







 QPLEX是一种用于多智能体强化学习的算法,它采用双层 Dueling 网络结构,通过分解联合动作价值函数为个体动作价值和优势函数,确保了 Individual-Global-Max (IGM) 原则的一致性。这种方法允许在不牺牲表达能力的情况下进行有效的学习。QPLEX通过Transformer网络将全局信息融入个体智能体的决策过程,以实现更好的协作和决策。在星际争霸2的实验中,QPLEX表现出了优越的性能,超越了其他算法。
QPLEX是一种用于多智能体强化学习的算法,它采用双层 Dueling 网络结构,通过分解联合动作价值函数为个体动作价值和优势函数,确保了 Individual-Global-Max (IGM) 原则的一致性。这种方法允许在不牺牲表达能力的情况下进行有效的学习。QPLEX通过Transformer网络将全局信息融入个体智能体的决策过程,以实现更好的协作和决策。在星际争霸2的实验中,QPLEX表现出了优越的性能,超越了其他算法。
多智能体强化学习—QPLEX
论文地址:QPLEX: Duplex Dueling Multi-Agent Q-Learning
视频效果:Experiments on StarCraft II
建议了解一下QMIX:多智能体强化学习—QMIX
1 介绍
IGM(Individual-Global-Max):
argmax
u
Q
t
o
t
(
τ
,
u
)
=
(
argmax
u
1
Q
1
(
τ
1
,
u
1
)
⋮
argmax
u
n
Q
n
(
τ
n
,
u
n
)
)
\underset{\mathbf{u}}{\operatorname{argmax}} Q_{t o t}(\tau, \mathbf{u})=\left(\begin{array}{cc} \operatorname{argmax}_{u^{1}} & Q_{1}\left(\tau^{1}, u^{1}\right) \\ \vdots \\ {\operatorname{argmax}}_{u^{n}} & Q_{n}\left(\tau^{n}, u^{n}\right) \end{array}\right)
uargmaxQtot(τ,u)=⎝⎜⎛argmaxu1⋮argmaxunQ1(τ1,u1)Qn(τn,un)⎠⎟⎞
其中,
Q
t
o
t
Q_{tot}
Qtot表示联合Q函数;
Q
i
Q_i
Qi表示智能体 i的动作值函数。
IGM表示
a
r
g
m
a
x
(
Q
t
o
t
)
argmax (Q_{tot})
argmax(Qtot) 与
a
r
g
m
a
x
(
Q
i
)
argmax (Q_i)
argmax(Qi)得到相同结果,这表示在无约束条件的情况下,个体最优就代表整体最优。
QPLEX:QMIX和VDN提出了IGM的两个充分条件(下式)来因式分解联合动作值函数。这两种分解方法都受到结构约束,并限制了它们可以表示的联合动作值函数类。
Q
t
o
t
V
D
N
(
τ
,
a
)
=
∑
i
=
1
n
Q
i
(
τ
i
,
a
i
)
and
∀
i
∈
N
,
∂
Q
t
o
t
Q
M
I
X
(
τ
,
a
)
∂
Q
i
(
τ
i
,
a
i
)
>
0
Q_{t o t}^{\mathrm{VDN}}(\boldsymbol{\tau}, \boldsymbol{a})=\sum_{i=1}^{n} Q_{i}\left(\tau_{i}, a_{i}\right) \quad \text { and } \quad \forall i \in \mathcal{N}, \frac{\partial Q_{t o t}^{\mathrm{QMIX}}(\boldsymbol{\tau}, \boldsymbol{a})}{\partial Q_{i}\left(\tau_{i}, a_{i}\right)}>0
QtotVDN(τ,a)=i=1∑nQi(τi,ai) and ∀i∈N,∂Qi(τi,ai)∂QtotQMIX(τ,a)>0
为了解决这一挑战,提出了QPLEX,称为duPLEX dueling multi-agent Q-learning-(QPLEX),该方法采用 duplex dueling network 结构将联合动作值函数分解为个体的动作值函数。QPLEX引入了dueling structure:Q=V+A,用于表示联合和个体动作值函数,然后将IGM原则重新形式化为基于优势的IGM。这种重新表述将IGM的一致性转换为对优势函数值范围的约束,从而促进了具有线性分解结构的动作-值函数的学习。QPLEX利用 advantage of a duplex dueling 架构将IGM约束条件编码到神经网络结构中,保证IGM的一致性。
QPLEX的主要亮点:分别对联合Q值
Q
t
o
t
Q_{tot}
Qtot 和各个agent的Q值
Q
i
Q_{i}
Qi 使用Dueling structure:
Q
=
V
+
A
Q=V+A
Q=V+A 进行分解,将IGM一致性转化为易于实现的优势函数取值范围约束,从而方便了具有线性分解结构的值函数的学习,这种分解让Q值的获得更为具体,Q值=当前状态的价值V+采取动作的价值A,这样可以进一步判断Q值的获得是由于状态还是由于采取的动作的优势。
下面进行具体分解:
- 联合动作价值函数的dueling分解:
(Joint Dueling)
Q
t
o
t
(
τ
,
a
)
=
V
tot
(
τ
)
+
A
tot
(
τ
,
a
)
and
V
tot
(
τ
)
=
max
a
′
Q
tot
(
τ
,
a
′
)
\text { (Joint Dueling) } \quad Q_{t o t}(\boldsymbol{\tau}, \boldsymbol{a})=V_{\text {tot }}(\boldsymbol{\tau})+A_{\text {tot }}(\boldsymbol{\tau}, \boldsymbol{a}) \text { and } V_{\text {tot }}(\boldsymbol{\tau})=\max _{a^{\prime}} Q_{\text {tot }}\left(\boldsymbol{\tau}, \boldsymbol{a}^{\prime}\right)
(Joint Dueling) Qtot(τ,a)=Vtot (τ)+Atot (τ,a) and Vtot (τ)=a′maxQtot (τ,a′)
其中:
Q
tot
:
T
×
A
↦
R
Q_{\text {tot }}: \mathcal{T} \times \mathcal{A} \mapsto \mathbb{R}
Qtot :T×A↦R
- 个体动作价值函数的dueling分解:
(Individual Dueling)
Q
i
(
τ
i
,
a
i
)
=
V
i
(
τ
i
)
+
A
i
(
τ
i
,
a
i
)
and
V
i
(
τ
i
)
=
max
a
i
′
Q
i
(
τ
i
,
a
i
′
)
\text { (Individual Dueling) } \quad Q_{i}\left(\tau_{i}, a_{i}\right)=V_{i}\left(\tau_{i}\right)+A_{i}\left(\tau_{i}, a_{i}\right) \text { and } V_{i}\left(\tau_{i}\right)=\max _{a_{i}^{\prime}} Q_{i}\left(\tau_{i}, a_{i}^{\prime}\right)
