







CG-solver
https://github.com/stovorov/ConjugateGradients
一、main的整体流程
1. 输入配置
位于solver.c中
printf("Conjugate Gradient solver using MKL.\n");
InputConfig *input_cfg;
input_cfg = arg_parser(argc, argv);
printf("Num of threads: %d\n", input_cfg->num_of_threads);
omp_set_num_threads(input_cfg->num_of_threads);
> InputConfig数据结构与实现
位于utils.h与.c
typedef struct{
char *filename;
int num_of_threads;
int gpu;
char *preconditioner;
} InputConfig;
InputConfig* arg_parser(int argc, char **argv){
/*Parse argument line*/
InputConfig *input_cfg = (InputConfig *)malloc(sizeof(InputConfig));
input_cfg->num_of_threads = 1;
input_cfg->gpu = 0;
input_cfg->filename = NULL;
input_cfg->preconditioner = NULL;
int mt = 0;
int fil_flag = 0;
for (int i = 0; i < argc; i++){
if (mt)
input_cfg->num_of_threads = atoi(argv[i]);
mt = 0;
if (strcmp(argv[i], "-mt") == 0)
mt = 1;
if (fil_flag)
input_cfg->filename = argv[i];
fil_flag = 0;
if (strcmp(argv[i], "-i") == 0)
fil_flag = 1;
if (strcmp(argv[i], "--pcg_jacobi") == 0)
input_cfg->preconditioner = "jacobi";
if (strcmp(argv[i], "--gpu") == 0)
input_cfg->gpu = 1;
}
return input_cfg;
}
2. 数据输入
Matrix *matrix;
matrix = getMatrixCRS(input_cfg);
if (matrix == NULL){
printf("ERROR - could not read matrix, exiting.\n");
FREE_STACK_COMMON;
exit(1);
}
printf("Matrix parameters:\n");
printf("Size = %d, non-zero elements = %d\n", (int)matrix->size, (int)matrix->non_zero);
> Matrix数据结构与数据读取
简单介绍一下CSR的存储算法,有一个稀疏矩阵A,把A的非零元素存在val数组里,然后把A的每行开头的非零元素在val的位置保存在I_column里面,I_column最后一个元素是非零元素的个数;把A的非零元素的列标存在J_row里。其中m代表的是A的行。
假如,A是一个 2 ∗ 3 2*3 2∗3的矩阵,记成 A = [ 1 , 2 , 3 ; 4 , 5 , 6 ] A=[1 ,2, 3;4 ,5, 6] A=[1,2,3;4,5,6]。把A转化成CSR的形式来进行存储,那么 val=[1 2 3 4 5 6], 而 I_column=[0 3 6], J_row= [0 1 2 0 1 2].
https://blog.csdn.net/qq_44032245/article/details/102673960
typedef struct {
MKL_INT size;
MKL_INT non_zero;
MKL_INT *I_column;
MKL_INT *J_row;
double *val;
}Matrix;
包括 行数、非零个数、I_column(长度比行数+1的MKL_INT向量,存行偏移量)、J_row(长度与non_zero相同的MKL_INT向量,存放非零数的列标)、val(长度与non_zero相同的double向量,存放非零数)
Matrix* getMatrixCRS(InputConfig *input_cfg){
/* Load Matrix stored in CSR format from file.*/
char *fil_name;
fil_name = input_cfg->filename;
if (fil_name == NULL)
return NULL;
FILE *pf;
pf = fopen(fil_name, "r");
if(pf == NULL){
printf("Can't open the file: %s", fil_name);
}
double v;
int c, non_zero, inx;
int matsize, max_rows;
// Load first line of file with information about size and non zero element in matrix
fscanf(pf,"%d %d %d", &matsize, &non_zero, &max_rows);
Matrix *matrix = (Matrix *)malloc(sizeof(Matrix));
matrix->size = matsize;
matrix->non_zero = non_zero;
matrix->I_column = (MKL_INT *)mkl_malloc((matsize + 1) * sizeof(MKL_INT), 64);
matrix->J_row = (MKL_INT *)mkl_malloc(non_zero * sizeof(MKL_INT), 64 );
