(x)
f(x)为强学习器,
h
(
x
)
h(x)
h(x)为弱学习器:
前一轮得到的强学习器是
f
t
−
1
(
x
)
f_{t-1}(x)
ft−1(x),损失函数是
L
(
y
,
f
t
−
1
(
x
)
)
L\left(y, f_{t-1}(x)\right)
L(y,ft−1(x))
本轮迭代的目标是找到一个弱学习器
h
t
(
x
)
h_{t}(x)
ht(x),来最小化本轮的损失
L
(
y
,
f
t
(
x
)
)
=
L
(
y
,
f
t
−
1
(
x
)
+
h
t
(
x
)
)
L\left(y, f_{t}(x)\right)=L\left(y, f_{t-1}(x)+h_{t}(x)\right)
L(y,ft(x))=L(y,ft−1(x)+ht(x))
当采用平方损失函数时:
L
(
y
,
f
t
−
1
(
x
)
+
h
t
(
x
)
)
=
(
y
−
f
t
−
1
(
x
)
−
h
t
(
x
)
)
2
=
(
r
−
h
t
(
x
)
)
2
\begin{array}{c} L\left(y, f_{t-1}(x)+h_{t}(x)\right) \\ =\left(y-f_{t-1}(x)-h_{t}(x)\right)^{2} \\ =\left(r-h_{t}(x)\right)^{2} \end{array}
L(y,ft−1(x)+ht(x))=(y−ft−1(x)−ht(x))2=(r−ht(x))2
这里,
r
=
y
−
f
t
−
1
(
x
)
r=y-f_{t-1}(x)
r=y−ft−1(x)即
r
r
r是当前模型拟合数据的残差(residual),所有提升树只需要单纯拟合模型的残差。
流程
a. 初始化
f
0
(
x
)
=
0
f_{0}(x)=0
f0(x)=0
b. 对于
m
=
1
,
2
,
…
M
m=1,2, \ldots M
m=1,2,…M
- 计算残差
r m i = y i − f m − 1 ( x ) , i = 1 , 2 , … , N r_{m i}=y_{i}-f_{m-1}(x), i=1,2, \ldots, N rmi=yi−fm−1(x),i=1,2,…,N
-
拟合残差 r m i r_{m i} rmi 学习一个回归树,得到 h m ( x ) h_{m}(x) hm(x):
-
更新 f m ( x ) = f m − 1 + h m ( x ) f_{m}(x)=f_{m-1}+h_{m}(x) fm(x)=fm−1+hm(x)
c. 得到回归问题的提升树
f
M
(
x
)
=
∑
m
=
1
M
h
m
(
x
)
f_{M}(x)=\sum_{m=1}^{M} h_{m}(x)
fM(x)=m=1∑Mhm(x)
上式
m
m
m为决策树编号,
M
M
M 为决策树的数量.
GBDT(梯度提升树)Gradient Boosting Decision Tree
GBDT使用的决策树为CART回归树,因为GBDT每次迭代要拟合的是梯度值,是连续值。
梯度提升树算法,利用损失函数的负梯度作为提升树算法中残差的近似值。
对于平方损失
L
(
y
i
,
f
(
x
i
)
)
=
1
2
(
y
i
−
f
(
x
i
)
)
2
L\left(y_{i}, f\left(x_{i}\right)\right)=\frac{1}{2}\left(y_{i}-f\left(x_{i}\right)\right)^{2}
L(yi,f(xi))=21(yi−f(xi))2
第 t 轮的第 i 个样本的损失函数负梯度为:
r
t
i
=
−
[
∂
L
(
y
i
,
f
(
x
i
)
)
∂
f
(
x
i
)
]
f
=
f
t
−
1
=
y
i
−
f
(
x
i
)
r_{t i}=-\left[\frac{\partial L\left(y_{i}, f\left(x_{i}\right)\right)}{\partial f\left(x_{i}\right)}\right]_{f=f_{t-1}}=y_i - f(x_i)
rti=−[∂f(xi)∂L(yi,f(xi))]f=ft−1=yi−f(xi)
即此时GBDT的负梯度就是残差,即要拟合的就是残差。
引申与证明
对于其他损失函数,其负梯度展开后不一定含有残差,即无法对残差进行拟合。
对于Boosting Tree来说,下一阶段的弱分类器要拟合的就是残差,而应用平方损失函数的GBDT的负梯度就等于残差,那么“推广一下”,对于应用其他损失函数的GBDT,也去拟合损失函数负梯度。
推导:
目标函数:
max
[
(
L
(
y
,
Σ
j
=
1
t
f
j
(
x
)
)
−
L
(
y
,
Σ
j
=
1
t
f
j
(
x
)
+
f
t
+
1
(
x
)
)
)
]