(Individual Dueling) Qi(τi,ai)=Vi(τi)+Ai(τi,ai) and Vi(τi)=ai′maxQi(τi,ai′)
其中:
[
Q
i
:
T
×
A
↦
R
]
i
=
1
n
\left[Q_{i}: \mathcal{T} \times \mathcal{A} \mapsto \mathbb{R}\right]_{i=1}^{n}
[Qi:T×A↦R]i=1n, where
∀
τ
∈
T
,
∀
a
∈
A
,
∀
i
∈
N
\forall \boldsymbol{\tau} \in \mathcal{T}, \forall \boldsymbol{a} \in \mathcal{A}, \forall i \in \mathcal{N}
∀τ∈T,∀a∈A,∀i∈N
- 约束条件:
arg
max
a
∈
A
A
tot
(
τ
,
a
)
=
(
arg
max
a
1
∈
A
A
1
(
τ
1
,
a
1
)
,
…
,
arg
max
a
n
∈
A
A
n
(
τ
n
,
a
n
)
)
\underset{\boldsymbol{a} \in \mathcal{A}}{\arg \max } A_{\text {tot }}(\boldsymbol{\tau}, \boldsymbol{a})=\left(\underset{a_{1} \in \mathcal{A}}{\arg \max } A_{1}\left(\tau_{1}, a_{1}\right), \ldots, \underset{a_{n} \in \mathcal{A}}{\arg \max } A_{n}\left(\tau_{n}, a_{n}\right)\right)
a∈AargmaxAtot (τ,a)=(a1∈AargmaxA1(τ1,a1),…,an∈AargmaxAn(τn,an))
对于优势函数有:
A
π
(
s
,
a
)
=
Q
π
(
s
,
a
)
−
V
π
(
s
)
A^{\pi}(s, a)=Q^{\pi}(s, a)-V^{\pi}(s)
Aπ(s,a)=Qπ(s,a)−Vπ(s)
当执行最佳动作时:
Q
π
(
s
,
a
)
=
V
π
(
s
)
Q^{\pi}(s, a)=V^{\pi}(s)
Qπ(s,a)=Vπ(s) ,则对于联合动作优势函数有:
A
t
o
t
(
τ
,
a
∗
)
=
A
i
(
τ
i
,
a
i
∗
)
=
0
a
n
d
A
t
o
t
(
τ
,
a
)
<
0
,
A
i
(
τ
i
,
a
i
)
≤
0
A_{t o t}\left(\boldsymbol{\tau}, \boldsymbol{a}^{*}\right)=A_{i}\left(\tau_{i}, a_{i}^{*}\right)=0 \quad and \quad A_{t o t}(\boldsymbol{\tau}, \boldsymbol{a})<0, A_{i}\left(\tau_{i}, a_{i}\right) \leq 0
Atot(τ,a∗)=Ai(τi,ai∗)=0andAtot(τ,a)<0,Ai(τi,ai)≤0
where
A
∗
(
τ
)
=
{
a
∣
a
∈
A
,
Q
tot
(
τ
,
a
)
=
V
tot
(
τ
)
}
\mathcal{A}^{*}(\boldsymbol{\tau})=\left\{\boldsymbol{a} \mid \boldsymbol{a} \in \mathcal{A}, Q_{\text {tot }}(\boldsymbol{\tau}, \boldsymbol{a})=V_{\text {tot }}(\boldsymbol{\tau})\right\}
A∗(τ)={a∣a∈A,Qtot (τ,a)=Vtot (τ)}
∀
τ
∈
T
,
∀
a
∗
∈
A
∗
(
τ
)
,
∀
a
∈
A
\
A
∗
(
τ
)
,
∀
i
∈
N
\forall \boldsymbol{\tau} \in \mathcal{T}, \forall a^{*} \in \mathcal{A}^{*}(\tau), \forall a \in \mathcal{A} \backslash \mathcal{A}^{*}(\tau), \forall i \in \mathcal{N}
∀τ∈T,∀a∗∈A∗(τ),∀a∈A\A∗(τ),∀i∈N
因为V只和状态有关,与动作无关,所以影响Q的主要是A,那么就把上式的约束转成了IGM约束条件
2 QMIX 算法框架
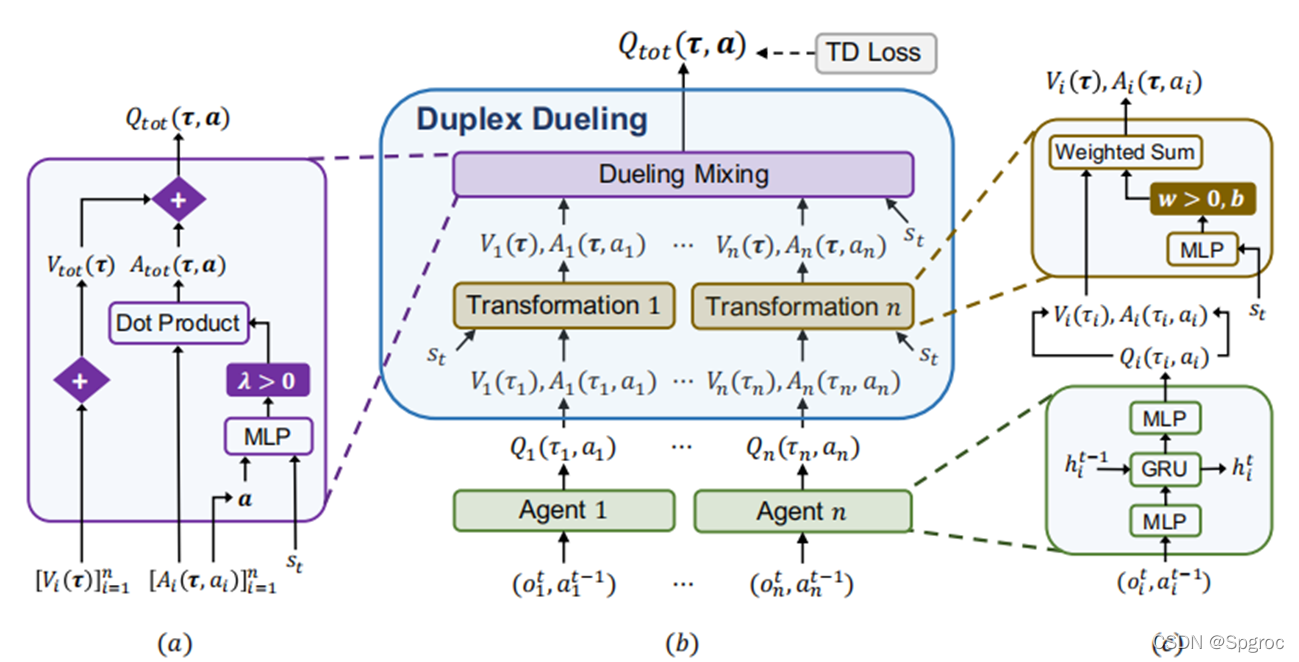
框架主要分三两部分:
- (a)Dueling Mixing网络
- (b)整体的Duplex Dueling架构
- (c)智能体网络结构,Transformation网络
下面进行具体分析:
2.1 Agent network(和QMIX网络的Agent network相同)
输入:
t
t
t时刻智能体
a
a
a的观测值
o
i
t
o_i^t
oit、
t
−
1
t-1
t−1时刻智能体
a
a
a的动作
a
i
t
−
1
a_i^{t-1}
ait−1
输出:
t
t
t时刻智能体
a
a
a的值函数
Q
i
(
τ
i
,
a
i
t
)
Q_{i}\left(\tau_{i}, a_i^{t}\right)
Qi(τi,ait)

Agent network由DRQN网络实现,根据不同的任务需求,不同智能体的网络可以进行单独训练,也可进行参数共享,DRQN是将DQN中的全连接层替换为LSTM网络,循环网络在观测质量变化的情况下,具有更强的适应性。如图所示,其网络一共包含 3 层,输入层(MLP多层神经网络)→ 中间层(GRU门控循环神经网络)→ 输出层(MLP多层神经网络)
实现代码如下:
智能体网络参数配置:
# --- Agent parameters ---
agent: "rnn" # Default rnn agent
rnn_hidden_dim: 64 # Size of hidden state for default rnn agent
obs_agent_id: True # Include the agent's one_hot id in the observation
obs_last_action: True # Include the agent's last action (one_hot) in the observation
RNN网络:
class RNNAgent(nn.Module):
def __init__(self, input_shape, args):
super(RNNAgent, self).__init__()
self.args = args
#根据参数配置,智能体网络的输入
#input_shape = obs_shape + n_actions + one_hot_code(one_hot_code_o+one_hot_code_u)
self.fc1 = nn.Linear(input_shape, args.rnn_hidden_dim) # 线性层
