






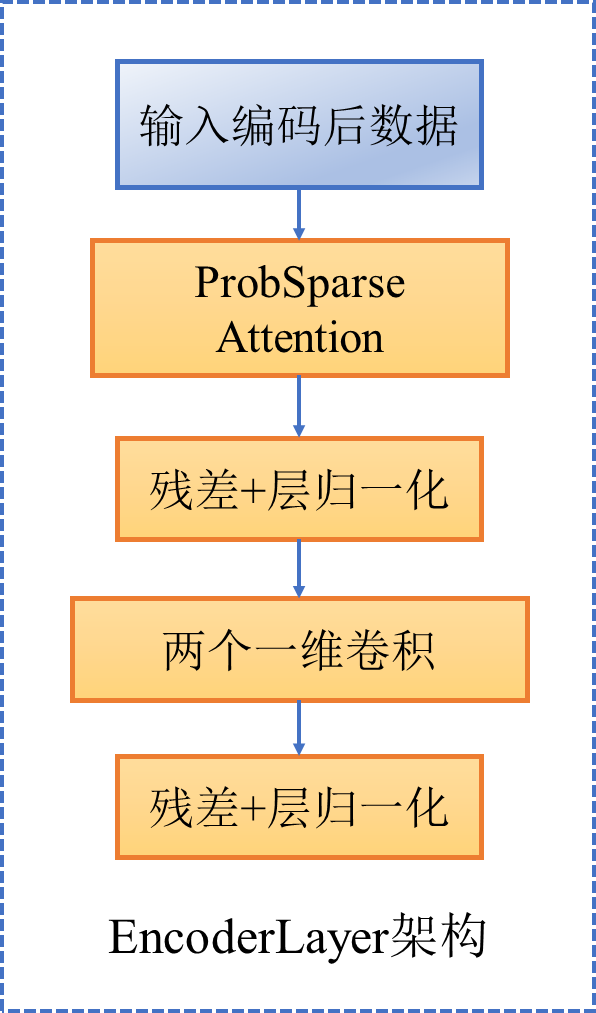
一、EncoderLayer架构如图(不改变输入形状)
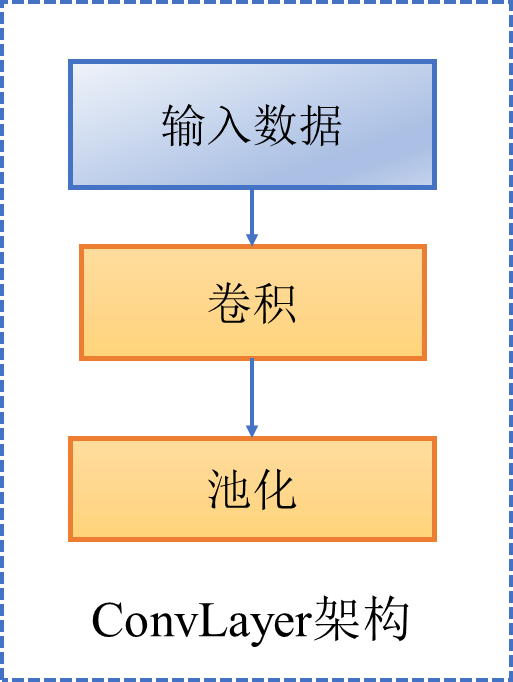
二、ConvLayer架构如图(输入形状中特征维度减半)
三、Encoder整体
包括三部分
1. 多层EncoderLayer
2. 多层ConvLayer
3. 层归一化
代码如下
class AttentionLayer(nn.Module):
def __init__(self, attention, d_model, n_heads,
d_keys=None, d_values=None, mix=False):
super(AttentionLayer, self).__init__()
d_keys = d_keys or (d_model//n_heads)
d_values = d_values or (d_model//n_heads)
self.inner_attention = attention
self.query_projection = nn.Linear(d_model, d_keys * n_heads)
self.key_projection = nn.Linear(d_model, d_keys * n_heads)
self.value_projection = nn.Linear(d_model, d_values * n_heads)
self.out_projection = nn.Linear(d_values * n_heads, d_model)
self.n_heads = n_heads
self.mix = mix
def forward(self, queries, keys, values, attn_mask):
B, L, _ = queries.shape
_, S, _ = keys.shape
H = self.n_heads
queries = self.query_projection(queries).view(B, L, H, -1)
keys = self.key_projection(keys).view(B, S, H, -1)
values = self.value_projection(values).view(B, S, H, -1)
out, attn = self.inner_attention(
queries,
keys,
values,
attn_mask
)
if self.mix:
out = out.transpose(2,1).contiguous()
out = out.view(B, L, -1)
return self.out_projection(out), attn
class ConvLayer(nn.Module):
def __init__(self, c_in):
super(ConvLayer, self).__init__()
padding = 1 if torch.__version__>='1.5.0' else 2
self.downConv = nn.Conv1d(in_channels=c_in,
out_channels=c_in,
kernel_size=3,
padding=padding,
padding_mode='circular')
# 批量归一化层的作用是在训练过程中对每个批次的数据进行归一化处理
# 使其均值接近于 0,方差接近于 1,从而加速模型的训练和提高模型的稳定性
# 不会改变形状
self.norm = nn.BatchNorm1d(c_in)
self.activation = nn.ELU()
self.maxPool = nn.MaxPool1d(kernel_size=3, stride=2, padding=1)
def forward(self, x):
x = self.downConv(x.permute(0, 2, 1))
x = self.norm(x)
x = self.activation(x)
x = self.maxPool(x)
x = x.transpose(1,2)
return x
class EncoderLayer(nn.Module):
def __init__(self, attention, d_model, d_ff=None, dropout=0.1, activation="relu"):
super(EncoderLayer, self).__init__()
d_ff = d_ff or 4*d_model
self.attention = attention
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
self.activation = F.relu if activation == "relu" else F.gelu
def forward(self, x, attn_mask=None):
# x [B, L, D]
# x = x + self.dropout(self.attention(
# x, x, x,
# attn_mask = attn_mask
# ))
new_x, attn = self.attention(
x, x, x,
attn_mask = attn_mask
)
x = x + self.dropout(new_x)
y = x = self.norm1(x)
y = self.dropout(self.activation(self.conv1(y.transpose(-1,1))))
y = self.dropout(self.conv2(y).transpose(-1,1))
return self.norm2(x+y), attn
class Encoder(nn.Module):
def __init__(self, attn_layers, conv_layers=None, norm_layer=None):
super(Encoder, self).__init__()
self.attn_layers = nn.ModuleList(attn_layers)
self.conv_layers = nn.ModuleList(conv_layers) if conv_layers is not None else None
self.norm = norm_layer
def forward(self, x, attn_mask=None):
# x [B, L, D]
attns = []
if self.conv_layers is not None:
for attn_layer, conv_layer in zip(self.attn_layers, self.conv_layers):
x, attn = attn_layer(x, attn_mask=attn_mask)
x = conv_layer(x)
attns.append(attn)
x, attn = self.attn_layers[-1](x, attn_mask=attn_mask)
attns.append(attn)
else:
for attn_layer in self.attn_layers:
x, attn = attn_layer(x, attn_mask=attn_mask)
attns.append(attn)
if self.norm is not None:
x = self.norm(x)














 5110
5110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









