






原文链接:
https://blog.csdn.net/langb2014/article/details/84953307
这个链接是Meta-learning近年来的一些paper:
https://github.com/floodsung/Meta-Learning-Papers
- Meta-Learning
Meta-Learning 即元学习,又称Learning to Learn (学习如何学习)是人工智能理论研究领域前沿也是一项重要分支:Machine Learning --> Deep Learning --> Reinforcement Learning --> Meta Learning。
Machine Learning: 能解决相对简单的分类回归问题;
Deep Learning: 基本解决了一对一映射问题(一个输入对应一个输出);
Reinforcement Learning: 对sequential decision making有了进一步的进展,但需要巨量的训练,和精确的Reward;
但现实情况往往无法实现无限训练或者没有好的reward,如何充分利用以往的知识经验来完成快速的学习,成为人工智能研究新的攻克方向。
先想想如何才能实现快速学习?
一个很简单的道理,我们人可以利用以往的经验来学习。我们人是基于价值观驱动的动物,即我们做任何事情前都有一杆秤在衡量这件事的重要性,即使有时非常感性,但也是因为感性的时候做那件事的价值最大化了。我们是否可以让AI拥有价值观,并利用价值观来驱动AI快速学习。
这篇paper(https://arxiv.org/pdf/1706.09529.pdf)给出了一个方法:
让AI在学习在学习各种任务后形成一个核心的价值网络,从而面对新的任务时,可以利用已有的核心价值网络来加速AI的学习速度。
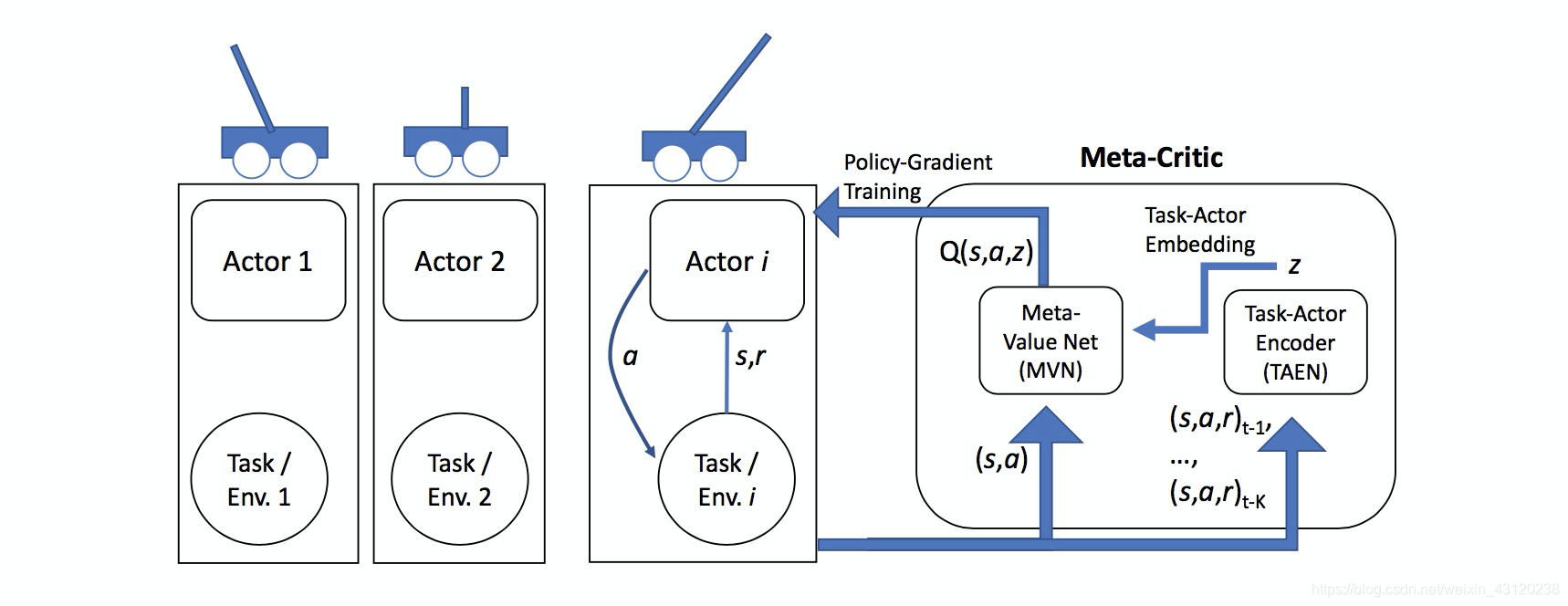
图一:Meta-Critic Network 的示意图;我们希望AI通过学习保持不同长度的杆的任务后,面对一个新的长度的杆,能快速学习掌握让杆平衡的技巧。
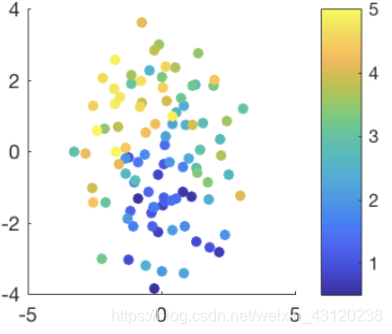
具体流程是对每个任务构建一个Actor Network和一个整体核心指导网络(Meta Critic Network)。其包含了两个网络,Meta Value Network和Task-Actor Encoder。在训练多个任务的同时,也训练这个Meta Crtiric Network。网络的关键在于Task-Actor Encoder,在给定任务的历史经验(状态stage,动作action和回馈reward),Task-Actor Encoder 输出任务的表示信息z。为了了解z到底学到了什么,我们用t-SNE可视化出z,如图所示:z的分布与杆的长度是直接相关的。 这意味着Task-Actor Encoder确实利用了以往的经验来理解训练一个任务。
- Model-Agnostic
即模型无关,与其说是一个深度学习的model,倒不如说是一个framwork。与在dataset上训练的base-learner不同的是,meta-learner是用于训练base-leanrer的。绝大多数深度学习模型都可作为base-leaner被嵌入在meta-learner中。

















 8338
8338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