self.rnn = nn.GRUCell(args.rnn_hidden_dim, args.rnn_hidden_dim) # GRU层,需要输入隐藏状态
self.fc2 = nn.Linear(args.rnn_hidden_dim, args.n_actions) # 线性层
def init_hidden(self):
# make hidden states on same device as model
return self.fc1.weight.new(1, self.args.rnn_hidden_dim).zero_()
def forward(self, inputs, hidden_state):
x = F.relu(self.fc1(inputs)) # 输入经过线性层后relu激活,输出x
h_in = hidden_state.reshape(-1, self.args.rnn_hidden_dim) # 对隐藏状态进行变形,列数为隐藏层维度大小
h = self.rnn(x, h_in) # 循环神经网络,输入x,与隐藏状态(上一时刻信息)
q = self.fc2(h) # 输出Q值
return q, h
Transformation network
输入:智能体
i
i
i的状态价值函数
V
i
(
τ
i
)
V_i(\tau_i)
Vi(τi)、优势函数
A
i
(
τ
i
,
a
i
)
A_i(\tau_i,a_i)
Ai(τi,ai)、全局状态
s
t
s_t
st
输出:基于全局信息
s
s
s 智能体
i
i
i的状态价值函数
V
i
(
τ
)
V_i(\tau)
Vi(τ)、优势函数
A
i
(
τ
,
a
i
)
A_i(\tau,a_i)
Ai(τ,ai)

[
V
i
(
τ
i
)
,
A
i
(
τ
i
,
a
i
)
]
i
=
1
n
to
[
V
i
(
τ
)
,
A
i
(
τ
,
a
i
)
]
i
=
1
n
\left[V_{i}\left(\tau_{i}\right), A_{i}\left(\tau_{i}, a_{i}\right)\right]_{i=1}^{n} \text { to }\left[V_{i}(\boldsymbol{\tau}), A_{i}\left(\boldsymbol{\tau}, a_{i}\right)\right]_{i=1}^{n}
[Vi(τi),Ai(τi,ai)]i=1n to [Vi(τ),Ai(τ,ai)]i=1n
将局部的值函数与优势函数
V
i
(
τ
i
)
V_i(\tau_i)
Vi(τi) ,
A
i
(
τ
i
,
a
i
)
A_i(\tau_i,a_i)
Ai(τi,ai) 与全局信息
s
t
s_t
st(或联合观测历史 )结合,获得基于全局观测信息的局部值函数
V
i
(
τ
)
V_i(\tau)
Vi(τ),
A
i
(
τ
,
a
i
)
A_i(\tau,a_i)
Ai(τ,ai)
具体实现方式是:
V
i
(
τ
)
=
w
i
(
τ
)
V
i
(
τ
i
)
+
b
i
(
τ
)
and
A
i
(
τ
,
a
i
)
=
w
i
(
τ
)
A
i
(
τ
i
,
a
i
)
+
b
i
(
τ
)
V_{i}(\boldsymbol{\tau})=w_{i}(\boldsymbol{\tau}) V_{i}\left(\tau_{i}\right)+b_{i}(\boldsymbol{\tau}) \quad \text { and } \quad A_{i}\left(\boldsymbol{\tau}, a_{i}\right)=w_{i}(\boldsymbol{\tau}) A_{i}\left(\tau_{i}, a_{i}\right)+b_{i}(\boldsymbol{\tau})
Vi(τ)=wi(τ)Vi(τi)+bi(τ) and Ai(τ,ai)=wi(τ)Ai(τi,ai)+bi(τ)
其中
w
i
w_i
wi是正权值,保证了局部函数和全局函数之间的单调性。
实现代码如下:
# 超网络输出权重 W
self.hyper_w_final = nn.Sequential(nn.Linear(self.state_dim, hypernet_embed),
nn.ReLU(),
nn.Linear(hypernet_embed, self.n_agents))
# 超网络输出偏差 bias
self.V = nn.Sequential(nn.Linear(self.state_dim, hypernet_embed),
nn.ReLU(),
nn.Linear(hypernet_embed, self.n_agents))
# 根据全局状态s获得transformation网络的参数
w_final = self.hyper_w_final(states) # 获得W权重
w_final = th.abs(w_final) # 求绝对值保证单调
w_final = w_final.view(-1, self.n_agents) + 1e-10
v = self.V(states) # 获得b偏差
v = v.view(-1, self.n_agents)
if self.args.weighted_head: # 是否使用加权头
agent_qs = w_final * agent_qs + v # 计算智能体动作价值函数
if not is_v:
max_q_i = max_q_i.view(-1, self.n_agents)
if self.args.weighted_head:
max_q_i = w_final * max_q_i + v # 根据状态值函数计算
2.2 Dueling Mixing network
输入:智能体
i
i
i的状态价值函数
V
i
(
τ
)
V_i(\tau)
Vi(τ)、优势函数
A
i
(
τ
,
a
i
)
A_i(\tau,a_i)
Ai(τ,ai)、全局状态
s
t
s_t
st
输出:联合动作价值函数
Q
t
o
t
(
τ
,
a
)
Q_{tot}\left(\tau, a\right)
Qtot(τ,a)

Dueling Mixing network 主要由两部分组成:
Q
t
o
t
(
τ
,
a
)
=
V
t
o
t
(
τ
)
+
A
t
o
t
(
τ
,
a
)
Q_{t o t}(\boldsymbol{\tau}, \boldsymbol{a})=V_{t o t}(\boldsymbol{\tau})+A_{t o t}(\boldsymbol{\tau}, \boldsymbol{a})
Qtot(τ,a)=Vtot(τ)+Atot(τ,a)
- 计算 V t o t ( τ ) V_{tot}(\tau) Vtot(τ):
因为
V
V
V仅与状态
s
s
s(或联合观测历史
τ
\tau
τ)有关,
V
t
o
t
(
τ
)
V_{tot}(\tau)
Vtot(τ) 表示为:
V
t
o
t
(
τ
)
=
∑
i
=
1
n
V
i
(
τ
)
V_{t o t}(\boldsymbol{\tau})=\sum_{i=1}^{n} V_{i}(\boldsymbol{\tau})
Vtot(τ)=i=1∑nVi(τ)
- 计算
A
t
o
t
(
τ
,
a
)
A_{tot}(\tau,a)
Atot(τ,a):