matrix->val = (double *)mkl_malloc(non_zero * sizeof(double), 64);
int n = 0;
while( ! feof(pf)){
if(n < matsize + 1){
fscanf(pf, "%le %d %d", &v, &c, &inx);
matrix->val[n] = v;
matrix->J_row[n] = c;
matrix->I_column[n] = inx;
}
else{
fscanf(pf, "%le %d", &v, &c);
matrix->val[n] = v;
matrix->J_row[n] = c;
}
n++;
}
fclose(pf);
pf = NULL;
return matrix;
}
其中下面代码解释了结构体含义:
matrix->size = matsize;
matrix->non_zero = non_zero;
matrix->I_column = (MKL_INT *)mkl_malloc((matsize + 1) * sizeof(MKL_INT), 64);
matrix->J_row = (MKL_INT *)mkl_malloc(non_zero * sizeof(MKL_INT), 64 );
matrix->val = (double *)mkl_malloc(non_zero * sizeof(double), 64);
int n = 0;
while( ! feof(pf)){
if(n < matsize + 1){
fscanf(pf, "%le %d %d", &v, &c, &inx);
matrix->val[n] = v;
matrix->J_row[n] = c;
matrix->I_column[n] = inx;
}
else{
fscanf(pf, "%le %d", &v, &c);
matrix->val[n] = v;
matrix->J_row[n] = c;
}
n++;
}
3. 数据准备
double *x_vec, *b_vec, *res_vec;
x_vec = (double *)mkl_malloc(matrix->size * sizeof(double), 64);
b_vec = (double *)mkl_malloc(matrix->size * sizeof(double), 64);
res_vec = (double *)mkl_malloc(matrix->size * sizeof(double), 64);
for (int i = 0; i < matrix->size; i++) {
x_vec[i] = 1;
b_vec[i] = 0;
res_vec[i] = 0;
}
int total_iter = 0;
double t_start, t_stop;
生成三个double向量*x_vec, *b_vec, *res_vec,长度与matrix尺寸相同
4. 求解
t_start = get_time();
total_iter = launch_solver(matrix, x_vec, b_vec, res_vec, input_cfg);
t_stop = get_time();
printf("Conjugate gradient method finished within %.3f [secs] in total %d iterations.\n", t_stop - t_start, total_iter);
FREE_STACK_ALL;
exit(0);
> launch_solver(matrix, x_vec, b_vec, res_vec, input_cfg);
位于utils.c
4.1 GPU信息读取
/*Launch proper solver based on input config data.*/
GPU_data *gpu_data; //gpu information
gpu_data = get_gpu_devices_data();
GPU_data数据结构与读取
位于gpu_utils.h 与.c
typedef struct {
char *name;
int warp_size;
int max_threads_per_block;
int clock_rate;
int multiprocessors_number;
const char *kernel_execution_timeout;
unsigned int total_global_memory;
unsigned int total_shared_memory_per_block;
} GPU_device;
typedef struct {
int devices_number;
GPU_device *devices;
} GPU_data;
GPU_data *get_gpu_devices_data(){
/*Get information about CUDA devices on host.*/
GPU_data *gpu_data;
gpu_data = (GPU_data *)malloc(sizeof(GPU_data));
gpu_data->devices_number = 0;
cudaError_t device_error;
device_error = cudaGetDeviceCount(&gpu_data->devices_number);
if (device_error != cudaSuccess)
printf("Error - could not read properly number of device, err=[%s] \n", cudaGetErrorString(device_error));
if (gpu_data->devices_number != 0){
gpu_data->devices = (GPU_device *)malloc(gpu_data->devices_number * sizeof(GPU_device));
for (int i = 0; i < gpu_data->devices_number; i ++){
cudaDeviceProp devProp;