\max \left[\left(L\left(y, \Sigma_{j=1}^{t} f_{j}(x)\right)-L\left(y, \Sigma_{j=1}^{t} f_{j}(x)+f_{t+1}(x)\right)\right)\right]
max[(L(y,Σj=1tfj(x))−L(y,Σj=1tfj(x)+ft+1(x)))]
令
c
=
Σ
j
=
1
t
f
j
(
x
)
c=\Sigma_{j=1}^{t} f_{j}(x)
c=Σj=1tfj(x), 即
max
[
L
(
y
,
c
)
−
L
(
y
,
c
+
f
t
+
1
(
x
)
)
]
\max \left[L(y, c)-L\left(y, c+f_{t+1}(x)\right)\right]
max[L(y,c)−L(y,c+ft+1(x))]
根据泰勒公式:
L
(
c
+
f
t
+
1
(
x
)
)
≈
L
(
c
)
+
L
′
(
c
)
f
t
+
1
(
x
)
L\left(c+f_{t+1}(x)\right) \approx L(c)+L^{\prime}(c) f_{t+1}(x)
L(c+ft+1(x))≈L(c)+L′(c)ft+1(x)
根据目标函数,得
L
(
c
+
f
t
+
1
(
x
)
)
=
L
(
c
)
+
L
′
(
c
)
f
t
+
1
(
x
)
<
L
(
c
)
L\left(c+f_{t+1}(x)\right)=L(c)+L^{\prime}(c) f_{t+1}(x)<L(c)
L(c+ft+1(x))=L(c)+L′(c)ft+1(x)<L(c)
为保证不等式恒成立,令
f
t
+
1
(
x
)
=
−
1
∗
L
′
(
x
)
f_{t+1}(x)=-1 * L^{\prime}(x)
ft+1(x)=−1∗L′(x),此时:
L
(
c
)
+
L
′
(
c
)
f
t
+
1
(
x
)
=
L
(
c
)
−
L
′
(
c
)
2
<
L
(
c
)
L(c)+L^{\prime}(c) f_{t+1}(x)=L(c)-L^{\prime}(c)^{2}<L(c)
L(c)+L′(c)ft+1(x)=L(c)−L′(c)2<L(c)
综上得, f t + 1 ( x ) = − 1 ∗ L ′ ( x ) f_{t+1}(x)=-1 * L^{\prime}(x) ft+1(x)=−1∗L′(x),证明了梯度提升树算法是利用损失函数的负梯度作为提升树算法中残差的近似值。
流程
a. 初始化弱学习器
f
0
(
x
)
=
arg
min
c
∑
i
=
1
N
L
(
y
i
,
c
)
f_{0}(x)=\arg \min _{c} \sum_{i=1}^{N} L\left(y_{i}, c\right)
f0(x)=argminc∑i=1NL(yi,c)
b. 对
m
=
1
,
2
,
…
M
m=1,2, \ldots M
m=1,2,…M 有:
- 对每个样本
i
=
1
,
2
,
…
N
i=1,2, \ldots N
i=1,2,…N,计算负梯度,即残差
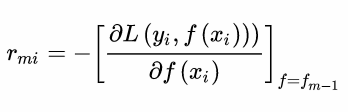
- 将上一步得到的残差作为样本新的真实值,并将数据 ( x i , r m i ) , i = 1 , 2 , … N (x_i, r_{mi}), i=1,2, \ldots N (xi,rmi),i=1,2,…N 作为下棵树的训练数据,得到一颗新的回归树 f m ( x ) f_m(x) fm(x),其对应的叶子节点区域为 R j m , j = 1 , 2 , … J R_{jm}, j=1,2, \ldots J Rjm,j=1,2,…J, 其中 J J J为回归树t的叶子节点的个数。
- 对叶子区域
j
=
1
,
2
,
…
J
j=1,2, \ldots J
j=1,2,…J计算最佳拟合值
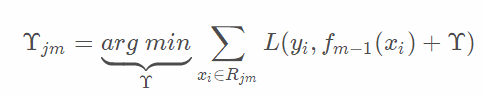
- 更新强学习器
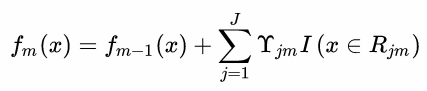
c. 得到最终学习器
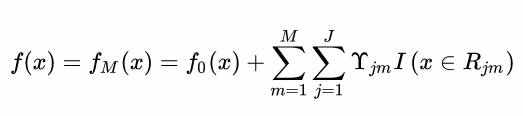
优点:
- 精度高
- 能处理非线性数据
- 能处理多特征类型
- 适合低维稠密数据
- 模型可解释性好
- 不需要做特征的归一化,可以自动选择特征
- 能适应多种损失函数
缺点:
- 不太适合并发执行
- 计算复杂度高
- 不适用高维稀疏特征
考点
训练过程
GBDT通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的残差来达到将数据分类或者回归的一种boosting 算法。
通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。一般选择cart tree且树的深度不会很深。