A t o t ( τ , a ) = ∑ i = 1 n λ i ( τ , a ) A i ( τ , a i ) A_{t o t}(\tau, a)=\sum_{i=1}^{n} \lambda_{i}(\boldsymbol{\tau}, \boldsymbol{a}) A_{i}\left(\boldsymbol{\tau}, a_{i}\right) Atot(τ,a)=i=1∑nλi(τ,a)Ai(τ,ai)
其中
,
λ
i
(
τ
,
a
)
>
0
,\lambda_{i}(\tau, \boldsymbol{a})>0
,λi(τ,a)>0,保证贪婪动作选择与策略一致
λ
i
(
τ
,
a
)
=
∑
k
=
1
K
λ
i
,
k
(
τ
,
a
)
ϕ
i
,
k
(
τ
)
v
k
(
τ
)
\lambda_{i}(\boldsymbol{\tau}, \boldsymbol{a})=\sum_{k=1}^{K} \lambda_{i, k}(\boldsymbol{\tau}, \boldsymbol{a}) \phi_{i, k}(\boldsymbol{\tau}) v_{k}(\boldsymbol{\tau})
λi(τ,a)=k=1∑Kλi,k(τ,a)ϕi,k(τ)vk(τ)
λ
i
(
τ
,
a
)
\lambda_{i}(\tau, \boldsymbol{a})
λi(τ,a)采用multi-head attention机制,式中,
K
K
K 是头数,
λ
i
,
k
(
τ
,
a
)
,
ϕ
i
,
k
(
τ
)
\lambda_{i, k}(\tau, a), \phi_{i, k}(\tau)
λi,k(τ,a),ϕi,k(τ) 为被sigmoid激活的注意力权重,
v
k
(
τ
)
>
0
v_{k}(\tau)>0
vk(τ)>0 为每个head的key
- 有了
V
t
o
t
(
τ
)
V_{tot}(\tau)
Vtot(τ),
A
t
o
t
(
τ
,
a
)
A_{tot}(\tau,a)
Atot(τ,a),可求
Q
t
o
t
Q_{tot}
Qtot:
Q t o t ( τ , a ) = V tot ( τ ) + A t o t ( τ , a ) = ∑ i = 1 n Q i ( τ , a i ) + ∑ i = 1 n ( λ i ( τ , a ) − 1 ) A i ( τ , a i ) Q_{t o t}(\boldsymbol{\tau}, \boldsymbol{a})=V_{\text {tot }}(\boldsymbol{\tau})+A_{t o t}(\boldsymbol{\tau}, \boldsymbol{a})=\sum_{i=1}^{n} Q_{i}\left(\boldsymbol{\tau}, a_{i}\right)+\sum_{i=1}^{n}\left(\lambda_{i}(\boldsymbol{\tau}, \boldsymbol{a})-1\right) A_{i}\left(\boldsymbol{\tau}, a_{i}\right) Qtot(τ,a)=Vtot (τ)+Atot(τ,a)=i=1∑nQi(τ,ai)+i=1∑n(λi(τ,a)−1)Ai(τ,ai)
其中, 前半部分
∑
i
=
1
n
Q
i
(
τ
,
a
i
)
\sum_{i=1}^{n} Q_{i}\left(\tau, a_{i}\right)
∑i=1nQi(τ,ai) 与VDN的
Q
t
o
t
V
D
N
Q_{t o t}^{V D N}
QtotVDN 相同, 而后半部分修正了
Q
tot
V
D
N
Q_{\text {tot }}^{V D N}
Qtot VDN 与真实的联合动作价值函数
Q
t
o
t
Q_{tot}
Qtot之间的误差。
实现代码如下:
# use the Q_Learner to train
agent_output_type: "q"
learner: "q_learner"
double_q: True
mixer: "qmix"
mixing_embed_dim: 32
hypernet_layers: 2
hypernet_embed: 64
class DMAQer(nn.Module):
def __init__(self, args):
super(DMAQer, self).__init__()
# 智能体、环境参数读取
self.args = args
self.n_agents = args.n_agents
self.n_actions = args.n_actions
self.state_dim = int(np.prod(args.state_shape))
self.action_dim = args.n_agents * self.n_actions
self.state_action_dim = self.state_dim + self.action_dim + 1
self.embed_dim = args.mixing_embed_dim # 隐层维度
hypernet_embed = self.args.hypernet_embed # 超网络的隐层维度
# 超网络输出权重 W
self.hyper_w_final = nn.Sequential(nn.Linear(self.state_dim, hypernet_embed),
nn.ReLU(),
nn.Linear(hypernet_embed, self.n_agents))
# 超网络输出偏差 bias
self.V = nn.Sequential(nn.Linear(self.state_dim, hypernet_embed),
nn.ReLU(),
nn.Linear(hypernet_embed, self.n_agents))
# 计算lambda
self.si_weight = DMAQ_SI_Weight(args)
# Q_{tot}=V_{tot}+A_{tot}=\sum Q_{i}+ \sum{(\lambda-1)*A_{i}}
def calc_v(self, agent_qs): # Dueling Mixing网络计算V_tot V_{tot}=\sum V_{i}
agent_qs = agent_qs.view(-1, self.n_agents)
v_tot = th.sum(agent_qs, dim=-1) # 求和
return v_tot
def calc_adv(self, agent_qs, states, actions, max_q_i): # Dueling Mixing网络计算A_tot \sum{(\lambda-1)*A_{i}}
states = states.reshape(-1, self.state_dim)
actions = actions.reshape(-1, self.action_dim)
agent_qs = agent_qs.view(-1, self.n_agents)
max_q_i = max_q_i.view(-1, self.n_agents)
adv_q = (agent_qs - max_q_i).view(-1, self.n_agents).detach() # 计算优势函数,并去掉梯度
adv_w_final = self.si_weight(states, actions) # 获得权重