cudaGetDeviceProperties(&devProp, i);
gpu_data->devices[i].name = devProp.name;
gpu_data->devices[i].warp_size = devProp.warpSize;
gpu_data->devices[i].max_threads_per_block = devProp.maxThreadsPerBlock;
gpu_data->devices[i].clock_rate = devProp.clockRate;
gpu_data->devices[i].multiprocessors_number = devProp.multiProcessorCount;
gpu_data->devices[i].kernel_execution_timeout = (devProp.kernelExecTimeoutEnabled ? "Yes" : "No");
gpu_data->devices[i].total_global_memory = devProp.totalGlobalMem;
gpu_data->devices[i].total_shared_memory_per_block = devProp.sharedMemPerBlock;
}
}
return gpu_data;
}
4.2 GPU设备上的求解
int total_iter = 0;
if (gpu_data->devices_number > 0 && input_cfg->gpu == 1){
printf("Launching GPU CG.\n");
printf("Number of CUDA devices: %d\n", gpu_data->devices_number);
cudaDeviceReset();
total_iter = gpu_conjugate_gradient_solver(matrix, x_vec, b_vec, res_vec, gpu_data);
}
else {
//
}
free(gpu_data);
return total_iter;
> total_iter = gpu_conjugate_gradient_solver(matrix, x_vec, b_vec, res_vec, gpu_data);
位于cg_colver_gpu.cu
详见下节
4.3 CPU设备上的求解
int total_iter = 0;
if (gpu_data->devices_number > 0 && input_cfg->gpu == 1){
//
}
else {
if (input_cfg->preconditioner == NULL){
printf("Launching CPU CG.\n");
total_iter = conjugate_gradient_solver(matrix, x_vec, b_vec, res_vec);
} else {
printf("Launching CPU PCG with %s preconditioner.\n", input_cfg->preconditioner);
total_iter = pcg_solver(matrix, x_vec, b_vec, res_vec, input_cfg->preconditioner);
}
}
free(gpu_data);
return total_iter;
> total_iter = conjugate_gradient_solver(matrix, x_vec, b_vec, res_vec);
位于cg_solver.c
详见下节
二、GPU与CPU的实现
完全调库,与流程一致
> total_iter = conjugate_gradient_solver(matrix, x_vec, b_vec, res_vec);

1. 数据准备
int k, max_iter;
double beta, tol, alpha, dTq, dot_zero, dot_new, dot_old;
double *Ax, *x, *d, *q;
k = 0;
beta = 0.0;
tol = 1e-2f;
max_iter = 200;
d = (double *)mkl_malloc(matrix->size * sizeof(double), 64);
x = (double *)mkl_malloc(matrix->size * sizeof(double), 64);
q = (double *)mkl_malloc(matrix->size * sizeof(double), 64);
Ax = (double *)mkl_malloc(matrix->size * sizeof(double), 64);
Ax表示 A x Ax Ax,rhs表示误差(初值为b),k是迭代次数,
2. 初始化
Ax = A x Ax Ax
rhs = rhs-Ax= b − A x b-Ax b−Ax
d = rhs
dot_new = r h s T r h s rhs^T rhs rhsTrhs
dot_zero = dot_new;
/*Calculate Ax matrix*/
mkl_cspblas_dcsrgemv("N", &(matrix->size), matrix->val, matrix->I_column, matrix->J_row, x_vec, Ax);
/*Calculate rhs=rhs-Ax matrix*/
cblas_daxpy(matrix->size, -1.0, Ax, 1 , rhs, 1);
/*CG: Copy updated rhs (residuum) to d vector*/
cblas_dcopy(matrix->size, rhs, 1, d, 1);
/*CG: calculate dot r'*r, assign it to dot_new */
dot_new = cblas_ddot(matrix->size, rhs, 1 ,rhs, 1);
/*assign dot_new to dot_zero*/
dot_zero = dot_new;
3. 迭代
循环体中流程基本与下图一致
