







ISO 26262标准对潜伏故障的定义
Latent Fault : multiple-point fault whose presence is not detected by a safety mechanism nor perceived by the driver within the multiple-point fault detection time interval.
从定义来看,潜伏故障是一个多点故障,它的出现,在多点故障探测时间间隔内,没有被安全机制探测到,也没有被驾驶员感知到。
在芯片设计中,以LDO为例,为LDO的输入增加了过压/欠压的安全机制,该安全机制形成的单点故障不会违反安全目标,但是如果此时,发生了过压/欠压,而安全机制没有检测到该故障,则形成了潜伏故障。在该过程中,可以认为潜伏故障本身并没有违反安全目标,而当另一个独立的硬件故障发生,即发生了过压/欠压,LDO输出违反了安全目标。
最后回顾一下哈
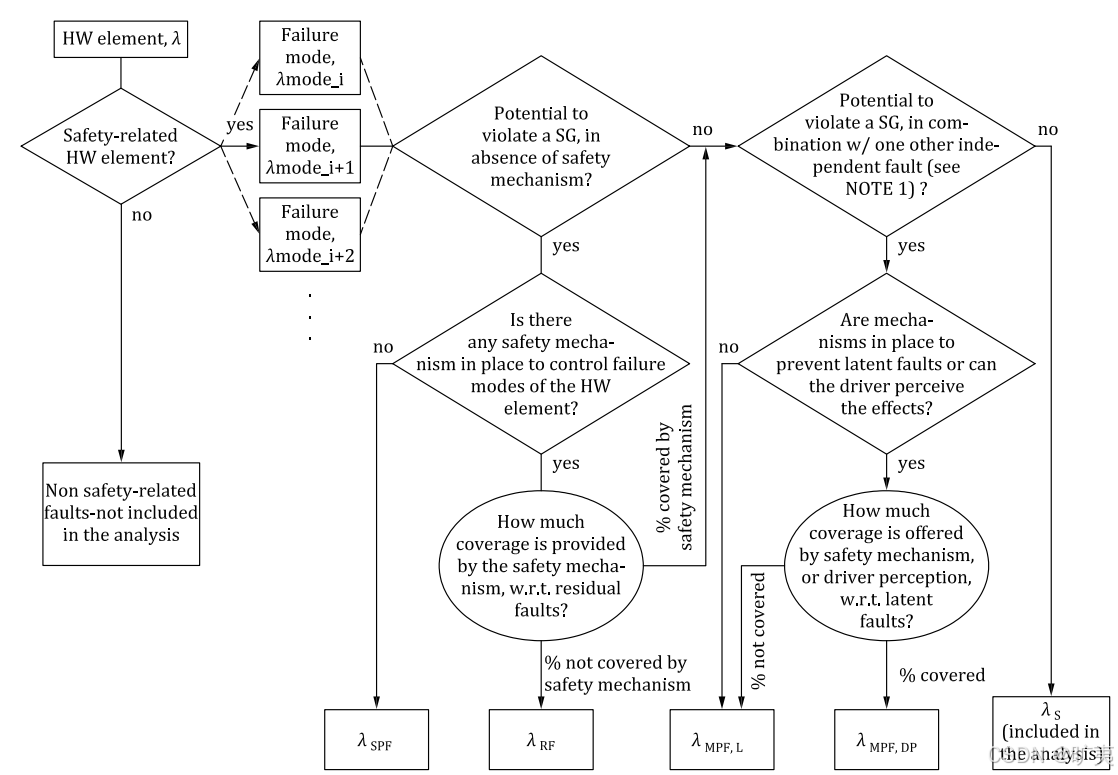
如果一个硬件模块,存在失效模式直接违反安全目标,如果没有安全机制检测,则直接形成单点故障,如果存在安全机制(诊断覆盖率),没有被安全机制覆盖的形成残余故障,被安全机制覆盖的部分,与其它独立的失效组合导致违反安全目标时,进一步考虑该多点故障是否能够被安全机制检测,如果不能够检测或感知,则形成潜伏故障。

















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