adv_w_final = adv_w_final.view(-1, self.n_agents)
# 计算A_tot
if self.args.is_minus_one: # 是不是相减的形式
adv_tot = th.sum(adv_q * (adv_w_final - 1.), dim=1) # \sum{(\lambda-1)*A_{i}}
else:
adv_tot = th.sum(adv_q * adv_w_final, dim=1)
return adv_tot
def calc(self, agent_qs, states, actions=None, max_q_i=None, is_v=False): # 计算total价值函数
if is_v:
v_tot = self.calc_v(agent_qs)
return v_tot
else:
adv_tot = self.calc_adv(agent_qs, states, actions, max_q_i)
return adv_tot
def forward(self, agent_qs, states, actions=None, max_q_i=None, is_v=False):
bs = agent_qs.size(0) # 样本数量数
states = states.reshape(-1, self.state_dim)
agent_qs = agent_qs.view(-1, self.n_agents)
# 根据全局状态s获得transformation网络的参数
w_final = self.hyper_w_final(states) # 获得W权重
w_final = th.abs(w_final) # 求绝对值保证单调
w_final = w_final.view(-1, self.n_agents) + 1e-10
v = self.V(states) # 获得b偏差
v = v.view(-1, self.n_agents)
if self.args.weighted_head: # 是否使用加权头
agent_qs = w_final * agent_qs + v # 计算智能体动作价值函数
if not is_v:
max_q_i = max_q_i.view(-1, self.n_agents)
if self.args.weighted_head:
max_q_i = w_final * max_q_i + v # 根据状态值函数计算
y = self.calc(agent_qs, states, actions=actions, max_q_i=max_q_i, is_v=is_v) # 进入Dueling Mixing网络,计算total
v_tot = y.view(bs, -1, 1)
return v_tot
多头注意力计算部分:
λ
i
(
τ
,
a
)
=
∑
k
=
1
K
λ
i
,
k
(
τ
,
a
)
ϕ
i
,
k
(
τ
)
v
k
(
τ
)
\lambda_{i}(\boldsymbol{\tau}, \boldsymbol{a})=\sum_{k=1}^{K} \lambda_{i, k}(\boldsymbol{\tau}, \boldsymbol{a}) \phi_{i, k}(\boldsymbol{\tau}) v_{k}(\boldsymbol{\tau})
λi(τ,a)=k=1∑Kλi,k(τ,a)ϕi,k(τ)vk(τ)
class DMAQ_SI_Weight(nn.Module):
def __init__(self, args):
super(DMAQ_SI_Weight, self).__init__()
self.args = args
self.n_agents = args.n_agents
self.n_actions = args.n_actions
self.state_dim = int(np.prod(args.state_shape))
self.action_dim = args.n_agents * self.n_actions
self.state_action_dim = self.state_dim + self.action_dim
self.num_kernel = args.num_kernel
self.key_extractors = nn.ModuleList()
self.agents_extractors = nn.ModuleList()
self.action_extractors = nn.ModuleList()
adv_hypernet_embed = self.args.adv_hypernet_embed
for i in range(self.num_kernel): # multi-head attention
if getattr(args, "adv_hypernet_layers", 1) == 1:
self.key_extractors.append(nn.Linear(self.state_dim, 1)) # key
self.agents_extractors.append(nn.Linear(self.state_dim, self.n_agents)) # agent
self.action_extractors.append(nn.Linear(self.state_action_dim, self.n_agents)) # action
elif getattr(args, "adv_hypernet_layers", 1) == 2:
self.key_extractors.append(nn.Sequential(nn.Linear(self.state_dim, adv_hypernet_embed),
nn.ReLU(),
nn.Linear(adv_hypernet_embed, 1))) # key
self.agents_extractors.append(nn.Sequential(nn.Linear(self.state_dim, adv_hypernet_embed),
nn.ReLU(),
nn.Linear(adv_hypernet_embed, self.n_agents))) # agent
self.action_extractors.append(nn.Sequential(nn.Linear(self.state_action_dim, adv_hypernet_embed),
nn.ReLU(),
nn.Linear(adv_hypernet_embed, self.n_agents))) # action
elif getattr(args, "adv_hypernet_layers", 1) == 3:
self.key_extractors.append(nn.Sequential(nn.Linear(self.state_dim, adv_hypernet_embed),
nn.ReLU(),
nn.Linear(adv_hypernet_embed, adv_hypernet_embed),
nn.ReLU(),
nn.Linear(adv_hypernet_embed, 1))) # key
self.agents_extractors.append(nn.Sequential(nn.Linear(self.state_dim, adv_hypernet_embed),