gbdt 的 gb的核心:让损失函数沿着梯度方向的下降。 利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值去拟合一个回归树。gbdt 每轮迭代的时候,都去拟合损失函数在当前模型下的负梯度。
这样每轮训练的时候都能够让损失函数尽可能快的减小,尽快的收敛达到局部最优解或者全局最优解。
弱分类器低方差和高偏差的原因
boosting中每个模型是弱模型,偏差bias高,方差variance低。
目标是通过平均降低偏差(bias)。
boosting的基本思想就是用贪心法最小化损失函数,显然能降低偏差,但是通常模型的相关性很强,因此不能显著降低variance。
典型的Boosting是Adaboost,另外一个常用的并行Boosting算法是GBDT(gradient boosting decision tree)。这一类算法通常不容易出现过拟合。
选择特征
即CART Tree生成的过程。这里有一个前提,gbdt的弱分类器默认选择的是CART TREE。其实也可以选择其他弱分类器的,选择的前提是低方差和高偏差。框架服从boosting 框架即可。
CART TREE 生成的过程其实就是一个选择特征的过程。假设我们目前总共有 M 个特征。第一步我们需要从中选择出一个特征 j,做为二叉树的第一个节点。然后对特征 j 的值选择一个切分点 m. 一个 样本的特征j的值 如果小于m,则分为一类,如果大于m,则分为另外一类。如此便构建了CART 树的一个节点。其他节点的生成过程和这个是一样的。
原始的gbdt的做法非常的暴力,首先遍历每个特征,然后对每个特征遍历它所有可能的切分点,找到最优特征 m 的最优切分点 j。
具体参见CART与ID3、C4.5决策树
构建特征
gbdt 本身是不能产生特征的,但是我们可以利用gbdt去产生特征的组合。在CTR预估中,工业界一般会采用逻辑回归去进行处理, 逻辑回归本身是适合处理线性可分的数据,如果我们想让逻辑回归处理非线性的数据,其中一种方式便是组合不同特征,增强逻辑回归对非线性分布的拟合能力。
Facebook 在2014年 发表的一篇论文,利用gbdt去产生有效的特征组合,以便用于逻辑回归的训练,提升模型最终的效果。

如图 所示,我们 使用 GBDT 生成了两棵树,两颗树一共有五个叶子节点。我们将样本 X 输入到两颗树当中去,样本X 落在了第一棵树的第二个叶子节点,第二颗树的第一个叶子节点,于是我们便可以依次构建一个五纬的特征向量,每一个纬度代表了一个叶子节点,样本落在这个叶子节点上面的话那么值为1,没有落在该叶子节点的话,那么值为 0.
于是对于该样本,我们可以得到一个向量[0,1,0,1,0] 作为该样本的组合特征,和原来的特征一起输入到逻辑回归当中进行训练。实验证明这样会得到比较显著的效果提升
分类任务
gbdt 无论用于分类还是回归一直都是使用的CART 回归树。不会因为我们所选择的任务是分类任务就选用分类树,这里面的核心是因为gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练的。这里的残差就是当前模型的负梯度值 。这个要求每轮迭代的时候,弱分类器的输出的结果相减是有意义的。残差相减是有意义的,类别相减是没有意义的。
我们具体到分类这个任务上面来,我们假设样本 X 总共有 K类。来了一个样本 x,我们需要使用gbdt来判断 x 属于样本的哪一类。
-
第一步 我们在训练的时候,是针对样本 X 每个可能的类都训练一个分类回归树。举例说明,目前样本有三类,也就是 K = 3。样本 x 属于 第二类。那么针对该样本 x 的分类结果,其实我们可以用一个 三维向量 [0,1,0] 来表示。0表示样本不属于该类,1表示样本属于该类。由于样本已经属于第二类了,所以第二类对应的向量维度为1,其他位置为0。
针对样本有 三类的情况,我们实质上是在每轮的训练的时候是同时训练三颗树。第一颗树针对样本x的第一类,输入为(x,0)。第二颗树输入针对 样本x 的第二类,输入为(x,1)。第三颗树针对样本x 的第三类,输入为(x,0)。
-
每颗树的训练过程就是CATR TREE 的生成过程。得到三棵树对x 类别的预测值f1(x),f2(x),f3(x)。那么在此类训练中,我们仿照多分类的逻辑回归 ,使用softmax 来产生概率,则属于类别 1 的概率为p1=exp(f1(x))/∑k
-
分别对三棵树求残差,并用残差代替下一轮输入的y值
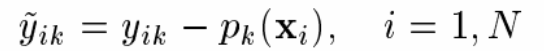
-
开始下一轮训练,用新输入拟合出三棵弱分类树,反复训练M轮,得到最终分类器。















 4180
4180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