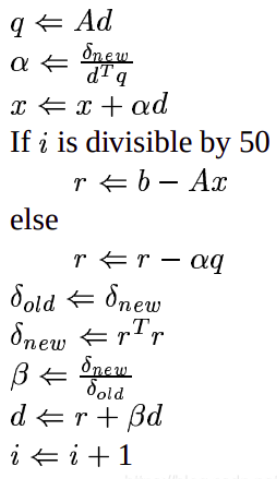
while (dot_new > tol * tol * dot_zero && k < max_iter) {
/*Calculate q=A*d vector*/
mkl_cspblas_dcsrgemv("N", &(matrix->size), matrix->val, matrix->I_column, matrix->J_row, d, q);
/*Calculate alpha:*/
dTq = cblas_ddot(matrix->size, d, 1, q, 1);
alpha = dot_new / dTq;
/*Calculate x=x+alpha*d*/
cblas_daxpy(matrix->size, alpha, d, 1, x, 1);
/*Calculate r=r-alpha*q*/
cblas_daxpy(matrix->size, (-1) * alpha, q, 1, rhs, 1);
/*Assign dot_old = dot_new*/
dot_old = dot_new;
/*CG:Assign dot_new = r'*r*/
dot_new = cblas_ddot(matrix->size, rhs, 1, rhs, 1);
beta = dot_new / dot_old;
/*Scale beta*d*/
cblas_dscal(matrix->size, beta, d, 1);
/*CG:Calculate d=r+beta*d*/
cblas_daxpy(matrix->size, 1.0, rhs, 1, d, 1);
k++;
}
FREE_STACK;
return k;
> total_iter = gpu_conjugate_gradient_solver(matrix, x_vec, b_vec, res_vec, gpu_data);
1.数据准备
/*Single GPU CG solver using cublas*/
double *h_dot, *h_dot_zero;
int *d_I = NULL, *d_J = NULL;
const double tol = 1e-2f;
double *d_alfa, *d_beta, *d_alpha_zero;
double *d_Ax, *d_x, *d_d, *d_q, *d_rhs, *d_r, *d_helper, *d_norm, *d_dot_new, *d_dot_zero, *d_dot_old, *d_dTq, *d_val;
int k, max_iter;
k = 0;
h_dot = 0;
h_dot_zero = 0;
max_iter = 200;
size_t size = matrix->size * sizeof(double);
size_t d_size = sizeof(double);
cusparseHandle_t cusparseHandle = 0;
cusparseCreate(&cusparseHandle);
cusparseMatDescr_t descr = 0;
cusparseCreateMatDescr(&descr);
cublasHandle_t cublasHandle = 0;
cublasCreate(&cublasHandle);
cusparseSetMatType(descr, CUSPARSE_MATRIX_TYPE_GENERAL);
cusparseSetMatIndexBase(descr, CUSPARSE_INDEX_BASE_ZERO);
cublasStatus_t cublasStatus;
printf("Mallocing CUDA divice memory\n");
cudaMalloc((void **)&d_r, size);
cudaMalloc((void **)&d_helper, size);
cudaMalloc((void **)&d_x, size);
cudaMalloc((void **)&d_rhs, size);
cudaMalloc((void **)&d_d, size);
cudaMalloc((void **)&d_Ax, size);
cudaMalloc((void **)&d_q, size);
cudaMalloc((void **)&d_val, matrix->non_zero * sizeof(double));
cudaMalloc((void **)&d_J, matrix->non_zero * sizeof(int));
cudaMalloc((void **)&d_I, (matrix->size + 1) * sizeof(int));
cudaMalloc((void **)&d_beta, d_size);
cudaMalloc((void **)&d_alfa, d_size);
cudaMalloc((void **)&d_alpha_zero, d_size);
cudaMalloc((void **)&d_dot_new, d_size);
cudaMalloc((void **)&d_dot_zero, d_size);
cudaMalloc((void **)&d_norm, d_size);
cudaMemset(d_beta, 0, d_size);
cudaMemset(d_alfa, 0, d_size);
cudaMemset(d_alpha_zero, 0, d_size);
cudaMemset(d_dot_new, 0, d_size);
cudaMemset(d_dot_zero, 0, d_size);
cudaMemset(d_norm, 0, d_size);
printf("Copying to device\n");
cudaMemcpy(d_val, matrix->val, matrix->non_zero * sizeof(double), cudaMemcpyHostToDevice);