nn.ReLU(),
nn.Linear(adv_hypernet_embed, adv_hypernet_embed),
nn.ReLU(),
nn.Linear(adv_hypernet_embed, self.n_agents))) # agent
self.action_extractors.append(nn.Sequential(nn.Linear(self.state_action_dim, adv_hypernet_embed),
nn.ReLU(),
nn.Linear(adv_hypernet_embed, adv_hypernet_embed),
nn.ReLU(),
nn.Linear(adv_hypernet_embed, self.n_agents))) # action
else:
raise Exception("Error setting number of adv hypernet layers.")
def forward(self, states, actions):
states = states.reshape(-1, self.state_dim)
actions = actions.reshape(-1, self.action_dim)
data = th.cat([states, actions], dim=1)
all_head_key = [k_ext(states) for k_ext in self.key_extractors]
all_head_agents = [k_ext(states) for k_ext in self.agents_extractors]
all_head_action = [sel_ext(data) for sel_ext in self.action_extractors]
head_attend_weights = []
for curr_head_key, curr_head_agents, curr_head_action in zip(all_head_key, all_head_agents, all_head_action):
x_key = th.abs(curr_head_key).repeat(1, self.n_agents) + 1e-10 #v_{k}(\tau)
x_agents = F.sigmoid(curr_head_agents) #\phi_{i, k}(\tau)
x_action = F.sigmoid(curr_head_action) #\lambda_{i, k}(\tau, a)
weights = x_key * x_agents * x_action #权重
head_attend_weights.append(weights)
head_attend = th.stack(head_attend_weights, dim=1)
head_attend = head_attend.view(-1, self.num_kernel, self.n_agents)
head_attend = th.sum(head_attend, dim=1) #求和
return head_attend
2.3 算法更新流程

损失函数:
L
(
θ
)
=
∑
i
=
1
b
[
(
y
i
t
o
t
−
Q
t
o
t
(
τ
,
u
,
s
;
θ
)
)
2
]
\mathcal{L}(\theta)=\sum_{i=1}^{b}\left[\left(y_{i}^{t o t}-Q_{t o t}(\tau, \mathbf{u}, s ; \theta)\right)^{2}\right]
L(θ)=∑i=1b[(yitot−Qtot(τ,u,s;θ))2]
其中
b
b
b表示从经验池中采样的样本数量,
y
t
o
t
=
r
+
γ
max
u
′
Q
t
o
t
(
τ
′
,
u
′
,
s
′
;
θ
−
)
y^{t o t}=r+\gamma \max _{\mathbf{u}^{\prime}} Q_{t o t}\left(\tau^{\prime}, \mathbf{u}^{\prime}, s^{\prime} ; \theta^{-}\right)
ytot=r+γmaxu′Qtot(τ′,u′,s′;θ−),
θ
−
\theta^{-}
θ−是目标网络的参数,
所以时序差分的误差可表示为:
T
D
e
r
r
o
r
=
(
r
+
γ
Q
t
o
t
(
target
)
)
−
Q
t
o
t
(
evalutate
)
\begin{aligned} {TDerror}=(r+\gamma Q _{ tot }(\text { target })) -Q _{ tot }(\text { evalutate }) \end{aligned}
TDerror=(r+γQtot( target ))−Qtot( evalutate )
Q
t
o
t
(
target
)
Q _{ tot }(\text { target })
Qtot( target ):状态
s
′
s^{'}
s′的情况下,所有行为中,获取的最大价值
Q
t
o
t
Q_{tot}
Qtot。根据IGM条件,输入为此状态下每个智能体的最大动作价值。
Q
t
o
t
(
evalutate
)
Q _{ tot }(\text { evalutate })
Qtot( evalutate ): 状态
s
s
s的情况下,根据当前网络策略所能获得
Q
t
o
t
Q_{tot}
Qtot。
实现代码如下:
参数配置:
# use epsilon greedy action selector
# --- QMIX specific parameters ---
# use epsilon greedy action selector
action_selector: "epsilon_greedy"
epsilon_start: 1.0
epsilon_finish: 0.05
epsilon_anneal_time: 50000
runner: "episode"
buffer_size: 5000
# update the target network every {} episodes
target_update_interval: 200
# use the Q_Learner to train
agent_output_type: "q"
learner: "q_learner"
double_q: True
mixer: "qmix"
mixing_embed_dim: 32
hypernet_layers: 2
hypernet_embed: 64
name: "qmix"
动作选择:(ε-greedy)
class EpsilonGreedyActionSelector():
def __init__(self, args):
self.args = args
self.schedule = DecayThenFlatSchedule(args.epsilon_start, args.epsilon_finish, args.epsilon_anneal_time,
decay="linear")
self.epsilon = self.schedule.eval(0)
def select_action(self, agent_inputs, avail_actions, t_env, test_mode=False):
