







电商平台用户退款预测模型(Python语言)
(…待改进)
# 加载需要用到的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
plt.style.use('fivethirtyeight')
from warnings import filterwarnings
filterwarnings('ignore')
orders=pd.read_excel('chargepre.xlsx')
orders
| goodsID | orderAmount | payment | chanelID | platfromType | discount | payyear | paymonth | chargeback | usercount_total_count | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PR000940 | 1978.47 | 1770.81 | 渠道-0530 | WechatMP | 0.104960 | 2019 | 10 | 否 | 1 |
| 2 | PR000512 | 521.60 | 511.59 | 渠道-0765 | WechatMP | 0.019191 | 2019 | 5 | 否 | 1 |
| 3 | PR000398 | 466.89 | 443.55 | 渠道-0007 | WechatMP | 0.049990 | 2019 | 11 | 否 | 2 |
| 4 | PR000351 | 2337.01 | 2328.43 | 渠道-0985 | APP | 0.003671 | 2019 | 10 | 是 | 2 |
| 5 | PR000433 | 2178.20 | 2162.14 | 渠道-9527 | APP | 0.007373 | 2019 | 1 | 否 | 1 |
| 6 | PR000771 | 4949.65 | 4879.94 | 渠道-0007 | WechatMP | 0.014084 | 2019 | 11 | 否 | 1 |
| 7 | PR000828 | 565.26 | 556.96 | 渠道-0896 | WechatMP | 0.014684 | 2019 | 9 | 否 | 1 |
| 8 | PR000147 | 430.34 | 373.46 | 渠道-0465 | APP | 0.132175 | 2019 | 7 | 否 | 1 |
| 9 | PR000060 | 694.52 | 664.79 | 渠道-0530 | APP | 0.042807 | 2019 | 3 | 是 | 2 |
| 10 | PR000072 | 453.83 | 371.50 | 渠道-0283 | WechatMP | 0.181412 | 2019 | 12 | 否 | 2 |
| 11 | PR000898 | 529.57 | 488.08 | 渠道-0530 | WEB | 0.078347 | 2019 | 11 | 否 | 2 |
104552 rows × 10 columns
orders.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 104552 entries, 1 to 104552
Data columns (total 10 columns):
goodsID 104552 non-null object
orderAmount 104552 non-null float64
payment 104552 non-null float64
chanelID 104552 non-null object
platfromType 104552 non-null object
discount 104552 non-null float64
payyear 104552 non-null int64
paymonth 104552 non-null int64
chargeback 104552 non-null object
usercount_total_count 104552 non-null int64
dtypes: float64(3), int64(3), object(4)
memory usage: 8.8+ MB
plt.figure(figsize=(20,10))
sns.pairplot(orders)

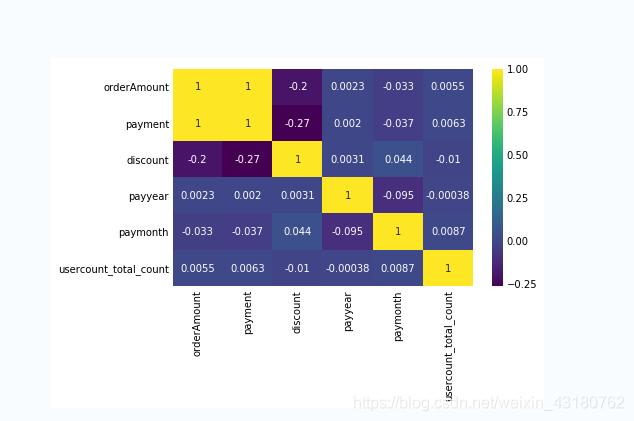
sns.heatmap(orders.corr(),annot=True,cmap='viridis')
target_array = orders['chargeback'].copy()
train = orders.drop(orders[['chargeback']],axis=1)
test = train
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
for feature in ['goodsID','chanelID','platfromType','orderAmount','payment','discount','payyear','paymonth','usercount_total_count']:
train[feature]=le.fit_transform(train[feature])
# test[feature]=le.transform(test[feature])
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
train = pd.DataFrame(scaler.fit_transform(train), columns=train.columns)
test = pd.DataFrame(scaler.transform(test), columns=test.columns)
X = train
y = target_array
X_to_be_predicted = test
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
from lightgbm import LGBMClassifier
model = LGBMClassifier(learning_rate=0.1,
n_estimators=10000,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
nthread=4,
scale_pos_weight=3,
seed=10)
model.fit(X_train, y_train)
[LightGBM] [Warning] Unknown parameter: gamma
[LightGBM] [Warning] num_threads is set with n_jobs=-1, nthread=4 will be ignored. Current value: num_threads=-1
[LightGBM] [Warning] Accuracy may be bad since you didn't explicitly set num_leaves OR 2^max_depth > num_leaves. (num_leaves=31).
LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=0.8,
gamma=0, importance_type='split', learning_rate=0.1, max_depth=5,
min_child_samples=20, min_child_weight=1, min_split_gain=0.0,
n_estimators=10000, n_jobs=-1, nthread=4, num_leaves=31,
objective=None, random_state=None, reg_alpha=0.0, reg_lambda=0.0,
scale_pos_weight=3, seed=10, silent=True, subsample=0.8,
subsample_for_bin=200000, subsample_freq=0)
from sklearn.metrics import classification_report
#打印评分
print(classification_report(y_train, model.predict(X_train)))
#测试集
print(classification_report(y_test, model.predict(X_test)))
y_predict = model.predict(X_to_be_predicted)
y_predict
precision recall f1-score support
否 1.00 0.99 1.00 68085
是 0.96 0.98 0.97 10329
micro avg 0.99 0.99 0.99 78414
macro avg 0.98 0.99 0.98 78414
weighted avg 0.99 0.99 0.99 78414
precision recall f1-score support
否 0.87 0.93 0.90 22687
是 0.12 0.06 0.08 3451
micro avg 0.82 0.82 0.82 26138
macro avg 0.50 0.50 0.49 26138
weighted avg 0.77 0.82 0.79 26138
array(['否', '否', '否', ..., '否', '否', '否'], dtype=object)
训练结果明显过拟合,由于原始数据(0/1)比例十分不均衡,接近9:1,故导致训练结果异常。
关于样本不均衡情况,应当进行如何处理?
根据样本数据又是否能高精度预测呢?


















 1672
1672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