cudaMemcpy(d_J, matrix->J_row, matrix->non_zero * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_I, matrix->I_column, (matrix->size + 1) * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_x, x_vec, size, cudaMemcpyHostToDevice);
2.初始化
int blocksPerGrid = ((matrix->size + threadsPerBlock - 1) / threadsPerBlock );
while (blocksPerGrid % threadsPerBlock != 0){
blocksPerGrid++;
}
double alpha = 1.0;
double beta = 0.0;
const double one = 1.0;
const double minus_one = -1.0;
/*Calculate Ax matrix*/
cusparseDcsrmv(cusparseHandle, CUSPARSE_OPERATION_NON_TRANSPOSE, matrix->size, matrix->size, matrix->non_zero,
&alpha, descr, d_val, d_J, d_I, d_x, &beta, d_Ax);
/*Calculate rhs=rhs-Ax matrix*/
cublasStatus = cublasDaxpy(cublasHandle, matrix->size, &minus_one, d_Ax, 1, d_rhs, 1);
CHECK_FOR_STATUS(cublasStatus);
/*CG: Copy updated rhs (residuum) to d vector*/
cublasStatus = cublasDcopy(cublasHandle, matrix->size, d_d, 1, d_rhs, 1);
CHECK_FOR_STATUS(cublasStatus);
/*CG: calculate dot r'*r, assign it to d_dot_new */
cublasStatus = cublasDdot(cublasHandle, matrix->size, d_rhs, 1, d_rhs, 1, d_dot_new);
CHECK_FOR_STATUS(cublasStatus);
/*assign dot_new to dot_zero*/
d_dot_zero = d_dot_new;
cudaMemcpy(h_dot, d_dot_new, sizeof(double), cudaMemcpyDeviceToHost);
cudaMemcpy(h_dot_zero, d_dot_zero, sizeof(double), cudaMemcpyDeviceToHost);
3. 迭代
while ((*h_dot > tol * tol * *h_dot_zero) && (k < max_iter)) {
/*Calculate q=A*d vector*/
cusparseDcsrmv(cusparseHandle, CUSPARSE_OPERATION_NON_TRANSPOSE, matrix->size, matrix->size, matrix->non_zero,
&alpha, descr, d_val, d_J, d_I, d_x, &beta, d_Ax);
/*Calculate alpha:*/
cublasStatus = cublasDdot(cublasHandle, matrix->size, d_d, 1, d_q, 1, d_dTq);
CHECK_FOR_STATUS(cublasStatus);
sDdiv<<<1, gpu_data->devices[0].warp_size>>>(d_alfa, d_dot_new, d_dTq);
/*Calculate x=x+alpha*d*/
cublasStatus = cublasDaxpy(cublasHandle, matrix->size, d_alfa, d_x, 1, d_d, 1);
CHECK_FOR_STATUS(cublasStatus);
/*Calculate r=r-alpha*q*/
axpy<<<blocksPerGrid, threadsPerBlock>>>(matrix->size, -1, d_q, d_rhs);
/*Assign dot_old = dot_new*/
cublasStatus = cublasDcopy(cublasHandle, 1, d_dot_old, 1, d_dot_new, 1);
CHECK_FOR_STATUS(cublasStatus);
/*CG:Assign dot_new = r'*r*/
cublasStatus = cublasDdot(cublasHandle, matrix->size, d_rhs, 1, d_rhs, 1, d_dot_new);
CHECK_FOR_STATUS(cublasStatus);
sDdiv<<<1, gpu_data->devices[0].warp_size>>>(d_beta, d_dot_new, d_dot_old);
/*Scale beta*d*/
cublasStatus = cublasDscal(cublasHandle, matrix->size, d_beta, d_d, 1);
CHECK_FOR_STATUS(cublasStatus);
/*CG:Calculate d=r+beta*d*/
cublasStatus = cublasDaxpy(cublasHandle, matrix->size, &one, d_rhs, 1, d_d, 1);
CHECK_FOR_STATUS(cublasStatus);
k++;
}
cusparseDestroy(cusparseHandle);
cudaDeviceReset();
FREE_DEVICE_STACK
return k;















 868
868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