# Assuming agent_inputs is a batch of Q-Values for each agent bav
self.epsilon = self.schedule.eval(t_env) # 获取epsilon
if test_mode:
# Greedy action selection only
self.epsilon = 0.0
# mask actions that are excluded from selection
masked_q_values = agent_inputs.clone() # q值 q_value
masked_q_values[avail_actions == 0.0] = -float("inf") # should never be selected! 不能选择的动作赋值为 负无穷
random_numbers = th.rand_like(agent_inputs[:, :, 0]) # 生成相同维度的随机矩阵
pick_random = (random_numbers < self.epsilon).long() # 如果小于epsilon
random_actions = Categorical(avail_actions.float()).sample().long() # 把可选的动作进行类别分布
# pick_random==1 说明 random_numbers < self.epsilon 进行随机探索
# pick_random==0 说明 random_numbers > self.epsilon 选择动作价值最大的函数
picked_actions = pick_random * random_actions + (1 - pick_random) * masked_q_values.max(dim=2)[1] # 进行动作选择
return picked_actions # 选择的动作
计算单个智能体估计的Q值
# Calculate estimated Q-Values 估计每个agent对应的Q值
mac_out = []
mac.init_hidden(batch.batch_size)
for t in range(batch.max_seq_length):
agent_outs = mac.forward(batch, t=t) # 计算智能体的Q值
mac_out.append(agent_outs)
mac_out = th.stack(mac_out, dim=1) # Concat over time
# Pick the Q-Values for the actions taken by each agent
# 取每个agent动作对应的Q值,并且把最后不需要的一维去掉,因为最后一维只有一个值了
chosen_action_qvals = th.gather(mac_out[:, :-1], dim=3, index=actions).squeeze(3) # Remove the last dim
x_mac_out = mac_out.clone().detach() # 提取数据不带梯度
x_mac_out[avail_actions == 0] = -9999999 # 不能执行的动作赋值为负无穷
max_action_qvals, max_action_index = x_mac_out[:, :-1].max(dim=3) # 最大的动作值及其索引
max_action_index = max_action_index.detach().unsqueeze(3) # 去掉梯度
is_max_action = (max_action_index == actions).int().float() # 是最大动作
计算单个智能体目标Q值
# Calculate the Q-Values necessary for the target 计算目标Q值
target_mac_out = []
self.target_mac.init_hidden(batch.batch_size)
for t in range(batch.max_seq_length):
target_agent_outs = self.target_mac.forward(batch, t=t)
target_mac_out.append(target_agent_outs)
# We don't need the first timesteps Q-Value estimate for calculating targets
target_mac_out = th.stack(target_mac_out[1:], dim=1) # Concat across time
# Mask out unavailable actions
target_mac_out[avail_actions[:, 1:] == 0] = -9999999
# Max over target Q-Values 找到最大的动作价值
if self.args.double_q: # 使用double结构,找到最大价值动作,再进行计算价值
# Get actions that maximise live Q (for double q-learning)
mac_out_detach = mac_out.clone().detach()
mac_out_detach[avail_actions == 0] = -9999999
cur_max_actions = mac_out_detach[:, 1:].max(dim=3, keepdim=True)[1] # 找到最大价值的动作
# 利用最优动作求取最大动作价值,并且把最后不需要的一维去掉
target_chosen_qvals = th.gather(target_mac_out, 3, cur_max_actions).squeeze(3)
target_max_qvals = target_mac_out.max(dim=3)[0]
target_next_actions = cur_max_actions.detach()
cur_max_actions_onehot = th.zeros(cur_max_actions.squeeze(3).shape + (self.n_actions,)).cuda() # 最大价值动作的独热码
cur_max_actions_onehot = cur_max_actions_onehot.scatter_(3, cur_max_actions, 1)
else:
# Calculate the Q-Values necessary for the target
# 上面都写了,不知道为啥又写一遍
target_mac_out = []
self.target_mac.init_hidden(batch.batch_size)
for t in range(batch.max_seq_length):
target_agent_outs = self.target_mac.forward(batch, t=t)
target_mac_out.append(target_agent_outs)
# We don't need the first timesteps Q-Value estimate for calculating targets
target_mac_out = th.stack(target_mac_out[1:], dim=1) # Concat across time
target_max_qvals = target_mac_out.max(dim=3)[0] # 找到最大价值函数
根据损失函数,进行反向传播
# Mix 混合网络,求total值
# QPLEX更新过程,evaluate网络输入的是每个agent选出来的行为的q值,target网络输入的是每个agent最大的q值,和DQN更新方式一样
if mixer is not None:
# 计算Q _{ tot }(evalutate)
if self.args.mixer == "dmaq_qatten":
ans_chosen, q_attend_regs, head_entropies = \
mixer(chosen_action_qvals, batch["state"][:, :-1], is_v=True) # 计算状态价值V
ans_adv, _, _ = mixer(chosen_action_qvals, batch["state"][:, :-1], actions=actions_onehot,
max_q_i=max_action_qvals, is_v=False) # 计算优势值A
chosen_action_qvals = ans_chosen + ans_adv # 动作价值Q
else:
ans_chosen = mixer(chosen_action_qvals, batch["state"][:, :-1], is_v=True) # 计算状态价值V
ans_adv = mixer(chosen_action_qvals, batch["state"][:, :-1], actions=actions_onehot,
max_q_i=max_action_qvals, is_v=False) # 计算优势值A
chosen_action_qvals = ans_chosen + ans_adv # 动作价值Q
# 计算Q _{ tot }(target )
if self.args.double_q:
if self.args.mixer == "dmaq_qatten":
target_chosen, _, _ = self.target_mixer(target_chosen_qvals, batch["state"][:, 1:],
is_v=True) # 计算状态价值V
target_adv, _, _ = self.target_mixer(target_chosen_qvals, batch["state"][:, 1:],
actions=cur_max_actions_onehot,
max_q_i=target_max_qvals, is_v=False) # 计算优势值A
target_max_qvals = target_chosen + target_adv # 动作价值Q
else:
target_chosen = self.target_mixer(target_chosen_qvals, batch["state"][:, 1:], is_v=True) # 计算状态价值V
target_adv = self.target_mixer(target_chosen_qvals, batch["state"][:, 1:],
actions=cur_max_actions_onehot,
max_q_i=target_max_qvals, is_v=False) # 计算优势值A
target_max_qvals = target_chosen + target_adv # 动作价值Q
else:
target_max_qvals = self.target_mixer(target_max_qvals, batch["state"][:, 1:], is_v=True) # 动作价值Q
# Calculate 1-step Q-Learning targets 以Q-Learning的方法计算目标值r+gamma*Q _{ tot }({ target }
targets = rewards + self.args.gamma * (1 - terminated) * target_max_qvals
if show_demo:
tot_q_data = chosen_action_qvals.detach().cpu().numpy()
tot_target = targets.detach().cpu().numpy()
print('action_pair_%d_%d' % (save_data[0], save_data[1]), np.squeeze(q_data[:, 0]),
np.squeeze(q_i_data[:, 0]), np.squeeze(tot_q_data[:, 0]), np.squeeze(tot_target[:, 0]))
self.logger.log_stat('action_pair_%d_%d' % (save_data[0], save_data[1]),
np.squeeze(tot_q_data[:, 0]), t_env)
return
# Td-error
td_error = (chosen_action_qvals - targets.detach())
mask = mask.expand_as(td_error) # 将mask扩展为td_error相同的size
# 0-out the targets that came from padded data
masked_td_error = td_error * mask # 抹掉填充的经验的td_error
# Normal L2 loss, take mean over actual data
if self.args.mixer == "dmaq_qatten":
loss = (masked_td_error ** 2).sum() / mask.sum() + q_attend_regs
else:
# L2的损失函数,不能直接用mean,因为还有许多经验是没用的,所以要求和再比真实的经验数,才是真正的均值
loss = (masked_td_error ** 2).sum() / mask.sum()
# Optimise RMSprop
# 优化
optimiser.zero_grad()
loss.backward()
grad_norm = th.nn.utils.clip_grad_norm_(params, self.args.grad_norm_clip)
optimiser.step()
3 实验效果:
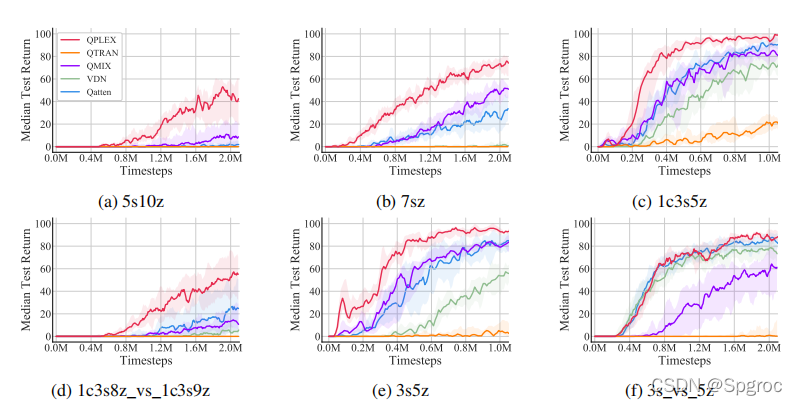
下图为在星际争霸2六种不同的在线数据收集地图的学习曲线。可以看到QPLEX显著优于其他算法
参考:
博客:QPLEX: Duplex Dueling Multi-agent Q-learning
代码:https://github.com/oxwhirl/pymarl


















 1975
1975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











